






 本文深入探讨了MapReduce中自定义数据类型的序列化和反序列化过程,以及分区(Partitioner)的作用和使用方法。通过具体案例,如统计个人总流量和学生月考总分,详细讲解了如何实现自定义类的序列化、map和reduce阶段的处理,以及自定义分区逻辑。
本文深入探讨了MapReduce中自定义数据类型的序列化和反序列化过程,以及分区(Partitioner)的作用和使用方法。通过具体案例,如统计个人总流量和学生月考总分,详细讲解了如何实现自定义类的序列化、map和reduce阶段的处理,以及自定义分区逻辑。
回顾:
上一篇我们讲述了mapreduce处理hdfs中数据的过程,就是分为map阶段和reduce阶段,map阶段就是把hdfs中的数据给“包装”好,这个包装工作会有很多的map线程去做,并且以key——value的形式,通过context传递给reduce阶段。相同key的值底层会把他做成一个带迭代器的数组。reduce阶段也称规约阶段,目的就是把上面分散的数据给集合起来,所以reduce可以拿到这个key,和value的数组迭代器,就可以对数据进行整合,最后传递出去。
问题的引出:
我们之前在map阶段对数据的包装都是基本数据,那么如果我们的value是一个对象,是不是还是像之前的模式一样操作就可以?答案肯定是否定的,如果想要使用自定义数据类型来封装数据,就需要使用到序列化和反序列化。这是因为在MapReduce中要求被传输的数据能够被序列化。
MapReduce中的序列化和反序列化:
案例:统计一个人 花费的总流量/出现过的地方
hdfs中的数据如下所示。
手机号/地区/名字/流量使用数
思路: 我们可以先用一个类来封装这下面的数据,然后在map阶段把封装好的数据作为value,用户名作为key传递给reduce阶段。

