









供自己参考学习,如有问题,欢迎交流指正!
Faster-RCNN代码运行记录_踩坑记录
首先实验室服务器上有安装好的anaconda以及pytorch1.0和cuda。自己首先找管理员申请一个账号,根据账号密码进入自己的账号文件夹下面。
1、远程连接服务器ssh(VScode)
- 安装remote-ssh插件
- 新建一个远程连接,随便输入一个名字回车(假如测试)


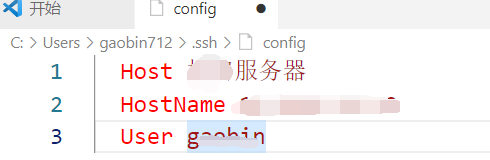
- 选择打开config文件,显示如图


- 修改Host为随便一个名字,HostName为服务器的IP地址,下面User为自己在服务器的用户名
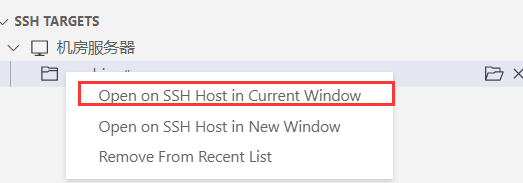
- 右键选择第一个,然后会提示输入自己的服务器账号密码,就可以连接服务器了
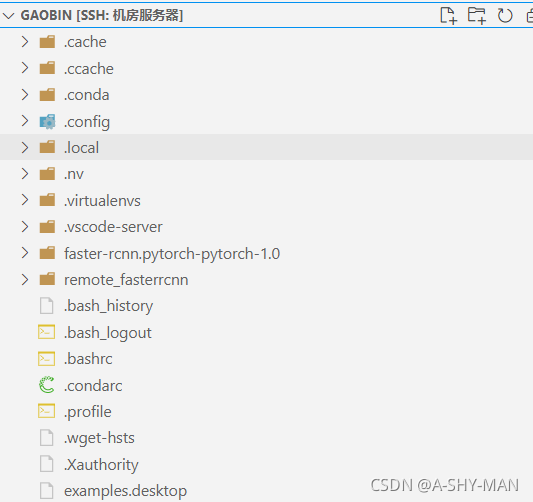
- 最终就可以在本地修改服务器上的文件,并用服务器GPU运行自己的模型,也可以在服务器存储自己的东西。
2、模型代码数据准备
注意所有文件路径和命名都要按照步骤来,因为模型代码已经规定好了数据的文件路径结构。另外数据集和预训练模型比较大,且下载需要科学上网,博主在放一下自己网盘里下载好的文件。
链接:https://pan.baidu.com/s/1icSxvO5PGRNYXBpmmP67AA
提取码:rsus
- 来源于github上比较火的一个fasterrcnn模型。
模型下载链接:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0 - 然后将自己下载的模型文件复制到自己的服务器文件夹下面,或者直接git clone。
- 进入模型文件夹新建一个data文件夹
cd faster-rcnn.pytorch-pytorch-1.0 && mkdir data
- 进入data文件夹,用下面的命令下载VOC2007标准数据集数据,或者直接在http网页下载后放到data文件夹中。
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
- 解压数据集,下面三行命令一起使用,不要单独输入,解压后文件会统一生成在data下的VOCdevkit文件夹中。
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tar
- 然后将VOCdevkit文件夹名字改为VOCdevkit2007,或者用如下命令建立软连接(注意-s后面是VOCdevkit的绝对路径)
ln -s /faster-rcnn.pytorch-pytorch-1.0/data/VOCdevkit VOCdevkit2007
-
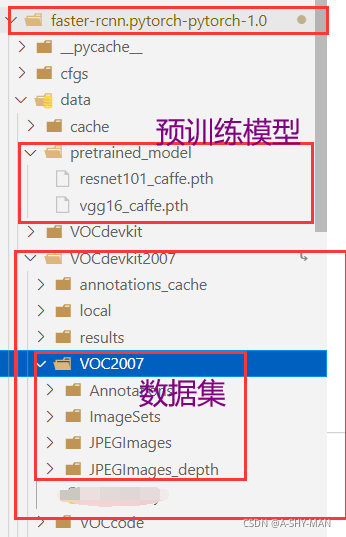
接下来在data下创建子文件夹pretrained_model,下载预训练模型VGG16,ResNet101后放到pretrained_model文件夹中.
