






什么是扩散模型
关于GAN、VAE和基于Flow模型的生成模型。在生成高质量样本方面取得了巨大成功,但每个都有其自身的局限性。GAN 模型因其对抗性训练性质而以潜在的不稳定训练和较少的生成多样性而闻名。VAE 依赖于替代损失。流模型必须使用专门的架构来构建可逆变换。
扩散模型的灵感来自于非平衡热力学。他们定义了一个扩散步骤的马尔可夫链,慢慢地向数据中添加随机噪声,然后学习反向扩散过程,从噪声中构建所需的数据样本。与VAE或流动模型不同,扩散模型的学习过程是固定的,潜在变量具有高维性(与原始数据相同)。
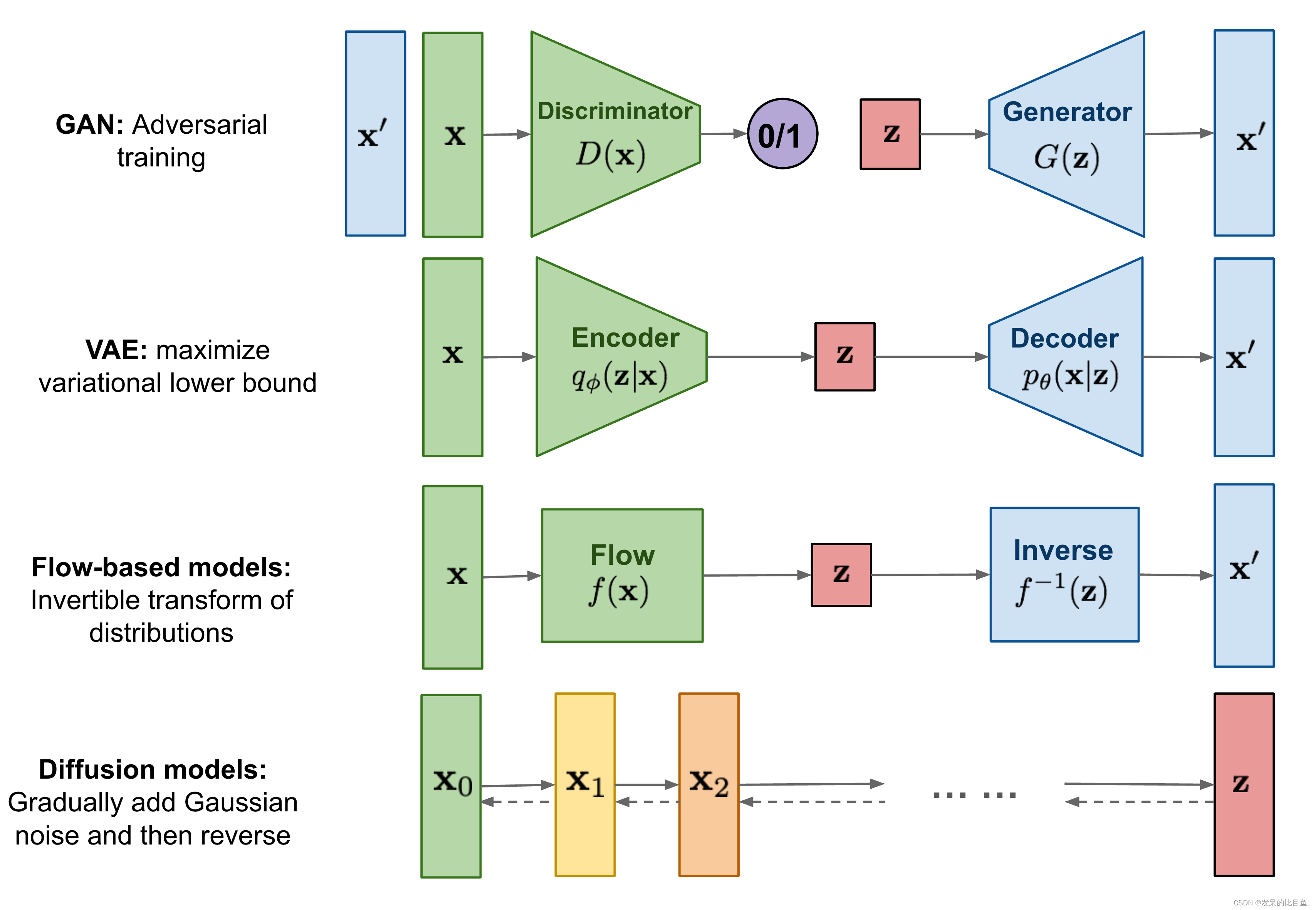
什么是扩散模型
人们提出了几种基于扩散的生成模型,其中包括扩散概率模型(Sohl-Dickstein et al., 2015)、噪声条件评分网络(NCSN;Yang & Ermon, 2019)和去噪扩散概率模型(DDPM; Hoet al.,2020)。
向前扩散过程
给定一个从真实数据分布中抽样的数据点
x
0
∼
q
(
x
)
\mathbf{x}_0 \sim q(\mathbf{x})
x0∼q(x), 让我们定义一个正向扩散过程,在
T
T
T步中向样本添加少量高斯噪声,产生一个噪声样本序列
x
1
,,
x
T
x_1,,x_T
x1,,xT。步长大小由方差控制:
{
β
t
∈
(
0
,
1
)
}
t
=
1
T
\{\beta_t \in (0, 1)\}_{t=1}^T
{βt∈(0,1)}t=1T
q
(
x
t
∣
x
t
−
1
)
=
N
(
x
t
;
1
−
β
t
x
t
−
1
,
β
t
I
)
q
(
x
1
:
T
∣
x
0
)
=
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t\mathbf{I}) \quad q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) = \prod^T_{t=1} q(\mathbf{x}_t \vert \mathbf{x}_{t-1})
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
随着步长
t
t
t的增大,数据样本
x
0
x_0
x0逐渐失去其可区分的特征。最终当
T
T
T时,
x
T
x_T
xT等价于各向同性高斯分布。
