




 本文深入解析Scrapy-Redis分布式爬虫框架的实现原理与部署流程,探讨Redis在爬虫中的关键作用,包括指纹集合与调度队列的运用,以及如何通过邮件监控确保爬虫稳定运行。
本文深入解析Scrapy-Redis分布式爬虫框架的实现原理与部署流程,探讨Redis在爬虫中的关键作用,包括指纹集合与调度队列的运用,以及如何通过邮件监控确保爬虫稳定运行。
一、scrapy-redis分布式
1、redis的安装
(1)、将压缩包解压到指定目录,就安装好了
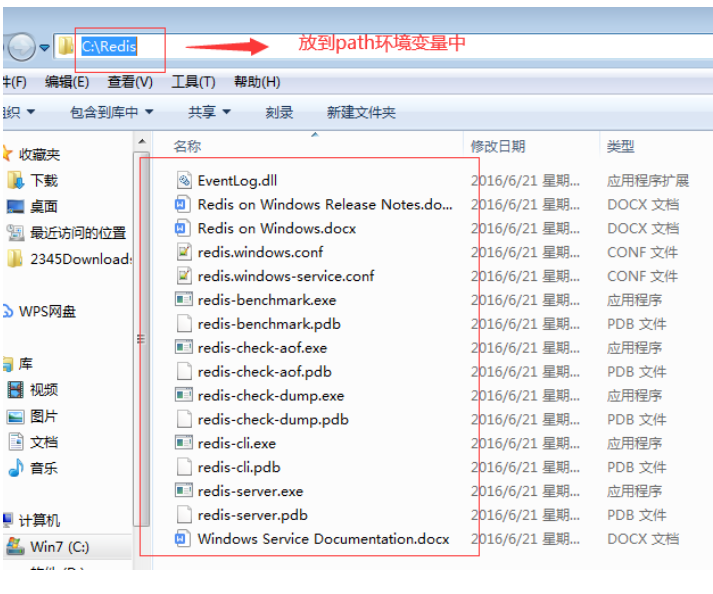
(2)、配置环境变量:
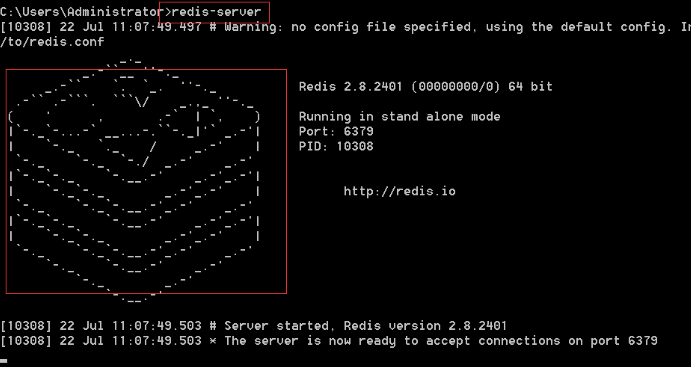
3、测试是否安装成功
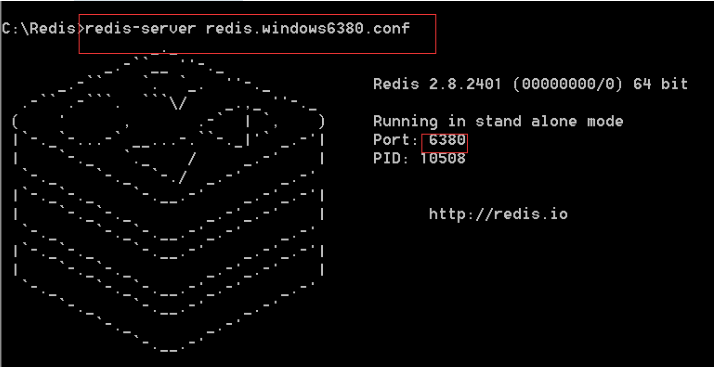
2、客户端和服务命令
一般情况,redis的使用的时候才启动,–其他时候都是关闭
原因:redis启动之后就会将他的所有数据全部加载到内存,对内存的消耗极大
服务端命令:
redis-server 配置文件的路径
redis的配置文件如下图:

配置文件是redis非常重要的文件,这个文件包含对一个redis服务器所有设置,我们只需要在这个配置文件中设置好一些信息,启动的时候只需要指定这个文件,那么这个redis服务器就会按照我们设置进行启动
