






排序:
昨天说了MapReduce组件中的序列化和分区。今天接着说组件。
规则:
reduce阶段处理完数据后,输出的内容是可以按照我们自己的要求来排序的。除了基本数据类型外,如果是自定义数据类型,那么需要在类中继承一个WritableComparable接口,实现它的compareto方法来自定义比较规则。
注意:
如果两个键的compareTo结果为0,那么Reduce阶段会将这两个键看作是同一个键然后对应的值分到一组
案例:
先按照月份升序,如果月份一致则同一月中按照利润降序。
文件内容如下:
月份/名字/利润
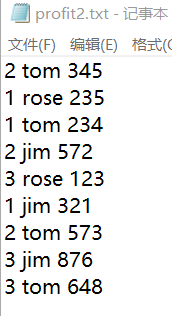
1.书写封装类:
package cn.tedu.sortprofit;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Profit implements WritableComparable<Profit> {
private int month;
private String name = "";
private int profit;
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getProfit() {
return profit;
}
public void setProfit(int profit) {
this.profit = profit;
}
// 先按照月份升序,如果月份一致则同一月中按照利润降序
@Override
public int compareTo(Profit o) {
int r1 = this.month - o.month;
if (r1 == 0) {
int r2 = o.profit - this.profit;
return r2 == 0 ? -1 : r2;
}
return r1;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(month);
out.writeUTF(name);
out.writeInt(profit);
}
@Override
public void readFields(DataInput in) throws IOException {
this.month = in.readInt();
this.name = in.readUTF();
this.profit = in.readInt();
}
@Override
public String toString() {
return month + " " + name + " " + profit;
}
}
2.map类
因为所有信息都在key中了,所以value就给了一个null
package cn.tedu.sortprofit;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SortProfitMapper
extends Mapper<LongWritable, Text, Profit, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] arr = value.toString().split(" ");
Profit p = new Profit();
p.setMonth(Integer.parseInt(arr[0]));
p.setName(arr[1]);
p.setProfit(Integer.parseInt(arr[2]));
context.write(p, NullWritable.get());
}
}
3.reduce类:
package cn.tedu.sortprofit;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SortProfitReducer
extends Reducer<Profit, NullWritable, Profit, NullWritable> {
@Override
protected void reduce(Profit key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
4.启动类:
package cn.tedu.sortprofit;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class SortProfitDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SortProfitDriver.class);