上述过程的一个很好的特性是,我们可以使用重新参数化技巧在任意时间步 t t t以封闭形式对 x t x_t xt进行采样。令 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt 和 α ˉ t = ∏ i = 1 T α i \bar{\alpha}_t = \prod_{i=1}^T \alpha_i αˉt=∏i=1Tαi
x t = α t x t − 1 + 1 − α t z t − 1 ;where z t − 1 , z t − 2 , ⋯ ∼ N ( 0 , I ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 z ˉ t − 2 ;where z ˉ t − 2 merges two Gaussians (*). = … = α ˉ t x 0 + 1 − α ˉ t z q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) \begin{aligned} \mathbf{x}_t &= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1 - \alpha_t}\mathbf{z}_{t-1} & \text{ ;where } \mathbf{z}_{t-1}, \mathbf{z}_{t-2}, \dots \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\ &= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\mathbf{z}}_{t-2} & \text{ ;where } \bar{\mathbf{z}}_{t-2} \text{ merges two Gaussians (*).} \\ &= \dots \\ &= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\mathbf{z} \\ q(\mathbf{x}_t \vert \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I}) \end{aligned} xtq(xt∣x0)=αtxt−1+1−αtzt−1=αtαt−1xt−2+1−αtαt−1zˉt−2=…=αˉtx0+1−αˉtz=N(xt;αˉtx0,(1−αˉt)I) ;where zt−1,zt−2,⋯∼N(0,I) ;where zˉt−2 merges two Gaussians (*).
