






 本文介绍如何使用Hadoop的MapReduce框架统计HDFS文件中各字符出现的次数,包括配置Maven依赖、编写Map和Reduce阶段代码以及运行MapReduce作业。
本文介绍如何使用Hadoop的MapReduce框架统计HDFS文件中各字符出现的次数,包括配置Maven依赖、编写Map和Reduce阶段代码以及运行MapReduce作业。
引入:
之前学习了hdfs,它是Hadoop的分布式存储系统,那么既然有了存储,我们就需要对存储的数据做一些操作,这就需要使用分布式计算系统MapReduce来做。
分布式计算过程:
使用统计字母个数的案例来解释计算过程
map(映射)过程:
MapReduce会把HDFS中的文件切片,然后每一片对应有个MapTask线程,每个MapTask线程处理每个分片的逻辑是相同的,默认对数据进行逐行处理,每片的字母和个数以key-value的形式保存起来。
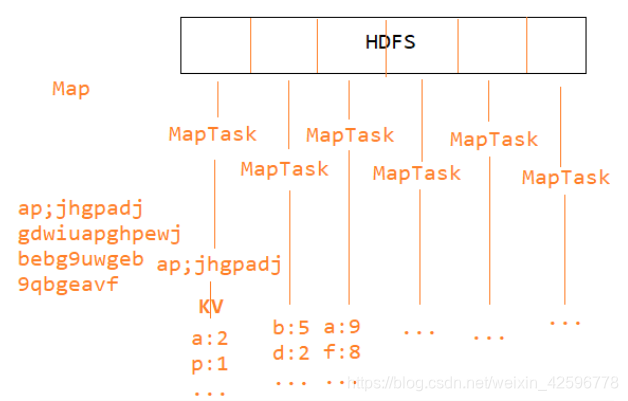
reduce(规约)阶段:
从上面可以看出,每个MapReduce已经计算出来自己分片的字母个数,接下来就需要算出总的文件各个字母个数。

