









 博客对比了C++编程与CUDA编程,还对CUDA调用多线程的时间进行对比,包括调用1个线程、多个thread和多个block的情况。同时介绍了Nvidia GPU硬件结构和CUDA架构,通过编译运行代码展示不同调用方式下的运算耗时。
博客对比了C++编程与CUDA编程,还对CUDA调用多线程的时间进行对比,包括调用1个线程、多个thread和多个block的情况。同时介绍了Nvidia GPU硬件结构和CUDA架构,通过编译运行代码展示不同调用方式下的运算耗时。
参考链接: An Even Easier Introduction to CUDA
完整代码: https://github.com/nnzzll/cuda
C++编程与CUDA编程的对比
-
CPU计算
编译add.cpp,并运行g++ add.cpp -o add ./add -
调用GPU计算
编译add.cu,并运行nvcc add.cu -o add_cuda ./add_cuda
CUDA调用多线程的时间对比
调用1个线程
nvprof为cuda的分析工具,需要将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\extras\CUPTI\lib64目录下的cupti64_XXXX.X.X.dll添加至环境变量
C:\Users\Administrator\Desktop\cuda\1>nvprof ./add_cuda
==8312== NVPROF is profiling process 8312, command: ./add_cuda
Max error:0
==8312== Profiling application: ./add_cuda
==8312== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 100.00% 127.57ms 1 127.57ms 127.57ms 127.57ms add(int, float*, float*)
API calls: 59.99% 258.17ms 2 129.08ms 16.353ms 241.82ms cudaMallocManaged
29.66% 127.65ms 1 127.65ms 127.65ms 127.65ms cudaDeviceSynchronize
7.84% 33.741ms 1 33.741ms 33.741ms 33.741ms cuDevicePrimaryCtxRelease
1.98% 8.5279ms 1 8.5279ms 8.5279ms 8.5279ms cudaLaunchKernel
0.34% 1.4683ms 2 734.15us 540.80us 927.50us cudaFree
0.17% 719.20us 1 719.20us 719.20us 719.20us cuModuleUnload
0.01% 26.700us 1 26.700us 26.700us 26.700us cuDeviceTotalMem
0.00% 19.400us 101 192ns 100ns 3.1000us cuDeviceGetAttribute
0.00% 13.200us 1 13.200us 13.200us 13.200us cuDeviceGetPCIBusId
0.00% 1.8000us 2 900ns 200ns 1.6000us cuDeviceGet
0.00% 1.4000us 3 466ns 300ns 700ns cuDeviceGetCount
0.00% 800ns 1 800ns 800ns 800ns cuDeviceGetName
0.00% 300ns 1 300ns 300ns 300ns cuDeviceGetLuid
0.00% 200ns 1 200ns 200ns 200ns cuDeviceGetUuid
==8312== Unified Memory profiling result:
Device "GeForce RTX 2080 Ti (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
258 31.751KB 4.0000KB 32.000KB 8.000000MB 6.034900ms Host To Device
384 32.000KB 32.000KB 32.000KB 12.00000MB 91.92530ms Device To Host
GPU activities即为GPU的运算时间,可以看到GeForce RTX 2080 Ti调用一个线程时所花时间为127.57ms
API calls为在CPU上调用cuda的API所花的时间,可以看到一半以上的时间都花在了在开辟内存上
调用多个thread
-
修改调用核函数时的参数
<<<>>中的两个参数分别为numblock,blocksize,即有多少个block,一个block有多少个threadadd<<<1,256>>>(N, x, y); -
修改核函数的循环方式
__global__ void add(int n, float *x, float *y) { int index = threadIdx.x; int stride = blockDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }
编译并运行
nvcc add_thread.cu -o add_cuda
nvprof ./add_cuda
GPU运算耗时1.4742ms,比单线程快了86倍!
调用多个block
在调用多个block之前先了解一下GPU和CUDA的架构
Nvidia GPU硬件结构
- 每个GPU有多个并行处理器,称作Streaming Multiprocessors(SMs),
SM用来管理调度Block,同一个SM内的Block之间是内存共享的 - 每个SM里有很多Stream Processor(SP,也叫CUDA Core),用来管理调度
SIMD Thread(CUDA中也叫Warp,线程束) - 每个
SIMD Thread中包含相同个数的Thread.CUDA中有32个,即一个线程束Warp有32个Thread.
