







 本文深入探讨了Transformer模型,一种完全依赖注意力机制的序列到序列模型,它解决了传统RNN模型的并行化难题,大大提高了训练效率。Transformer由六个相同的encoder和decoder层组成,通过多头注意力机制增强模型性能。
本文深入探讨了Transformer模型,一种完全依赖注意力机制的序列到序列模型,它解决了传统RNN模型的并行化难题,大大提高了训练效率。Transformer由六个相同的encoder和decoder层组成,通过多头注意力机制增强模型性能。
文献地址:
https://arxiv.org/pdf/1706.03762.pdf
Attention Is All You Need
摘要:
不同与传统的机器翻译模型使用复杂的循环神经网络和卷积神经网络去构成翻译器的encoder 和decoder,attention机制大大提升了模型训练时的并行化程度,并减少了训练和预测的时间.
简介:
存在的问题:
传统的序列模型RNN,GRU,LSTM都需要等待得到上一个时间的ht-1计算结果才能计算当前的ht,这大大缩小了计算过程并行化处理的可能性.
解决方案:
transformers . 完全靠注意力机制去从全局上表现输入和输出之间的联系.
背景
其他序列并行化模型:
Extended Neural GPU,ByteNet,ConvS2S.这些都是卷积模型,并且在计算序列中距离较远的两个部分时,其计算步骤会增加.
在transformer中的,序列的不同位置的计算量则是被降低到一个恒定的值(虽然这可能会降低分辨率或者说会有信息损失,但是后面的多头机制有助于解决这个问题(增加信息之类的?))
模型
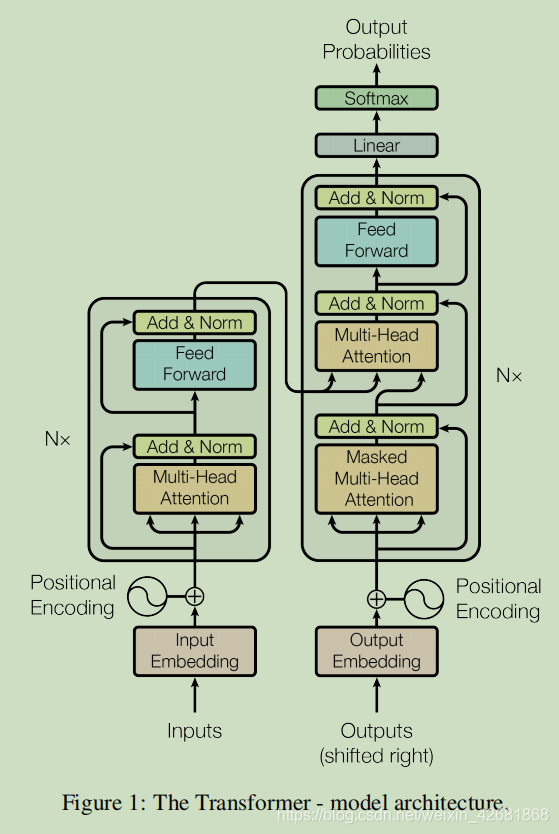
transformer由encoder 和decoder 构成.其中两部分都是由完全相同的6个合成层的pipline构成的,encode的每个合成层有两个子层,decode的每个合成层有3个子层.如上图所示.
Add: 残差
Norm: layer normalization
Feed-Forward:两个全连接层(中间用一个RELU链接)
transformer可以被认为是一个映射表:(提问,键,值)>> 输出向量.
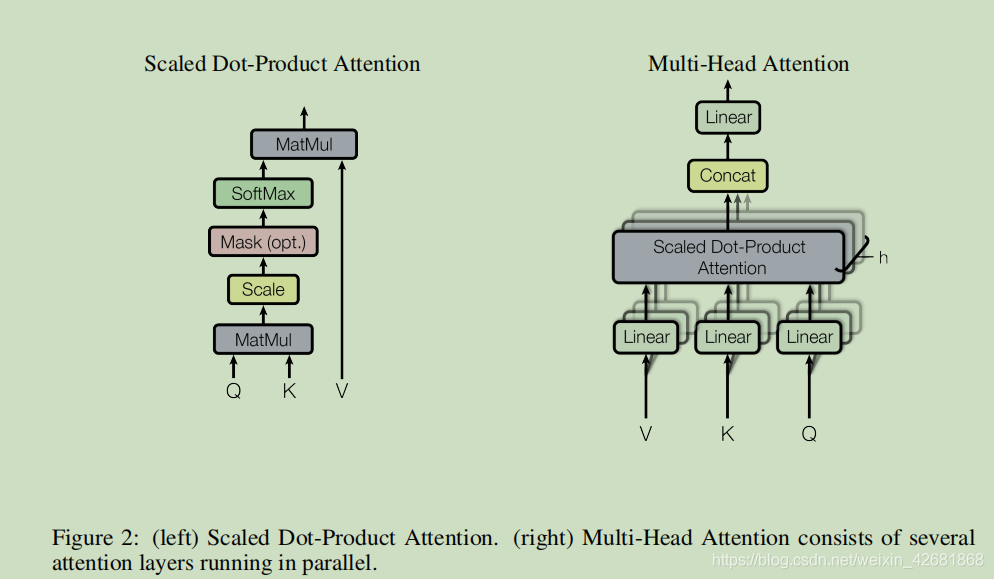
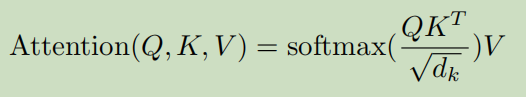
1:每个特征的Q去点乘所有特征的K
2:将上面的结果缩放(除以dk^0.5)-- scale
3:把Q和每个特征的K乘出来的结果,m个数输入到softmax中,缩放到0-1
4:softmax的结果乘每个特征的V,然后加起来就是该特征的输出了
在多头模型中,每头(通道)的计算和单头的attention的计算过程一样,然后在把每个头的结果concat起来.每个头在训练过程中是有可能学习到不同的部分的信息的.
绝对位置信息的维度和embbeding的维度相同,所以会在输入时把位置向量和embedding直接相加,再输入到attention中.

















 1372
1372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