使用Java来实现MapReduce操作HDFS计算文件字母出现次数:
1.导入pom文件和日志文件:
pom:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.tedu</groupId>
<artifactId>mr01</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency>
</dependencies>
</project>
日志文件log4j.properties粘贴到resources下。
2.Map阶段代码:
每一行数据,会被一个MapTask来操作,下面的代码就是针对一行数据。
需要注意的是Map阶段会把信息给转化为一个数组,然后使用context传递给reduce
package cn.tedu.charcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// 统计每一个字符出现的次数
// 在MapReduce中,要求数据能够被序列化
// KEYIN - 输入的键的类型。如果不指定,默认就是行的字节偏移量
// VALUEIN - 输入的值的类型。如果不指定,默认就是一行数据
// KEYOUT - 输出的键的类型。当前案例中,输出的键是字符
// VALUEOUT - 输出的值的类型。当前案例中,输出的值是次数
public class CharCountMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
// key:键,实际上就是行偏移量
// value:值,实际上就是一行数据
// context:利用这个参数将数据传递给Reduce
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// hello
// 先将这一行中的字符拆分出来
char[] cs = value.toString().toCharArray();
// {h, e, l, l, o}
// h:1 e:1 l:2 o:1
// h:1 e:1 l:1 l:1 o:1
for (char c : cs) {
context.write(new Text(c + ""),
new IntWritable(1));
}
}
}
3.reduce阶段代码:
这里需要解释的是,reduce阶段接收到的value是上面通过context传递过来的,底层会自动转化为一个迭代器,通过迭代器来遍历就可以
package cn.tedu.charcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
// KEYIN,VALUEIN - 输入的键值类型 - Reduce的数据来自Map
// 那么就意味着Map的输出就是Reduce的输入
// KEYOUT,VALUEOUT - 输出的键值类型
public class CharCountReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
// key:输入的键 - 字符
// values:输入的值。这个值已经进行过分组,将相同的键对应的值分到一组
// 分组之后产生一个迭代器
// context:利用这个参数将结果写到HDFS上
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// key = 'a'
// values = {1,1,1,1,1,1,1...}
// 求总次数
int sum = 0;
// 遍历迭代器来求和
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
启动类:
map和reduce阶段需要一个启动来启动
package cn.tedu.charcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class CharCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 环境参数
Configuration conf = new Configuration();
// 向YARN来申请任务
Job job = Job.getInstance(conf);
// 设置入口类
job.setJarByClass(CharCountDriver.class);
// 设置Mapper类
job.setMapperClass(CharCountMapper.class);
// 设置Reducer类
job.setReducerClass(CharCountReducer.class);
// 设置Mapper的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置Redcer的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入路径
FileInputFormat.addInputPath(job,
new Path("hdfs://hadoop01:9000/txt/characters.txt"));
// 设置输出路径
// 输出路径必须不存在
FileOutputFormat.setOutputPath(job,
new Path("hdfs://hadoop01:9000/result/charcount"));
// 提交任务
job.waitForCompletion(true);
}
}
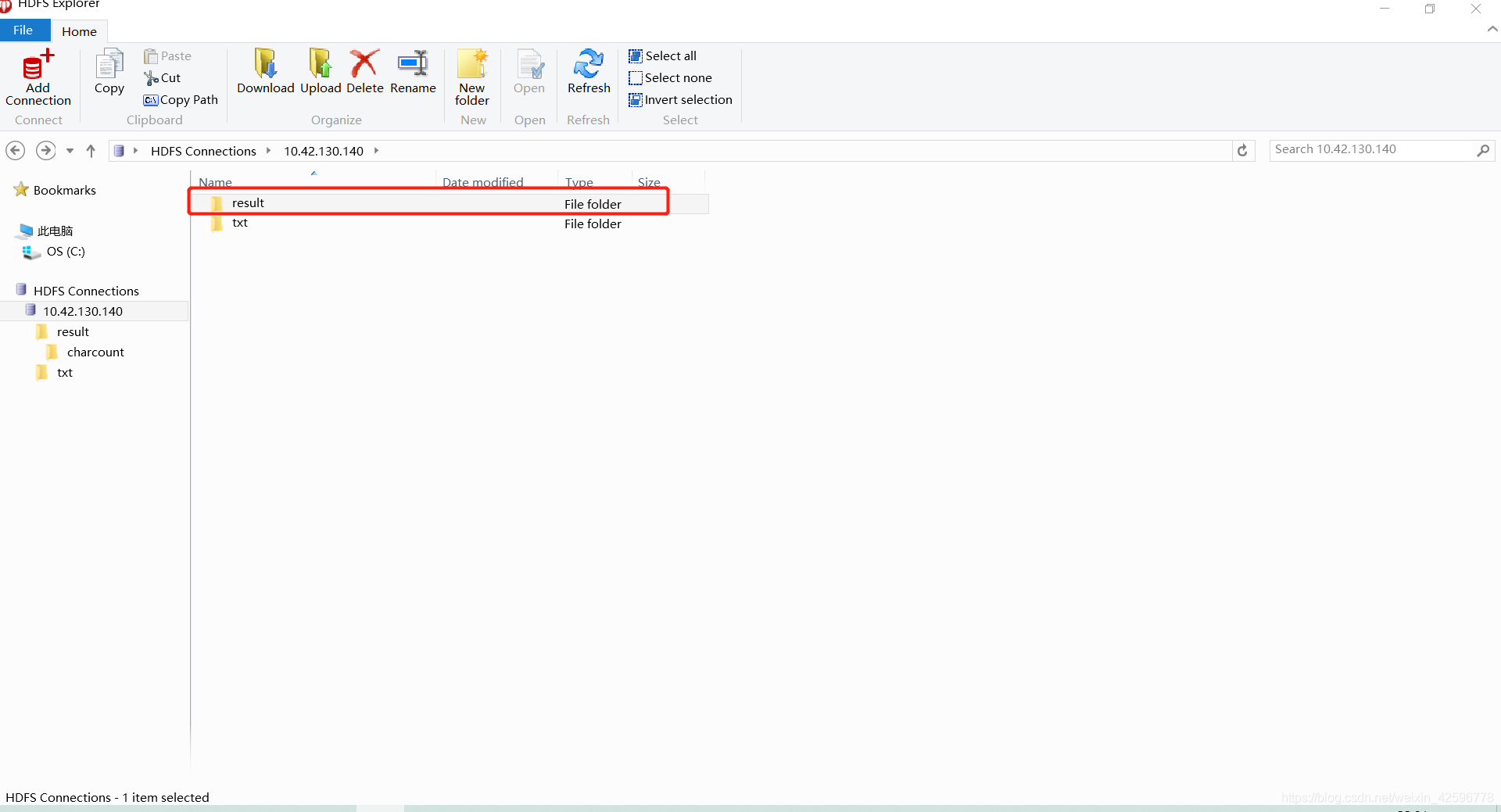
输出成功后就可以在hdfs上看见这个文件夹


















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