一个redis服务器就是一个配置文件

redis的默认端口是6379
可以指定配置文件来进行启动数据库
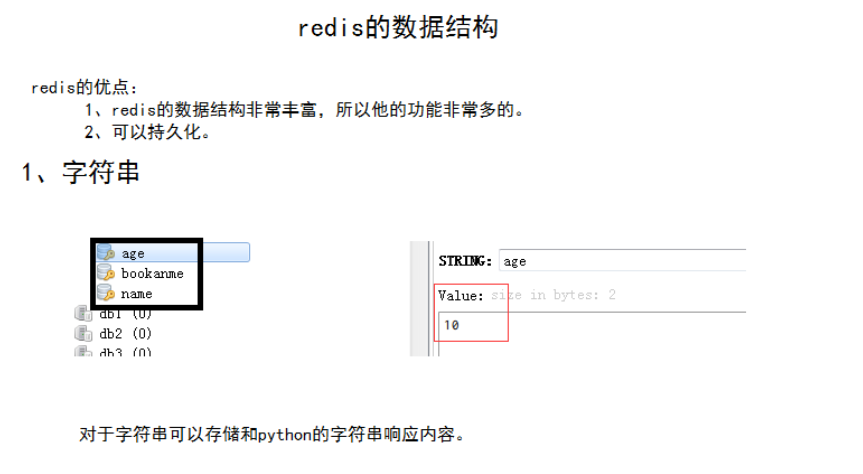
二、redis数据
文档:01-Redis数据结构.note
链接:http://note.youdao.com/noteshare?id=b25d0db9b99d173ad016f8d84184bd99&sub=20A0DDC40FF0446D876E8FDD3D221D36
持久化:将内存中的数据保存到硬盘上这个过程。
存储文件
数据----数据库文件


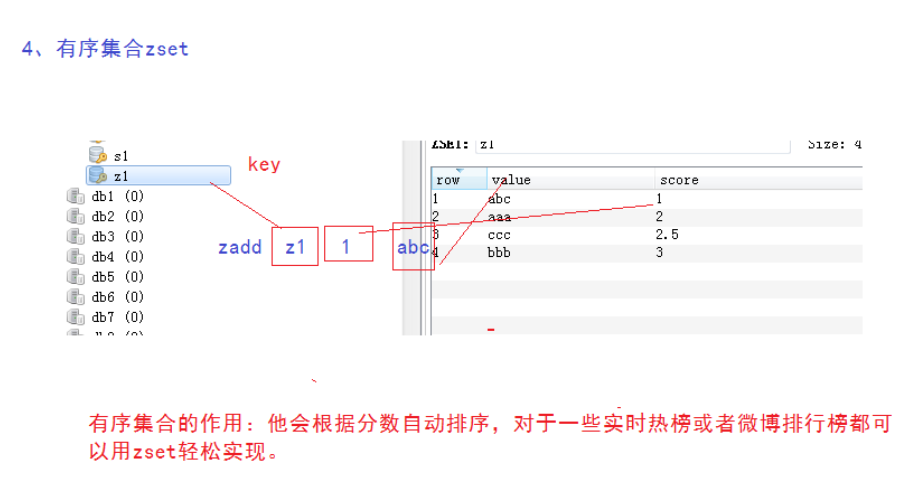
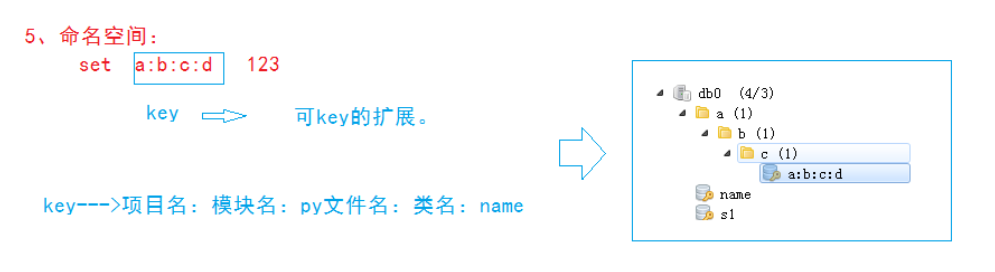
三、scrapy-redis分布式原理
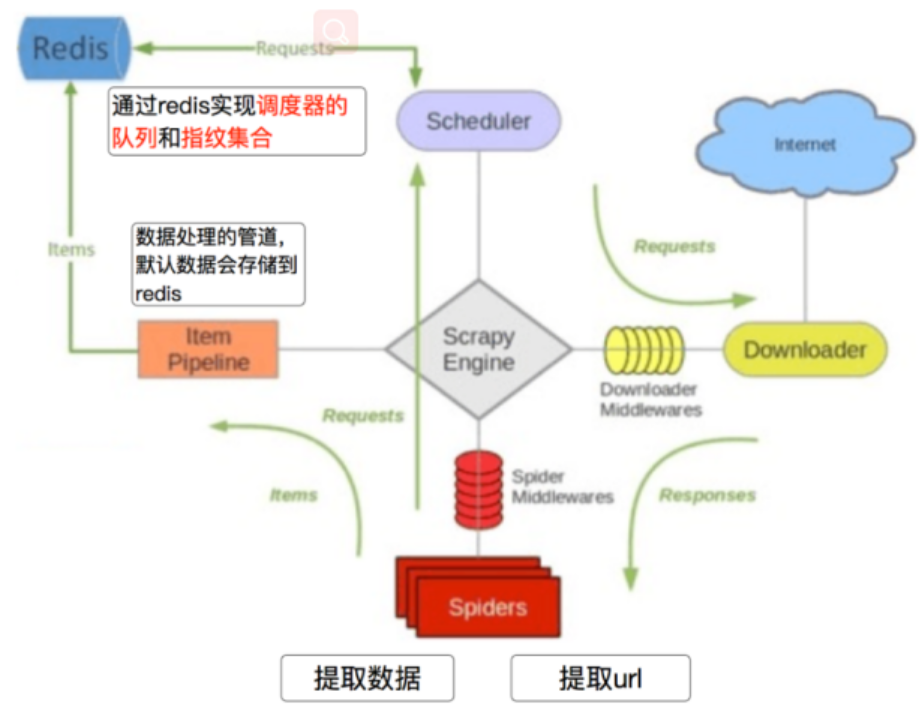
scrapy-redis分布式框架就是在scrapy基础上增加了redis组件,那么这个redis组件的功能就是scrapy和scrapy-redis主要区别
scrapy和scrapy-redis的主要区别就在于redis的两个功能:指纹集合和redis的调度队列
指纹集合的原理下图:
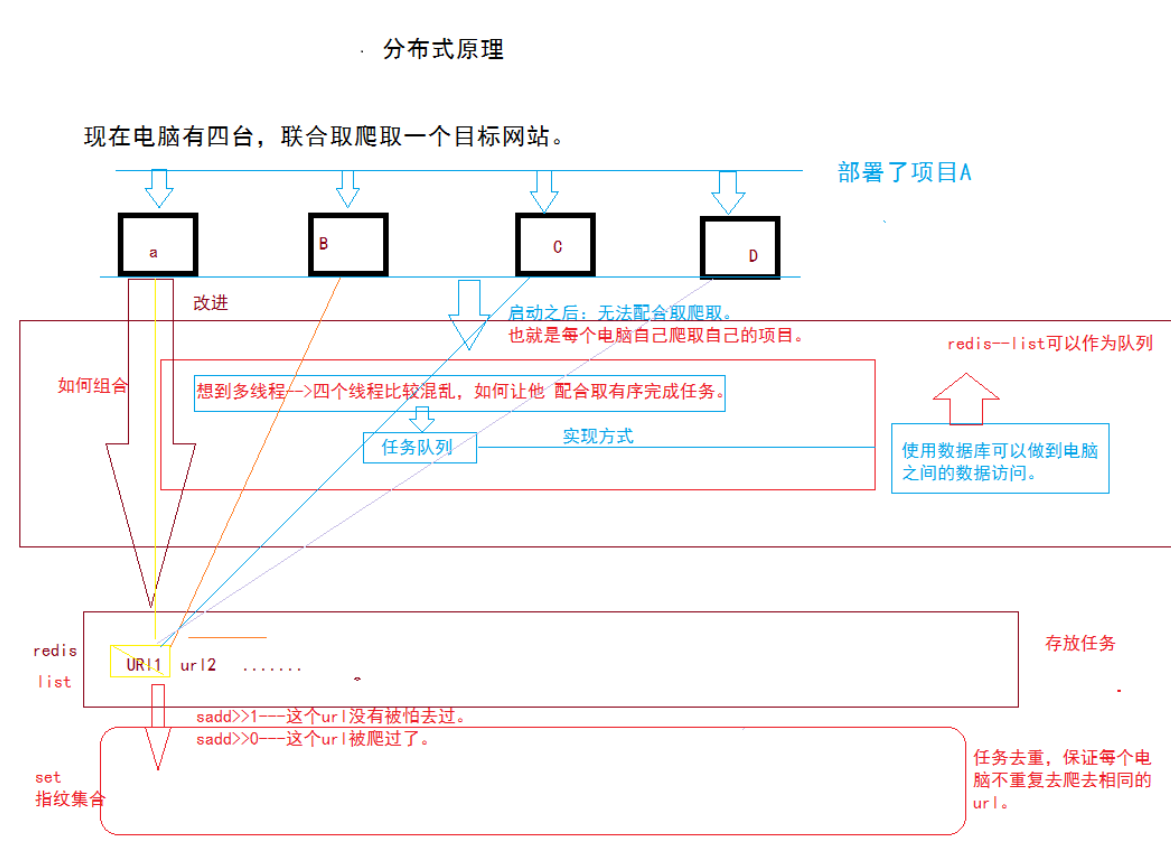