1.首先我们需要声明一个类来封装这些数据。
需要注意的是,这里我们就做了一个序列化和反序列化的操作,就按照代码里的来写就可以,很简单。
mapreduce序列化底层使用的是avro,但是它还是做了一层封装,所以只需要继承writable并且override一下就可以。
public class Flow implements Writable {
private String phone = "";
private String addr = "";
private String name = "";
private int flow;
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getAddr() {
return addr;
}
public void setAddr(String addr) {
this.addr = addr;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getFlow() {
return flow;
}
public void setFlow(int flow) {
this.flow = flow;
}
// 序列化
// 只需要将有必要的属性(需要根据开发文档的要求)来一一写出即可
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phone);
out.writeUTF(addr);
out.writeUTF(name);
out.writeInt(flow);
}
// 反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.phone = in.readUTF();
this.addr = in.readUTF();
this.name = in.readUTF();
this.flow = in.readInt();
}
}
2.map阶段的代码:
这里就是很常规的把文件里的数据给封装到对象中作为value,用户名作为key传递过去给reduce阶段
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SerialFlowMapper
extends Mapper<LongWritable, Text, Text, Flow> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 13877779999 bj zs 2145
String[] arr = value.toString().split(" ");
// 封装对象
Flow f = new Flow();
f.setPhone(arr[0]);
f.setAddr(arr[1]);
f.setName(arr[2]);
f.setFlow(Integer.parseInt(arr[3]));
context.write(new Text(f.getName()), f);
}
}
3.reduce阶段:
从数据的特点我们可以看出,一个手机号只会对应一个人,而一个人可能对应多个手机号。
统计每一个人花费的总流量:以name作为key传递过来,所以每个数组中就包含这个name的所有手机使用信息。
统计每一个人出现过的地方: 一个人可能出现过多个地方,但是这里我们还是用name作为key,传递过来的数组里包含这个用户的所有信息。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
// 统计每一个人花费的总流量 - Text, IntWritable
public class SerialFlowReducer
extends Reducer<Text, Flow, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<Flow> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (Flow val : values) {
sum += val.getFlow();
}
context.write(key, new IntWritable(sum));
}
}
// 统计每一个人出现过的地方
class SerialFlowReducer2
extends Reducer<Text, Flow, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Flow> values, Context context) throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
for (Flow val : values) {
sb.append(val.getAddr()).append("\t");
}
context.write(key, new Text(sb.toString()));
}
}
4.启动类:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class SerialFlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SerialFlowDriver.class);
job.setMapperClass(SerialFlowMapper.class);
job.setReducerClass(SerialFlowReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Flow.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,
new Path("hdfs://hadoop01:9000/txt/flow.txt"));
FileOutputFormat.setOutputPath(job,
new Path("hdfs://hadoop01:9000/result/serialflow"));
job.waitForCompletion(true);
}
}
分区(Partitioner):
作用:
用于对数据进行分类的
使用方法:
如果要自定义分区,需要定义一个类继承Partitioner类,覆盖其中的getPartition方法来指定分区逻辑
规则:
在MapReduce中要进行分区,默认对分区进行编号,编号从0开始递增
在MapReduce中,ReduceTask的数量默认就只有1个
每一个分区要对应一个ReduceTask,每一个ReduceTask都会产生一个结果文件
案例:计算每个学生每个月的考试总分
文件如下:
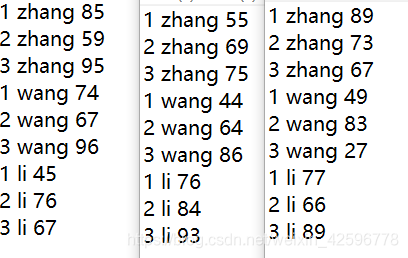
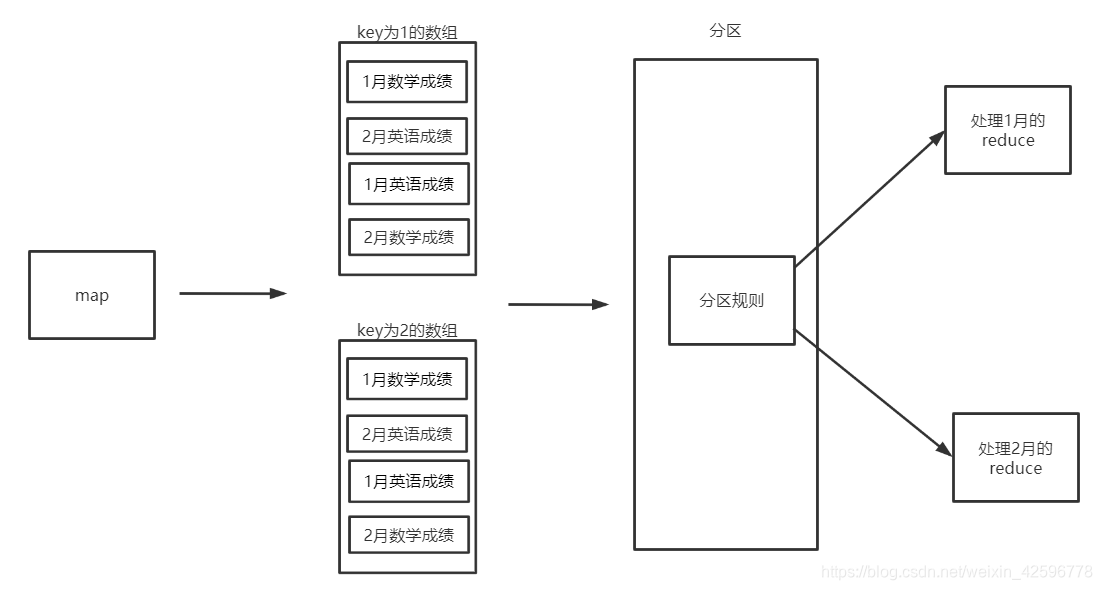
思路:我们可以先写一个类来做封装,虽然是三个文件,但是其实抽象思维一下,可以把他们看成一个大文件,map线程每次获取一行数据,把这个数据封装到对象中作为value,用学生名字来做key。
这里需要注意的是,在根据key组成数组发送给reduce之前,有一个分区的动作,分区会把已经分组好的数据,根据分区规则筛选一下,把符合规则的发配给同一个reduce
1.书写封装类:
package cn.tedu.partscore;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class PartScore implements Writable {
private int month;
private String name;
private int score;
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(month);
out.writeUTF(name);
out.writeInt(score);
}
@Override
public void readFields(DataInput in) throws IOException {
this.month = in.readInt();
this.name = in.readUTF();
this.score = in.readInt();
}
}
2.书写map:
package cn.tedu.partscore;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class PartScoreMapper
extends Mapper<LongWritable, Text, Text, PartScore> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] arr = value.toString().split(" ");
PartScore s = new PartScore();
s.setMonth(Integer.parseInt(arr[0]));
s.setName(arr[1]);
s.setScore(Integer.parseInt(arr[2]));
context.write(new Text(s.getName()), s);
}
}
3.书写分区类:
package cn.tedu.partscore;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class PartScorePartitioner
extends Partitioner<Text, PartScore> {
@Override
public int getPartition(Text key, PartScore value, int numPartitions) {
int month = value.getMonth();
//如month==1,就把该对象分配到0号reduce
if(month==1)
return 0;
if(month==2)
return 1;
if(month==3)
return 2;
}
}
4.书写reduce
package cn.tedu.partscore;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class PartScoreReducer
extends Reducer<Text, PartScore, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<PartScore> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (PartScore val : values) {
sum += val.getScore();
}
context.write(key, new IntWritable(sum));
}
}
5.启动类:
在写启动类的时候需要注意,如果不声明要几个reduce,默认就是1,后面输出文件也是1。
package cn.tedu.partscore;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class PartScoreDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(PartScoreDriver.class);
job.setMapperClass(PartScoreMapper.class);
job.setReducerClass(PartScoreReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PartScore.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//声明分区,和处理分区的reduce个数
job.setPartitionerClass(PartScorePartitioner.class);
job.setNumReduceTasks(5);
FileInputFormat.addInputPath(job,
new Path("hdfs://hadoop01:9000/txt/score1/"));
FileOutputFormat.setOutputPath(job,
new Path("hdfs://hadoop01:9000/result/partscore"));
job.waitForCompletion(true);
}
}


















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