VGG16预训练模型链接:https://www.dropbox.com/s/s3brpk0bdq60nyb/vgg16_caffe.pth?dl=0
ResNet101预训练模型链接:https://www.dropbox.com/s/iev3tkbz5wyyuz9/resnet101_caffe.pth?dl=0 -
最终的文件结构是:
3、环境准备
- 在命令行中使用conda创建一个自己的虚拟环境(gaobin_py3.6 是自己的虚拟环境名,python==3.6是自己用的python版本)
conda create -n gaobin_py3.6 python==3.6
- 然后进入自己的虚拟环境
conda activate gaobin_py3.6
效果如下图,如果前面没有base或者自己环境名,建议首先conda init初始化一下。

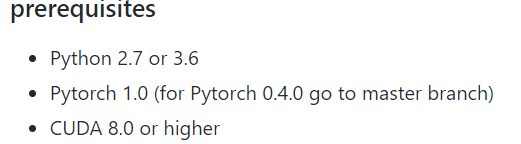
- 然后安装自己需要的的环境,首先我们看github作者建议的准备环境,在创建虚拟环境时我们已经设置了python3.6,然后
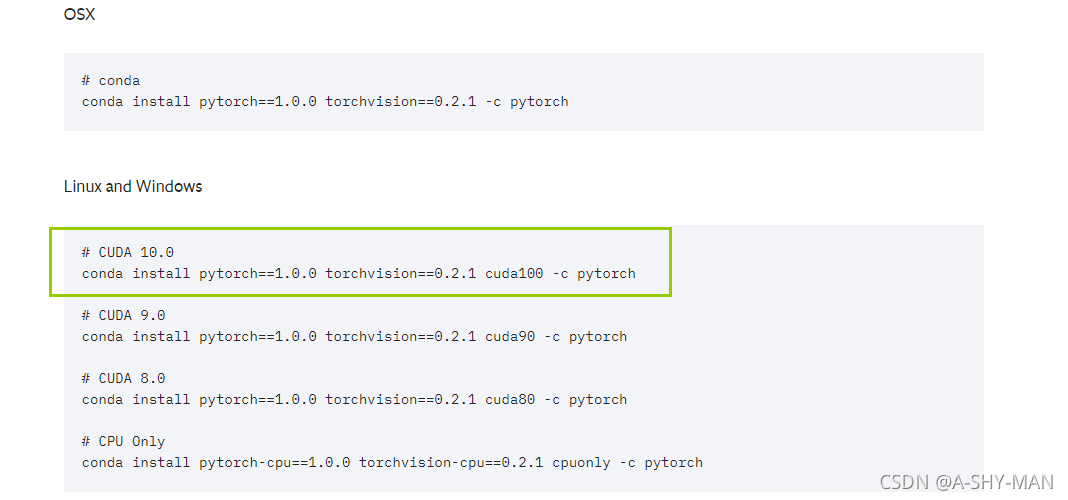
conda list看看自己的虚拟环境里有没有pytorch,如果没有,在这个pytorch网站(https://pytorch.org/get-started/previous-versions/)寻找对应于版本的安装命令,因为cuda是向下兼容的,我们的服务器装的是cuda11.4,用nvidia-smi可以查看安装的cuda信息,所以我用的下图中这个命令,实测可以用,安装结束之后,记得conda list再检查一下有没有安装好pytorch。
- 然后回到faster-rcnn.pytorch-1.0文件夹下面安装python依赖的包
pip install -r requirements.txt
- 然后进入lib文件夹编译cuda的环境
cd lib
python setup.py build develop
在这一步或者训练的的时候运行可能会遇到两个问题
(1)cannot import name ‘_mask’
这时候是pycocotools这个包出问题了,我重新安装了一下pip install pycocotools就好了,但网上还有很多下载cocoapi解决问题的,后续遇到可以试试。
(2)can’t import ‘imread’
这是scipy的版本问题,具体啥版本我忘了,用pip install scipy==1.2.1重新安装一个1.2.1版本就解决了。
4、训练、测试和demo运行(这里用的res101预训练模型)
