







先上爬取1-10页的效果(获取全网即更改页数即可)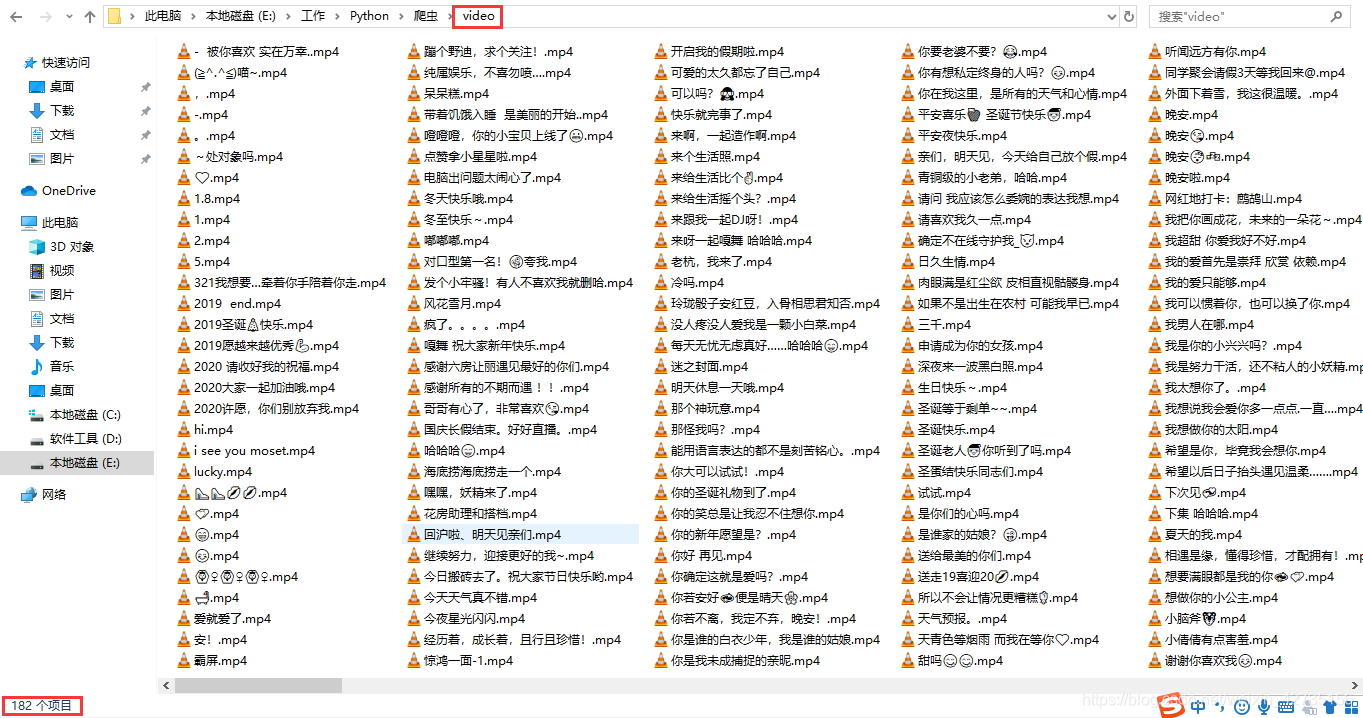
<><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><><>
思路:
(1)访问网站
(2)获取响应数据
(3)解析数据:
a:转换数据类型
b:数据解析
(4)遍历列表,find网址
(5)下载到文件夹
import requests
import json
import re
def change_title(title):
pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]")
new_title = re.sub(pattern,"_",title)
return new_title
for page in range(1,10):#爬取1~n页
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1470
1470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









