



 本文介绍了如何下载和安装git,以及如何使用git克隆scrapy-redis项目。通过实例讲解了scrapy-redis的单机爬虫dmoz项目,以及分布式爬虫mycrawler_redis项目,强调了在运行爬虫前启动redis服务器的重要性,并展示了如何通过redis推送请求链接来实现爬虫的分布式执行。
本文介绍了如何下载和安装git,以及如何使用git克隆scrapy-redis项目。通过实例讲解了scrapy-redis的单机爬虫dmoz项目,以及分布式爬虫mycrawler_redis项目,强调了在运行爬虫前启动redis服务器的重要性,并展示了如何通过redis推送请求链接来实现爬虫的分布式执行。
首先,如果没有下载git,执行后续命令时,可能会报错。
下载地址:https://git-scm.com/downloads

安装很简单,一直进行下一步即可(个别选项依照个人需求更改)
空白处鼠标右击,点击 Git Bash Here 出现窗口,输入命令:git --version 即可查看当前下载的git版本(效果如下)

接下来就来下载 scrapy-redis项目
下载地址:https://github.com/rmax/scrapy-redis

在桌面新建文件夹(名字自定义),然后打开cmd终端,cd到刚才新建的文件夹路径,输入命令:git clone + 复制项目的下载路径,回车执行完毕后,项目就下载好了,文件中显示内容大致如下:
将文件夹拖入到PyChrom中,点击example下,进入到settings 里面,确保下方代码处于解注释状态,
# 使用scrapy_redis的去重类 不使用scrapy默认的去重类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy_redis的调度器,不使用scrapy默认的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 控制爬虫是否允许暂停
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
# 使用redis数据库所要添加的管道,如果使用redis数据库 必须添加
'scrapy_redis.pipelines.RedisPipeline': 400,、
#这两句代码可写可不写,如若不写,默认为本机ip
REDIS_HOST = '127.0.0.1' # redis数据库的ip
# 端口为数字
REDIS_PORT = 6379接下来就自带的三个爬虫小程序进行实操讲解:
(1)dmoz项目(此处为单机爬虫)
由于 dmoz.com已经于去年停止使用,所以这里就改爬红袖小说的小说名字......
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class DmozSpider(CrawlSpider):
"""Follow categories and extract links."""
name = 'dmoz'
allowed_domains = ['hongxiu.com']
start_urls = ['https://www.hongxiu.com/finish']
# 规则
rules = [
# 获取网页的指定内容 然后进入到指定方法里面
Rule(LinkExtractor(
restrict_css=('.book-info')
# follow 设置是否继续执行后面的内容
# 如果有回调函数,则默认为False 否则为True
), callback='parse_directory', follow=True),
]
def parse_directory(self, response):