CUDA
- 一个SM包含了多个
Grid,并且可以多个SM并行执行 - 一个
Grid中有 2 32 2^{32} 232个Block - 一个
Block中有 2 10 2^{10} 210个Thread
编译并运行cuda_proc.cu,可以查看相关属性
GPU num:1
Max threads/block:1024
Max threads/SM:1024
Max block/SM:16
Max Grid size:2147483647,65535,65535
现在我们有N次计算,我们打算直接调用N个线程,那就需要计算block的数量
int blockSize = 256;
int numBlocks = (N+blocksize-1)/blockSize;
add<<<numBlocks,blockSize>>>(N,x,y)
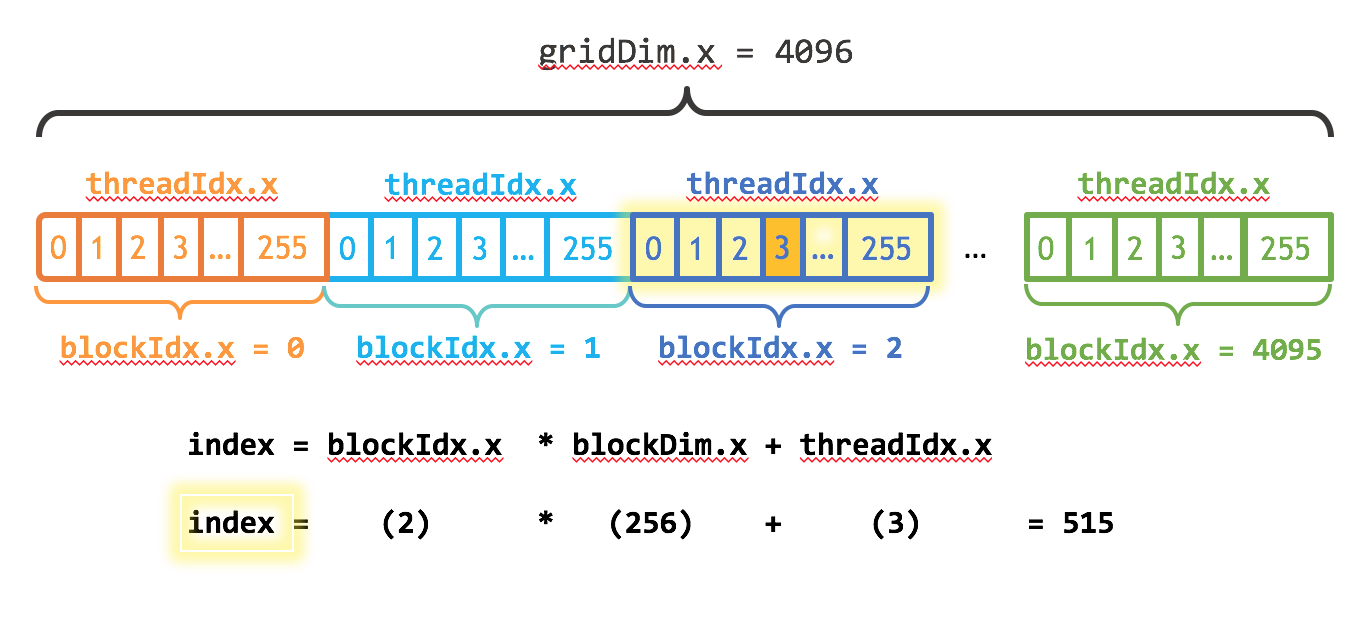
同样的,在核函数中我们需要修改循环的起始索引与步长:
以上图为例,blockIdx是block在一个grid中的索引,blockDim即为一个block所包含的thread数量,threadIdx则为thread在当前block中的索引
- 因此在核函数中,
thread的索引index为blockIdx.x*blockDim.x+threadIdx.x - 步长的设置采用grid-stride-loop,即步长为一个
grid中所有的threadint stride = blockDim.x * gridDim.x;
编译并运行add_block.cu
GPU activities: 100.00% 23.776us 1 23.776us 23.776us 23.776us add(int, float*, float*)
这次的耗时仅为23.776us

















 5656
5656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