2、sscrapy框架之所以不能进行分布式,原因是由scheduler决定的
调度队列的原理如下:
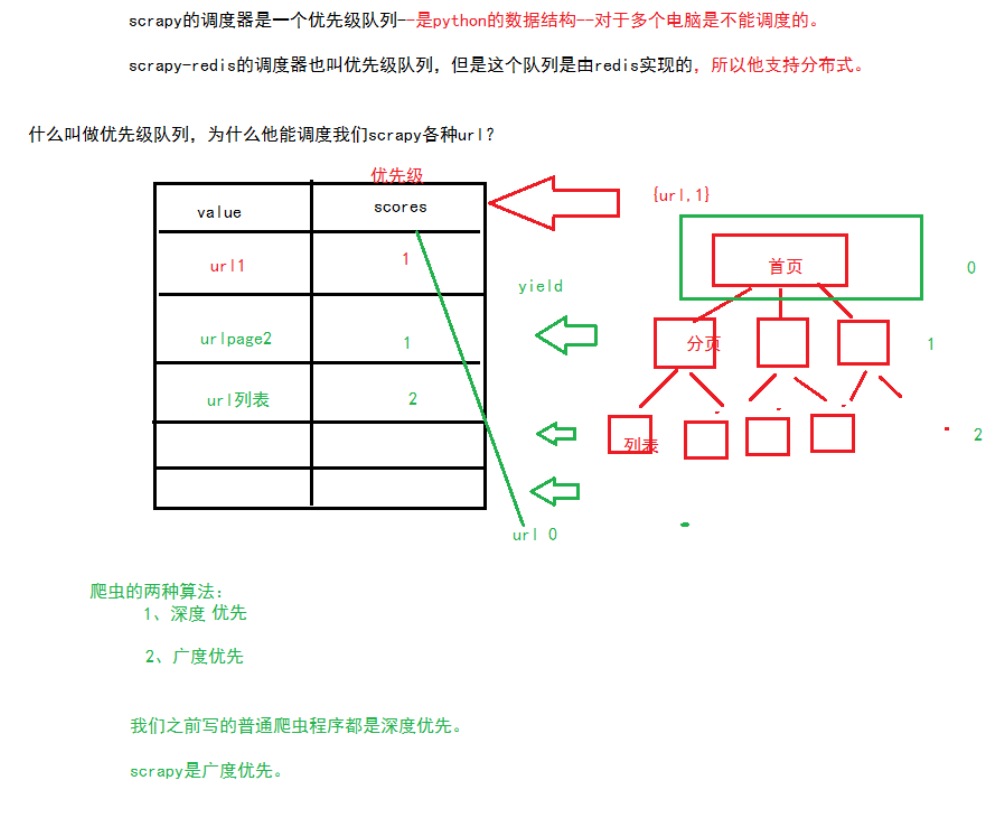
scrapy-redis重点:
1、scrapy-redis框架
2、redis的功能(去重指纹集合,调度器区别和scrapy调度器)
3、部署
四、scrapy部署流程:
创建scrapy-redis分布式项目必须先有一个完整的scrapy项目
1、导入包,更改spider继承
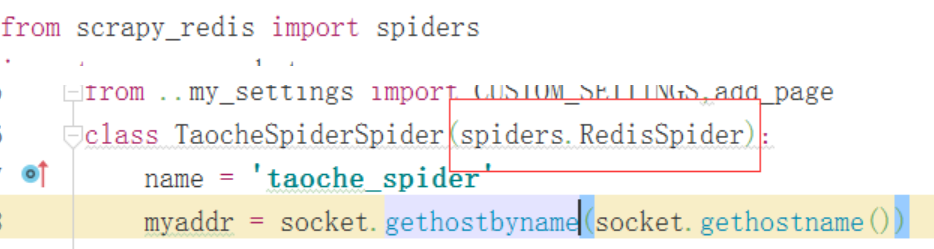
2、将start_urls注释调,因为scrapy-redis是从redis中读取初始任务的,不需要start_urls

3、主机写入初始化redis的初始url列表的代码
主机:就是使用的哪台电脑上的redis和mongo,哪台电脑就是主机
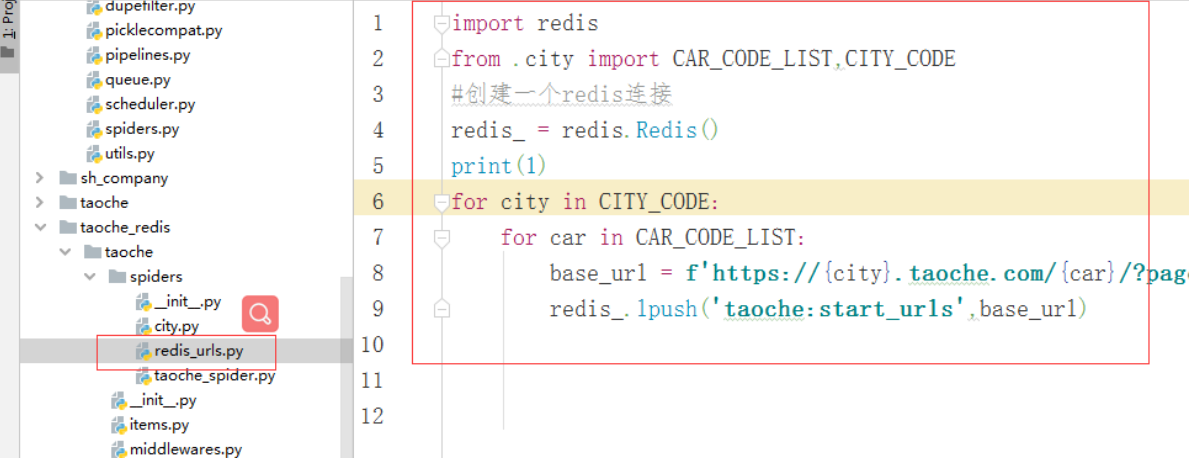
这里的redis-key就表示将来项目启动后就会从redis中的这个key所对应的列表中获取url
4、在spider中设置读取初始任务的代码,方法如下:
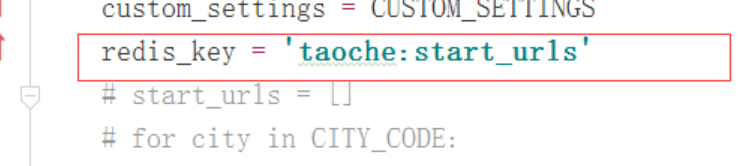
这里的redis-key就表示将来项目启动后就会从redis中的这个key所对应的列表中获取url
5、添加如下配置:
