







问题描述:
需要爬取BVDV相关文献做研究,主要使用参数有title,pmid,abstract。
由于有些文章没有abstract,导致爬取失败。
错误代码:
Traceback (most recent call last):
File “E:////master/pythontest.py", line 106, in
main()
File "E:////master/pythontest.py", line 88, in main
parserPmidHtmlText(html, pmid)
File "E:///****/****master/pythontest.py”, line 49, in parserPmidHtmlText
abstractTag = abstractTag[0].find_all(‘p’)
IndexError: list index out of range
问题分析:
虽然提示数组下标越界,但是实际上你看倒数第二行错误,在find_all方法调用的时候仅搜索
标签,是不对的,我们返回原网页去对比,发现没有abstract的页面使用的是标签,所以我们可以在这里用xpath方法做一个判断,或者在首页选定规则。解决办法如下:
解决办法1:
采用xpath做判断。
(时间有限,暂时搁置)
解决办法2:
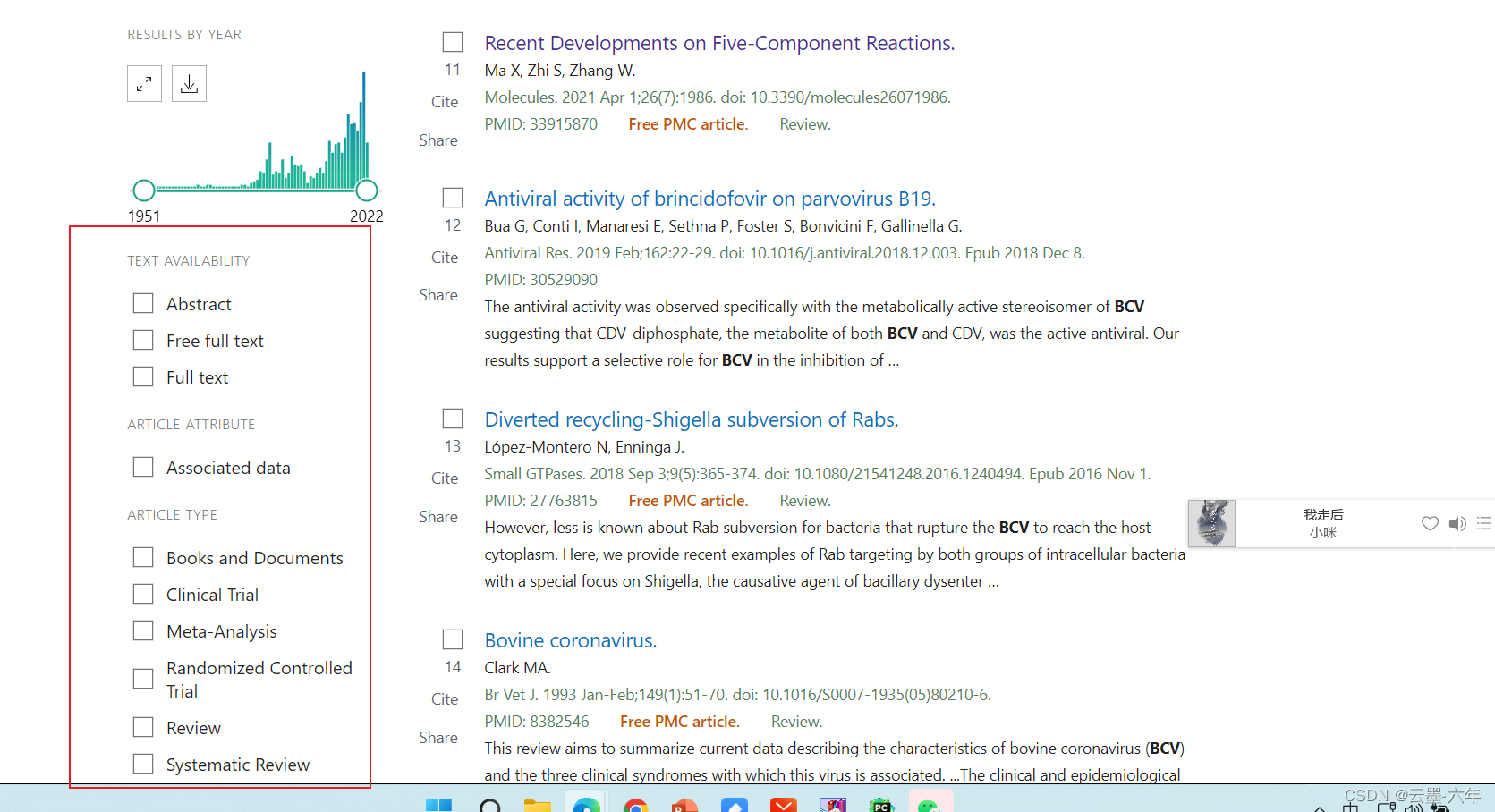
在对应选项上勾选,在爬取页面上写增加一个拼接字段。
原字段:
https://pubmed.ncbi.nlm.nih.gov/?term=BCV&filter=simsearch3.fft&page=2
初始网站+搜索字段+(锁定字段)+页码

















 1977
1977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