- 运行trainval_net.py文件,下面第一个是运行命令说明,第二是我自己用的命令,要注意自己的GPU编号和预训练的模型,其余参数github上作者有建议参数,我们只跑的是VOC2007数据集。
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py \
--dataset pascal_voc --net vgg16 \
--bs $BATCH_SIZE --nw $WORKER_NUMBER \
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP \
--cuda
CUDA_VISIBLE_DEVICES=1 python trainval_net.py
--dataset pascal_voc --net res101
--bs 1 --nw 4 --cuda --epochs 5
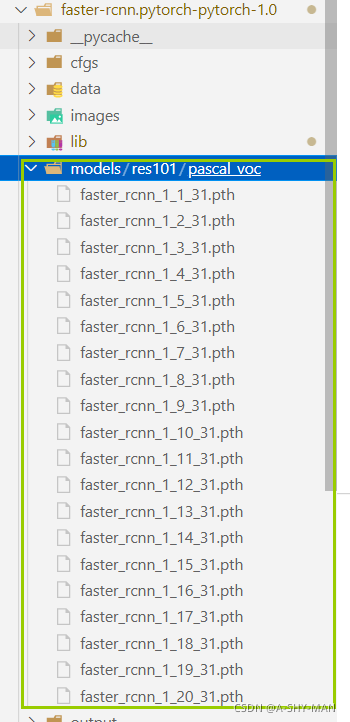
运行结束后,如果没有自己制定模型文件夹,faster-rcnn.pytorch-pytorch-1.0文件夹下就会出现一个models文件夹,文件夹结构如下:(文件里名字后面包含的31应该是2504,这个和数据集大小有关,这个31是我自己后面自己的数据集训练出来的)
- 测试VGG16,ResNet101预训练模型训练出来的模型在在pascal_voc测试集上的表现,使用以下命令,第一个是运行命令说明,第二是我自己用的命令(具体参数的意思之后再学习)。
python test_net.py --dataset pascal_voc --net vgg16 \
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT \
--cuda
python test_net.py --dataset pascal_voc --net res101
--checksession 1 --checkepoch 20
--checkpoint 2504
--cuda
- 运行demo.py,image中是运行要跑的图片,如果想跑自己的图片,替换就行,如果训练时没有改变路径,那么按照如下命令直接运行。第一个是运行命令说明,第二是我自己用的命令,
python demo.py --net res101 \
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT \
--cuda --load_dir + 模型存放文件夹
python demo.py --net res101
--checksession 1 --checkepoch 20
--checkpoint 2054
--cuda --load_dir models