job.setMapperClass(SortProfitMapper.class);
job.setReducerClass(SortProfitReducer.class);
job.setMapOutputKeyClass(Profit.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Profit.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job,
new Path("hdfs://hadoop01:9000/txt/profit3.txt"));
FileOutputFormat.setOutputPath(job,
new Path("hdfs://hadoop01:9000/result/sortprofit3"));
job.waitForCompletion(true);
}
}
合并:
之前做的都是所有mapTask封装好数据给到RduceTask来进行计算,所谓的合并,就是在交给reduce之前,每个map自己先算好,最后把各自的数据再给reduce,这样reduce就可以减少很多的计算量。
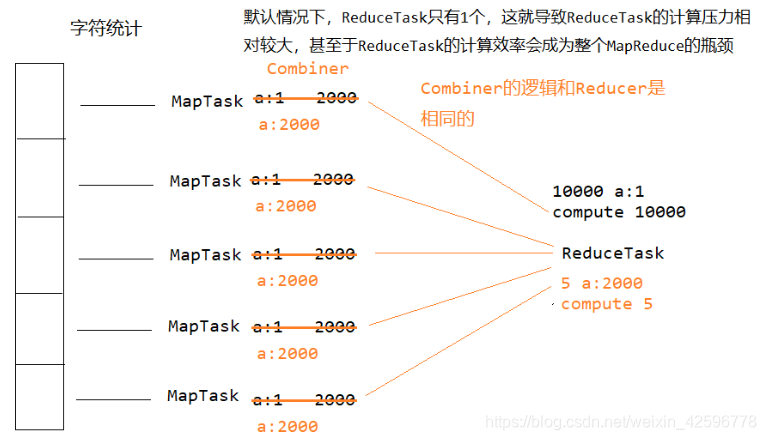
如上图所示,每一个mapTask有2000个1,如果他们直接把数据给reduceTask,那么reduce要计算1w个1相加,但是如果每个map自己算好了自己的那一部分,到了reduce这里它就只需要计算5个2000相加就可以。
使用合并:
非常简单,在启动类中声明一下就可以,mapReduce自动使用
job.setCombinerClass(SortScoreReducer.class);
注意:
Combiner能够有效的提高MapReduce的效率,但不是所有的场景都是和与使用Combiner。例如求和、求最值、去重等可传递运算的场景可以使用Combiner,例如求平均等不可传递的场景不能使用Combiner
MapReduce的基本理论:
数据本地化策略:
一个分块(block)一般是128m,而分片在一般开发中,也是规定128m,这样 分块数=分片数。
主节点(JobTracker): 用来从HDFS的NameNode中接收元数据,获取任务的block,对block进行切片,每一个切片分配给一个map。
切片: 一种逻辑上的切分,根据任务量(block的数量大小)来确定map的线程个数。
切片的规则:
如果是空文件,则整个文件作为1个切片处理
文件存在可切与不可切两种。例如绝大部分的压缩文件都市不可切的。如果文件不可切,则整个文件作为1个切片来进行处理
默认情况下,Split和Block的大小一致 如果要调小splitSize,那么需要调小maxSize -
FileInputFormat.setMaxInputSplitSize();如果要调大splitSize,那么需要调大minSize -
FileInputFormat.setMinInputSplitSize();在切片过程中,存在切片与之SPLIT_SLOP=1.1,如果剩余文件大小/splitSize>1.1才会继续切,不然剩下的数据就会作为1个切片处理
从节点(TaskTracker): 接收到map来进行处理。
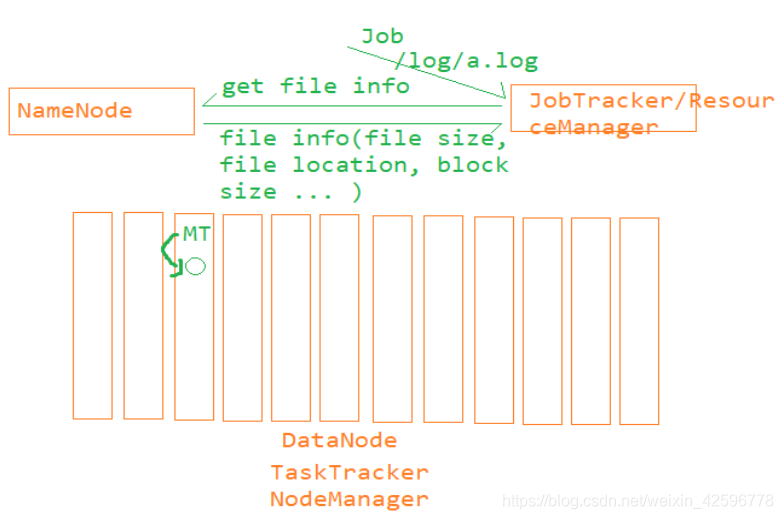
数据本地化策略:
- 在实际生产过程中,会考虑将DataNode和TaskTracker部署在相同的节点上,因为这样做可以减少TaskTracker跨集群去拿block中的数据。
- 在分配任务的时候,考虑尽量将任务分配到有对应数据的节点上,这样做就保证数据是从本地读取减少了集群中节点之间的网络消耗
Job执行的流程:
启动类中,我们创建了一个job对象,并且通过该对象绑定了map,reduce以及他们的输出形式和位置,下面就来细说一下Job的执行流程。
提交阶段: 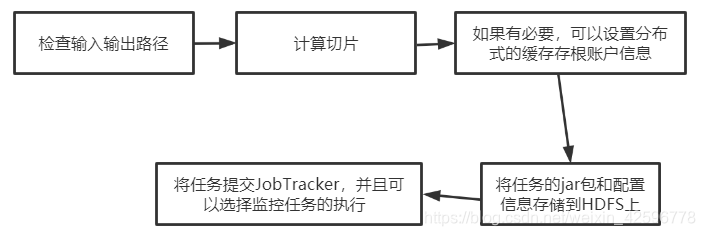
执行阶段 :
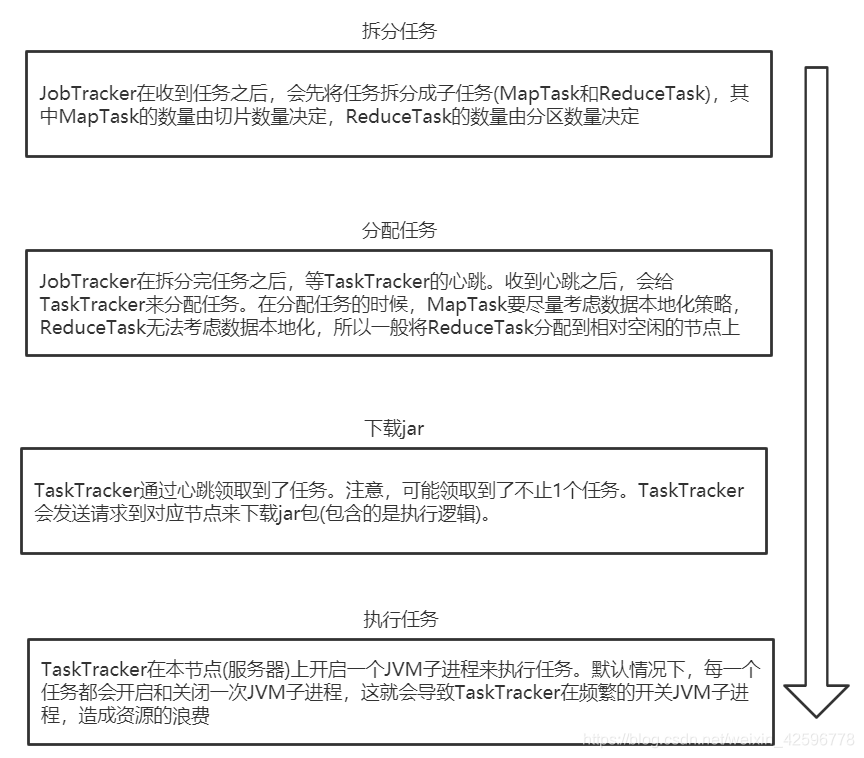
uber模式:
上面说过,taskTracker会去JobTracker那里领取任务,一个分片就是一个任务,如果分片过多,任务就过多,导致map过多,那么就会耗费大量资源,通过Uber模式,可以节省一些资源。
uber默认不开启,此时每一个任务都会开启和关闭一次JVM子进程 。
开启uber模式:
配置mapred-site.xml中




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