========================================================
这三条主机和从机都要添加:配置调度器和去重指纹集合。
#配置scrapy-redis调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#配置url去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#配置优先级队列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
========================================================
##端口号
REDIS_PORT = 6379
MONGO_DATABASE = 'caixi'
========================================================
#主机和从机不一样的:
#主机名
REDIS_HOST = 'localhost'
MONGO_URI = 'localhost'
【主机才负责初始化redis的任务列表】
从机里面: 主机ip要确定
REDIS_HOST = '目标主机的ip'
MONGO_URI = '目标主机的ip'
========================================================
五、邮件监控
背景:将爬虫部署工具,基本上很少再去关注了,–反爬因素。慢慢爬取
问题:网页内容改变了,或者请求头中某些变了,—造成爬虫不能用,数据库的数据变少
需要一个监控爬虫的工具,如果网页发生变更,或者爬虫程序出现数据缺失等等问题时候,能够告诉我们是哪个爬虫出了问题,因为这些原因出了爬虫监控功能
发邮件===如何让程序发邮件
try:
except:
调用发邮件功能
def send_email(content,subject=None,receive='2320047077@qq.com',
msg_from ='742783358@qq.com',password=''):
'''
发送邮件
:param content: 发送邮件内容
:param subject: 邮件主题
:param receive: 收件人,多个收件人格式:'收件人1;收件2;...'
:param msg_from: 发件人
:param password: 授权码
:return:
'''
# 定义发件人
msg_from = msg_from
# 定义收件人
msg_to = receive
# 授权码
password = 'podesdnezjfdbcba'
# 主题
subject = subject
msg = MIMEText(content, 'plain', 'utf-8')
msg['From'] = msg_from
msg['To'] = msg_to
msg['Subject'] = subject
try:
# 创建邮件对象
smtpobj = smtplib.SMTP()
# 连接服务器
# 指定qq邮箱的smt服务器
smtpobj.connect('smtp.qq.com')
# 登陆操作:指定邮箱和授权码
smtpobj.login(msg_from, password)
# 发邮件:
# sendmail:参数是:发件人,多个收件人列表,msg对象的字符串格式
smtpobj.sendmail(msg_from, msg['To'].split(';'), msg.as_string())
print('发送成功!')
except Exception as e:
print('发送失败!', e)
元类:
1、元类:创建类的类。
什么是类:创建对象的类就是类
obj = A()
对象=类()
#类= 元类()
python提供给我们的唯一元类就是type,tpye方发作为元类的时候有三个属性:
type(
name,创建出来的类的名字
bases,类的继承的元组
attrs,类的属性字典
)

















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