如果训练时改变了模型存储路径,要修改–load_dir 的参数,比较麻烦不好修改,或者保持和models下一样的文件结构models/res101/pascal_voc
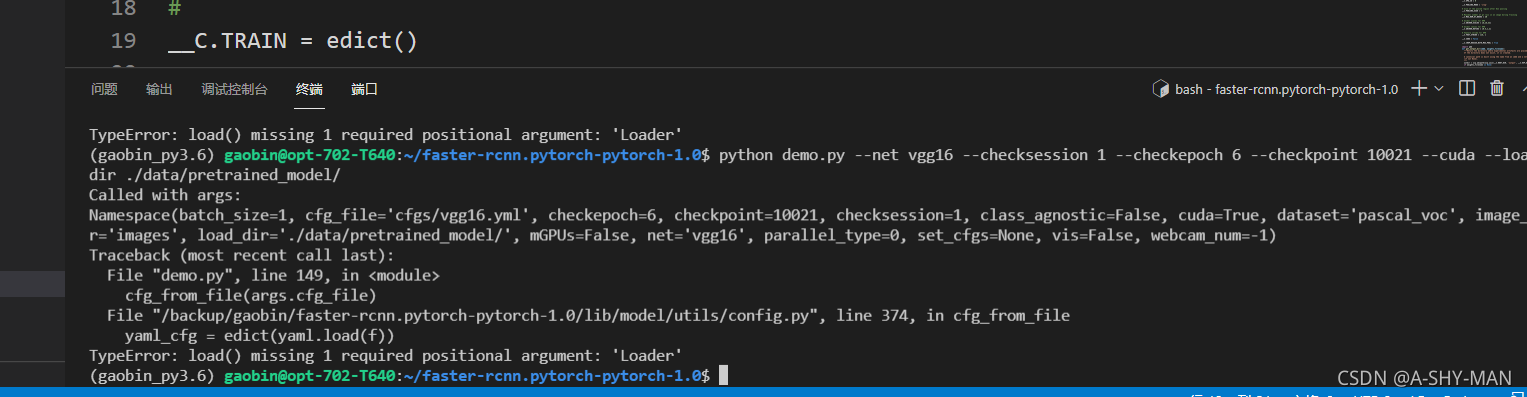
注意这里可能出现如下错误:
显示缺少参数,这个问题是yaml版本问题,可以conda install pyyaml==5.4.1重新安装一个低版本的yaml就行了。
- 效果:(其中某一张图,检测结果的图片比原图名字多加了"_det",注意区分)

5、训练自己的数据
-
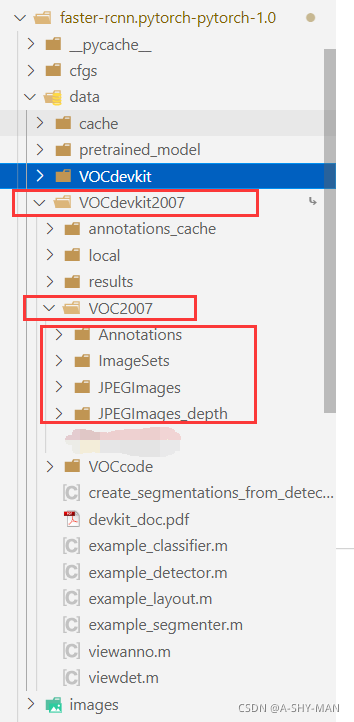
自己的数据结构保持和VOC2007一致,为了方便,直接删掉标准数据集的数据,复制进去自己的在如下第三个红框的位置。这里可以准别好JPEGImages文件夹的照片数据和Annotations文件夹的标签数据,然后自动生成训练集和测试集的文件,参考这篇博客:Faster-RCNN.pytorch的搭建、使用过程详解(适配PyTorch 1.0以上版本)。
-
修改/lib/datasets/pascal_voc.py(大约在代码48行左右)里的检测类别:
原始的检测类别是:
self._classes = ('__background__', # always index 0
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor','plane')
改为自己的,我这里只有一类:
self._classes = ('__background__', # always index 0
'thyroid')
- 按照上述同样的方法修改demo.py((大约在代码170行左右))中的类别。
- 训练、测试、运行自己的数据跑的结果
CUDA_VISIBLE_DEVICES=0 python trainval_net.py
--dataset pascal_voc --net res101
--bs 4 --nw 0 --lr 0.001
--lr_decay_step 5 --cuda
python test_net.py --dataset pascal_voc
--net res101 --checksession 1 --checkepoch 20 --checkpoint 31
--cuda
python demo.py --net res101 --checksession 1 --checkepoch 20 --checkpoint 31
--cuda --load_dir models

















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









