







 本文介绍了Spark Shell的使用,包括其作为开发工具的优势和操作原理,以及RDD的Transformation和Action操作。通过示例展示了如何进行数据加载、统计用户收藏商品数量、去重和排序等操作。同时,对比了Spark Scala API和Java API在实现相同功能时的代码差异,强调了Scala API的简洁高效。
本文介绍了Spark Shell的使用,包括其作为开发工具的优势和操作原理,以及RDD的Transformation和Action操作。通过示例展示了如何进行数据加载、统计用户收藏商品数量、去重和排序等操作。同时,对比了Spark Scala API和Java API在实现相同功能时的代码差异,强调了Scala API的简洁高效。
Spark Shell操作
Spark shell是一个特别适合快速开发Spark程序的工具。即使你对Scala不熟悉,仍然可以使用这个工具快速应用Scala操作Spark。
Spark shell使得用户可以和Spark集群交互,提交查询,这便于调试,也便于初学者使用Spark。
Spark shell是非常方便的,因为它很大程度上基于Scala REPL(Scala交互式shell,即Scala解释器),并继承了Scala REPL(读取-求值-打印-循环)(Read-Evaluate-Print-Loop)的所有功能。运行spark-shell,则会运行spark-submit,spark-shell其实是对spark-submit的一层封装。
下面是Spark shell的运行原理图:

RDD有两种类型的操作 ,分别是Transformation(返回一个新的RDD)和Action(返回values)。
1.Transformation:根据已有RDD创建新的RDD数据集build
- (1)map(func):对调用map的RDD数据集中的每个element都使用func,然后返回一个新的RDD,这个返回的数据集是分布式的数据集。
- (2)filter(func) :对调用filter的RDD数据集中的每个元素都使用func,然后返回一个包含使func为true的元素构成的RDD。
- (3)flatMap(func):和map很像,但是flatMap生成的是多个结果。
- (4)mapPartitions(func):和map很像,但是map是每个element,而mapPartitions是每个partition。
- (5)mapPartitionsWithSplit(func):和mapPartitions很像,但是func作用的是其中一个split上,所以func中应该有index。
- (6)sample(withReplacement,faction,seed):抽样。
- (7)union(otherDataset):返回一个新的dataset,包含源dataset和给定dataset的元素的集合。
- (8)distinct([numTasks]):返回一个新的dataset,这个dataset含有的是源dataset中的distinct的element。
- (9)groupByKey(numTasks):返回(K,Seq[V]),也就是Hadoop中reduce函数接受的key-valuelist。
- (10)reduceByKey(func,[numTasks]):就是用一个给定的reduce func再作用在groupByKey产生的(K,Seq[V]),比如求和,求平均数。
- (11)sortByKey([ascending],[numTasks]):按照key来进行排序,是升序还是降序,ascending是boolean类型。
2.Action:在RDD数据集运行计算后,返回一个值或者将结果写入外部存储
- (1)reduce(func):就是聚集,但是传入的函数是两个参数输入返回一个值,这个函数必须是满足交换律和结合律的。
- (2)collect():一般在filter或者足够小的结果的时候,再用collect封装返回一个数组。
- (3)count():返回的是dataset中的element的个数。
- (4)first():返回的是dataset中的第一个元素。
- (5)take(n):返回前n个elements。
- (6)takeSample(withReplacement,num,seed):抽样返回一个dataset中的num个元素,随机种子seed。
- (7)saveAsTextFile(path):把dataset写到一个textfile中,或者HDFS,或者HDFS支持的文件系统中,Spark把每条记录都转换为一行记录,然后写到file中。
- (8)saveAsSequenceFile(path):只能用在key-value对上,然后生成SequenceFile写到本地或者Hadoop文件系统。
- (9)countByKey():返回的是key对应的个数的一个map,作用于一个RDD。
- (10)foreach(func):对dataset中的每个元素都使用func。
WordCount统计:某电商网站记录了大量的用户对商品的收藏数据,并将数据存储在名为buyer_favorite的文本文件中。文本数据格式如下:
用户id(buyer_id),商品id(goods_id),收藏日期(dt)
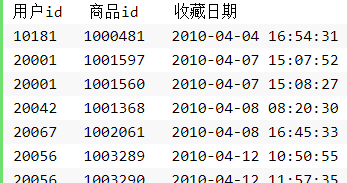
现要求统计用户收藏数据中,每个用户收藏商品数量。
1.在Linux上,创建/data/spark3/wordcount目录,用于存储实验所需的数据。
- mkdir -p /data/spark3/wordcount
切换目录到/data/spark3/wordcount下,并从http://59.64.78.41:60000/allfiles/spark3/wordcount/buyer_favorite下载实验数据。
- cd /data/spark3/wordcount
- wget http://59.64.78.41:60000/allfiles/spark3/wordcount/buyer_favorite
2.使用jps查看Hadoop以及Spark的相关进程是否已经启动,若未启动则执行启动命令。
- jps
- /apps/hadoop/sbin/start-all.sh
- /apps/spark/sbin/start-all.sh
将Linux本地/data/spark3/wordcount/buyer_favorite文件,上传到HDFS上的/myspark3/wordcount目录下。若HDFS上/myspark3目录不存在则需提前创建。
- hadoop fs -mkdir -p /myspark3/wordcount
- hadoop fs -put /data/spark3/wordcount/buyer_favorite /myspark3/wordcount
3.启动spark-shell
- spark-shell
4.编写Scala语句,统计用户收藏数据中,每个用户收藏商品数量。
先在spark-shell中,加载数据。
- val rdd = sc.textFile("hdfs://localhost:9000/myspark3/wordcount/buyer_favorite");
执行统计并输出。
- rdd.map(line=> (line.split('\t')(0),1)).reduceByKey(_+_).collect

去重:使用spark-shell,对上述实验中,用户收藏数据文件进行统计。根据商品ID进行去重,统计用户收藏数据中都有哪些商品被收藏。
1.在Linux上,创建/data/spark3/distinct,用于存储实验数据。
- mkdir -p /data/spark3/distinct
切换到/data/spark3/distinct目录下,并从http://59.64.78.41:60000/allfiles/spark3/distinct/buyer_favorite下载实验数据。
- cd /data/spark3/distinct
- wget http://59.64.78.41:60000/allfiles/spark3/distinct/buyer_favorite
2.使用jps查看Hadoop,Spark的进程。保证Hadoop、Spark框架相关进程为已启动状态。
3.将/data/spark3/distinct/buyer_favorite文件,上传到HDFS上的/myspark3/distinct目录下。若HDFS目录不存在则创建。
- hadoop fs -mkdir -p /myspark3/distinct
- hadoop fs -put /data/spark3/distinct/buyer_favorite /myspark3/distinct
4.在Spark窗口,编写Scala语句,统计用户收藏数据中,都有哪些商品被收藏。
先加载数据,创建RDD。
- val rdd = sc.textFile("hdfs://localhost:9000/myspark3/distinct/buyer_favorite");
对RDD进行统计并将结果打印输出。
- rdd.map(line => line.split('\t')(1)).distinct.collect

排序:电商网站都会对商品的访问情况进行统计,现有一个goods_visit文件,存储了电商网站中的各种商品以及此各个商品的点击次数。
商品id(goods_id) 点击次数(click_num)
- 商品ID 点击次数
- 1010037 100
- 1010102 100
- 1010152 97
- 1010178 96
- 1010280 104
- 1010320 103
- 1010510 104
- 1010603 96
- 1010637 97
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









