




 博主参加了招行FinTech精英训练营的线上竞赛,主要任务是识别财务造假。面对数据不平衡问题,博主尝试了特征选择、标准化、离散化、欠采样和过采样等多种方法。尽管遇到挑战,但通过不断尝试和调整,最终取得了0.095的分数。博主反思了数据集不平衡对模型的影响,以及离群值处理的策略,并探讨了特征选择和降维的方法。
博主参加了招行FinTech精英训练营的线上竞赛,主要任务是识别财务造假。面对数据不平衡问题,博主尝试了特征选择、标准化、离散化、欠采样和过采样等多种方法。尽管遇到挑战,但通过不断尝试和调整,最终取得了0.095的分数。博主反思了数据集不平衡对模型的影响,以及离群值处理的策略,并探讨了特征选择和降维的方法。
暂时总结线上竞赛部分,等面试完后再看情况是否更新这篇文章。
因为涉及隐私数据,所以我只能边提思路边提供自己的部分代码,数据方面就无能为力啦。
实际用到的代码进过了多重改动,所以本文的代码会出现部分命名混乱的情况,思路为主,不要在意这种小问题。
FinTech是什么
简单地说,它是招行为了选拔训练营的人才而设立的 竞赛 。这是我第一次参加实战,本来也没奢望能拿到面试资格,没想到再过几天就要去面试了,姑且总结下思路与经验,以备往后温习和各位借鉴。大佬们欢迎留言或私信我交流更好的思路呀~
线上竞赛思路
选题
- 第五题 识别财务造假
- 样本数量 7653,其中正负样本数量比约 1:70,只有少数缺失值
- 提供了34个特征,标签为 ”fake“,1 表示财务造假,0 表示没有造假
- 评分标准: f 1 = 2 R e c a l l × P r e c i s i o n ( R e c a l l + P r e c i s i o n ) , f1 = \frac {2Recall \times Precision} {(Recall + Precision)}, f1=(Recall+Precision)2Recall×Precision,
其中
R e c a l l = T P T P + F N Recall=\frac{TP} {TP + FN} Recall=TP+FNTP 表示的是全部实际为正的样本中,成功被预测(召回)的比例,如果有”漏网之鱼“的代价很大,那么通常要求 Recall 足够高!
P r e c i s i o n = T P T P + F P Precision=\frac{TP} {TP + FP} Precision=TP+FPTP 表示的是预测为正的样本中,实际上确实为正样本的比例,如果”错杀“的代价很大,那么就要求 Precision足够高!
一番权衡下,就有了新的指标 f 1 f1 f1。
尝试一
不做任何特征工程与数据预处理,连缺失值也不管,数据集也没划分,直接开干,轮番将 knn, svm, mlp, naive bayes, randomforest, adaboost, xgb 都用默认参数进行拟合预测,天,accuracy妥妥的 90%+,一提交,稳了,直接零分。。。。。。
用 n p . s u m ( d a t a . f a k e = = 1 ) np.sum(data.fake == 1) np.sum(data.fake==1) 看了下,只有 109 条正样本,明显的数据集不平衡。赶紧查了下数据集失衡下的 常规操作 ,首选的两个做法是重采样以及合理地进行特征选择。
这一部分的处理流程主要是:特征选择——标准化——离散化——欠采样——训练——过采样——训练。
先用直方图查看下数据分布,我随便挑选了其中四个有代表性的分布:
import matplotlib.pyplot as plt
cols = features.columns
for col in cols:
plt.hist(features[col], bins=200)
plt.show()
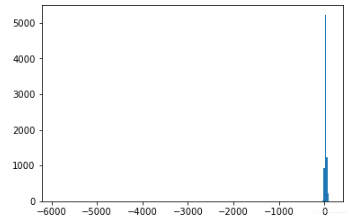
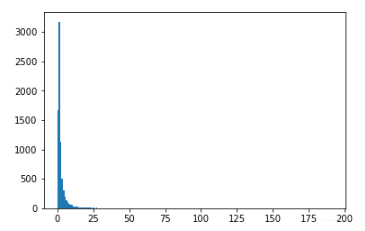
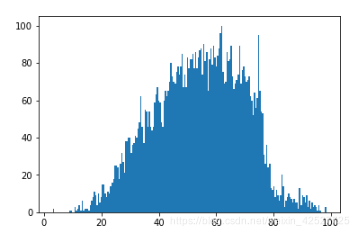
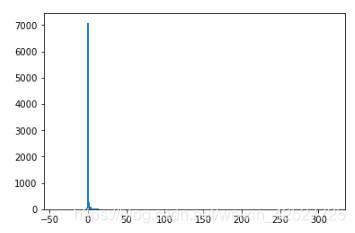
看起来每个特征的分布很离散,有很明显的离群值,我最初觉得这些离群值可能有重要的区分作用,所以没有将它去除(BTW:这些离群值也许真的是高分的关键——毕竟第一名 0.77 远远把第二名甩在后头……只是我还不知道怎么利用离群值来辅助分类,大佬们如果有好的想法赶紧留言或给我私信!!!!)。
但我还是将所有特征视为一个整体做了一次异常值检测,用的是 LOF,只检测出两个异常样本,直接删除。在这一步之前还有个缺失值处理的过程,只有一个特征的3个值缺失,我将其设为 0。
