






 本文探讨了Hadoop中常见的数据倾斜、join操作、小文件问题及推测执行机制的优化方法,包括二阶段聚合、缓存利用、文件打包及合理配置推测执行。
本文探讨了Hadoop中常见的数据倾斜、join操作、小文件问题及推测执行机制的优化方法,包括二阶段聚合、缓存利用、文件打包及合理配置推测执行。
1.数据倾斜:
原因:
因为又分区的情况,导致Reduce阶段的ReduceTask处理的数据量不一样,可能有的多有的少,这就产生了数据倾斜的问题。
另外还有可能发生Map阶段的数据倾斜,但是需要满足3个条件:多输入源,文件不可切分,文件大小不均等。
reduce阶段的数据倾斜如何优化?
- 二阶段聚合:
第一阶段:把数据打散,进行部分聚合
第二阶段:根据分区条件来进行聚合
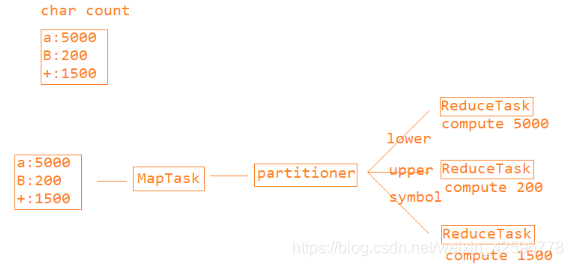
没有使用二阶段聚合:
每一个reduceTask处理的数据量都不一样,可以明显的看出第一个reduceTask的处理数据量比另外两个要大很多,所以九发生了数据倾斜
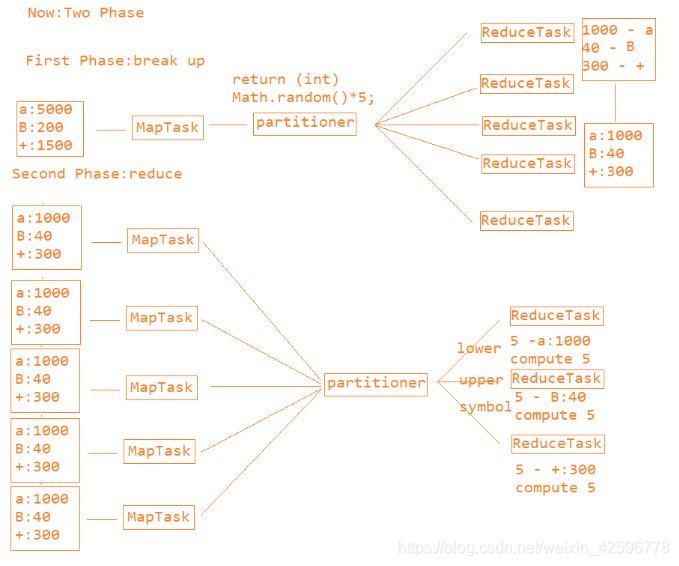
使用了二阶段聚合:
在一个阶段,把任务平均分一下到各个reduceTask中进行计算,然后第二个mapTask去拿数据,拿出各个reduceTask计算出来的数据,把这些数据分区进行计算。
2.join
什么时候使用join?
如果两个或者多个文件之间相互关联,那么此时就需要使用join操作
使用方法:
分析需求确定好键值之后,就可以确定哪个文件作为主处理文件,其他的关联文件需要放到缓存中。在Mapper处理的时候,先将缓存中文件取出来先处理,然后再利用map方法来处理主文件,在处理主文件的过程中,如果需要用到缓存中的内容,那么就可以直接获取
3.小文件
小文件存在的问题:
- 存储:大量小文件,就会产生大量的元数据,导致内存被大量占用,降低查询效率
- 计算:大量小文件,就会产生大量的切片,导致产生大量的线程(MapTask),增加服务器(集群)的并发压力
小文件的解决方案:
合并和打包。
打包的方式:Hadoop提供了原生的打包方式:Hadoop Archive。例如:hadoop archive -archiveName txt.har -p /txt /result - 实际上就是利用合并+索引的方式来实现可切的打包过程
4.推测执行机制
是Hadoop自身提供的一种任务执行的优化方案:
当集群中出现慢任务的时候,Hadoop会将这个慢任务复制一份到其他节点上,两个节点同时执行相同的任务,谁先执行完成,那么这个结果就作为最后结果,而另一个没有完成的任务会被kill
慢任务出现的场景:
- 任务分配不均匀
- 服务器性能不一致
- 数据倾斜
问题:
数据倾斜的情况下,任务本身就慢,所以开启推测机制是没有意义的,所以一般都会关闭推测机制。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