# for div in response.css('.title-and-desc'):
# yield {
# 'name': div.css('.site-title::text').extract_first(),
# 'description': div.css('.site-descr::text').extract_first().strip(),
# 'link': div.css('a::attr(href)').extract_first(),
# }
print('----------------')
print(response.url)在执行命令之前,先在终端打开redis数据库(命令:redis-server redis.windows.conf),之后再打开一个cmd终端窗口,cd到当前需执行的文件夹路径下,然后输入命令:scrapy crawl dmoz 即可。
(2.)mycrawler_redis项目(分布式爬虫)
注意:网页链接依然引用红袖链接
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from scrapy_redis.spiders import RedisCrawlSpider
class MyCrawler(RedisCrawlSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'mycrawler_redis'
# allowde_domains = ['biadu.com']
redis_key = 'mycrawler:start_urls' # 类名 : start_urls 推荐写法;标准写法
# start_urls = ['']
rules = (
# follow all links
Rule(LinkExtractor(), callback='parse_page', follow=True),
# Rule(LinkExtractor(), callback='detali')
)
# 初始化方法
# def __init__(self, *args, **kwargs):
# # 动态的 定义 allowde允许 domains域名 list列表
# # Dynamically define the allowed domains list.
# # 此处动态定义域名列表
# domain = kwargs.pop('domain', '')
# # self.allowed_domains = filter(None, domain.split(','))
# # super 后面写自己的类名
# super(MyCrawler, self).__init__(*args, **kwargs)
def parse_page(self, response):
# return {
# 'name': response.css('title::text').extract_first(),
# 'url': response.url,
# }
print('============================')
print(response.url)打开cmd终端,输入命令:scrapy crawl mycrawler_redis ,运行后,会到下图位置停止:
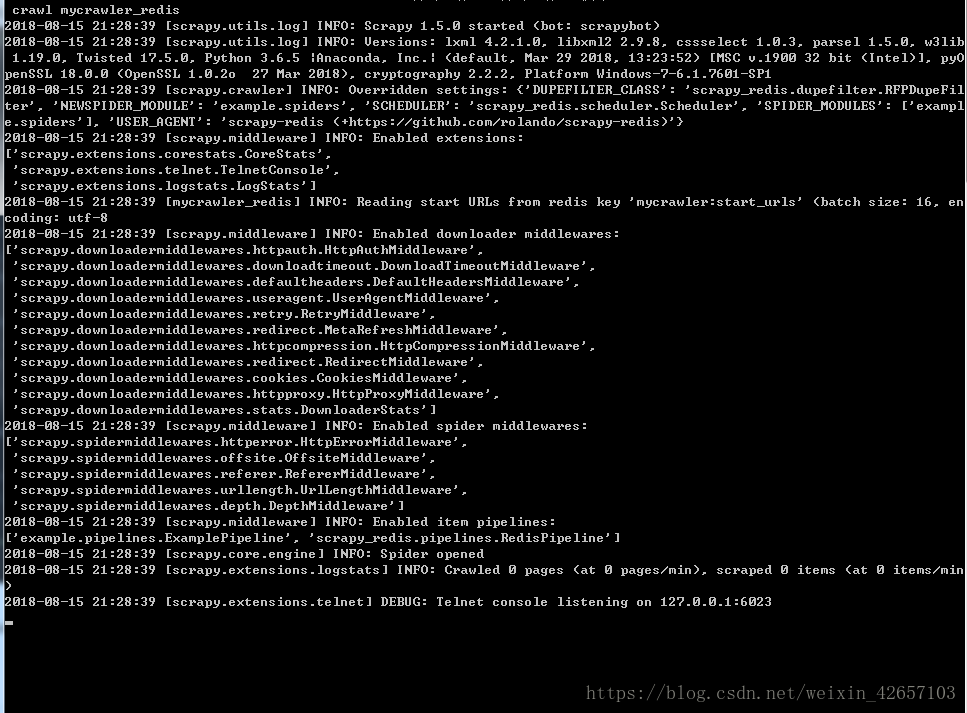
这里先不要关闭或者停止运行,另外打开一个cmd终端,输入命令:redis-cli,效果如下:
接着再次输入命令:lpush key值(redis-key值) value值(爬取的网页链接) 回车,上一个终端命令即可继续执行(因为在等待请求网页链接)
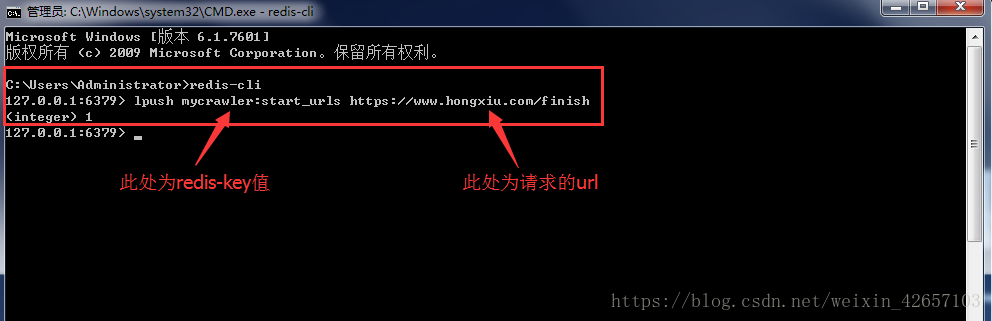
打开redis数据库数据库查看:
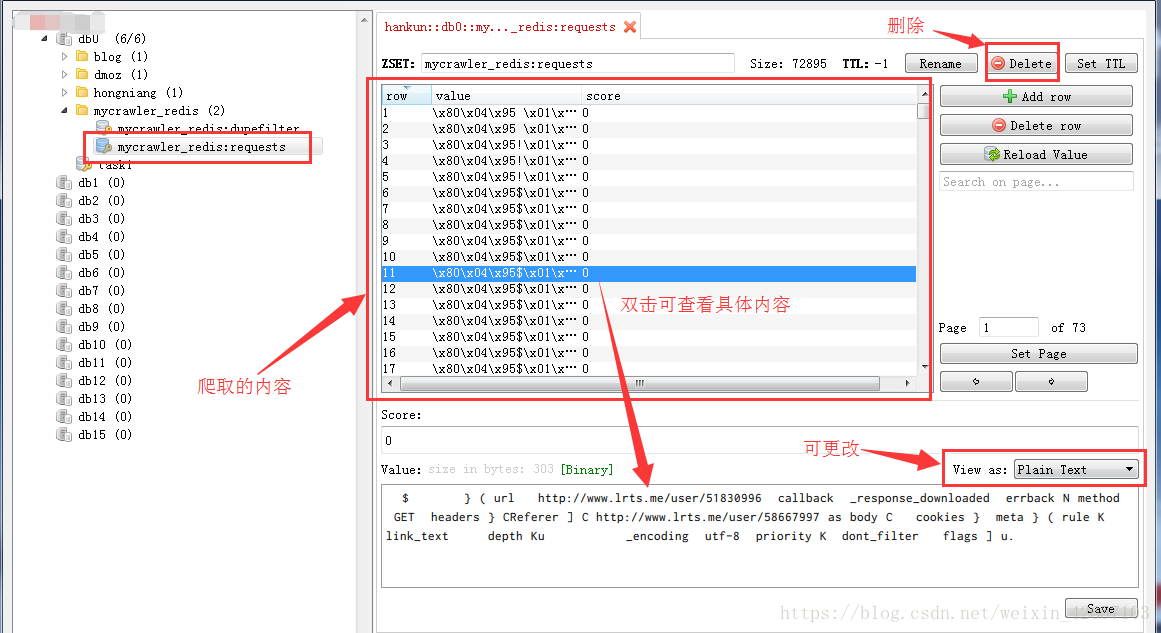
第三个小项目跟第二个项目类似,这里就跳过了。

















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