from sklearn.neighbors import LocalOutlierFactor as LOF
lof = LOF(n_neighbors=35, contamination=0.05, n_jobs=-1)
# y_pred = lof.fit_predict(np.reshape(features.A_to_L_ratio, (-1, 1)))
# for i in range(len(features.columns)):
copy_ = features.iloc[:, 0:1].copy()
y_pred = lof.fit_predict(copy_)
copy_.iloc[y_pred, 0:1] = np.nan
copy_data.dropna(how='any', inplace=True)
copy_data.reset_index(inplace=True)
copy_data.drop(columns=['index', 'stockcode'], inplace=True)
下一步,用 pandas.corr() 输出协方差矩阵,将与标签相关性最低的若干个特征 drop 掉。
more_related_cols = []
indices = correlation.index
for i in range(len(cols)):
if abs(correlation[i]) > 0.01:
more_related_cols.append(indices[i])
# 这里保留了 13 个特征
more_related_cols
进一步地,我还分别用了统计学的 f 值和信息论的互信息来进一步筛选,下面的代码是使用 f 值的部分,选出 10 个数值最高的特征。
from sklearn.feature_selection import mutual_info_classif, f_classif, SelectKBest
select = SelectKBest(f_classif, k=10)
select.fit(r_features, r_labels)
# select.scores_
more_related_cols_from_f_classif = [more_related_cols[i] for i in range(len(more_related_cols)) if i in [0, 1, 2, 4, 5, 6, 7, 8, 10, 11, 12]]
more_related_cols_from_f_classif
下一步是标准化。因为一时半会还没想明白哪种方法合适,索性全部用了 MinMax。
'''standardization'''
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
r2_features = mm.fit_transform(r_features[more_related_cols_from_f_classif])
r2_features.shape
这里保险起见,我对特征矩阵单独再用了 corr() 剔除了相关性在 0.75 以上的特征。
下一步是离散化。我才发现 sklearn 里面集成了等距、等频、聚类三大类,牛逼。因为数值总体非常离散,而有的又非常集中,感觉等距的话受离群值影响很大,等频的也不合适,所以我首选的是聚类法。
from sklearn.preprocessing import KBinsDiscretizer
kb = KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='kmeans')
df_r2[more_related_cols_from_f_classif] = kb.fit_transform(df_r2[more_related_cols_from_f_classif])
现在终于要采样训练了。第一次用 imblearn,什么都不懂,用了最基础的随机欠采样方法,将正负样本比例控制在 0.2~0.9以内(都试试)。
from imblearn.under_sampling import RandomUnderSampler
resample = RandomUnderSampler 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2719
2719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