(*)回想一下,当我们合并两个方差不同的高斯函数时 N ( 0 , σ 1 2 I ) \mathcal{N}(\mathbf{0}, \sigma_1^2\mathbf{I}) N(0,σ12I)和$\mathcal{N}(\mathbf{0}, \sigma_2^2\mathbf{I})
,新的分布是 ,新的分布是 ,新的分布是\mathcal{N}(\mathbf{0}, (\sigma_1^2 + \sigma_2^2)\mathbf{I}) , 合并标准差是 ,合并标准差是 ,合并标准差是\sqrt{(1 - \alpha_t) + \alpha_t (1-\alpha_{t-1})} = \sqrt{1 - \alpha_t\alpha_{t-1}}$
通常情况下,当样本噪音更大时,我们可以承担更大的更新步骤,所以 β 1 < β 2 < ⋯ < β T \beta_1 < \beta_2 < \dots < \beta_T β1<β2<⋯<βT和 α ˉ 1 > ⋯ > α ˉ T \bar{\alpha}_1 > \dots > \bar{\alpha}_T αˉ1>⋯>αˉT
与随机梯度Langevin动力学关系
Langevin 动力学是一个来自物理学的概念,用于分子系统的统计建模。结合随机梯度下降,随机梯度Langevin动力学(Welling & Teh 2011)仅使用马尔可夫更新链中的梯度
∇
x
l
o
g
p
(
x
)
\nabla xlog p(x)
∇xlogp(x)就可以从概率密度
p
(
x
)
p(x)
p(x)中产生样本:
x
t
=
x
t
−
1
+
ϵ
2
∇
x
log
p
(
x
t
−
1
)
+
ϵ
z
t
,
where
z
t
∼
N
(
0
,
I
)
\mathbf{x}_t = \mathbf{x}_{t-1} + \frac{\epsilon}{2} \nabla_\mathbf{x} \log p(\mathbf{x}_{t-1}) + \sqrt{\epsilon} \mathbf{z}_t ,\quad\text{where } \mathbf{z}_t \sim \mathcal{N}(\mathbf{0}, \mathbf{I})
xt=xt−1+2ϵ∇xlogp(xt−1)+ϵzt,where zt∼N(0,I)
其中,
ϵ
\epsilon
ϵ是步长。当
T
→
∞
,
ϵ
→
0
T \to \infty, \epsilon \to 0
T→∞,ϵ→0时,
X
T
X^T
XT等于真实概率密度
p
(
x
)
p(x)
p(x)。
与标准SGD相比,随机梯度Langevin动力学在参数更新中注入了高斯噪声,避免了陷入局部极小值。
反向扩散过程
如果我们可以逆转上述过程,并从
q
(
x
t
−
1
∣
x
t
)
q(\mathbf{x}_{t-1} \vert \mathbf{x}_t)
q(xt−1∣xt)采样,我们将能够从高斯噪声输入
x
T
∼
N
(
0
,
I
)
\mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I})
xT∼N(0,I)重建真实的样本。注意,如果
β
t
β_t
βt足够小,
q
(
x
t
−
1
∣
x
t
)
q(\mathbf{x}_{t-1} \vert \mathbf{x}_t)
q(xt−1∣xt)也将是高斯分布。不幸的是,我们不能轻易地估计
q
(
x
t
−
1
∣
x
t
)
q(\mathbf{x}_{t-1} \vert \mathbf{x}_t)
q(xt−1∣xt),因为它需要使用整个数据集,因此我们需要学习一个模型
p
θ
p_θ
pθ来近似这些条件概率,以便运行反向扩散过程。
p
θ
(
x
0
:
T
)
=
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
p
θ
(
x
t
−
1
∣
x
t
)
=
N
(
x
t
−
1
;
μ
θ
(
x
t
,
t
)
,
Σ
θ
(
x
t
,
t
)
)
p_\theta(\mathbf{x}_{0:T}) = p(\mathbf{x}_T) \prod^T_{t=1} p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) \quad p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t))
pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))

值得注意的是,当条件为
x
0
x_0
x0时,反向条件概率是
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
N
(
x
t
−
1
;
μ
~
(
x
t
,
x
0
)
,
β
~
t
I
)
q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_{t-1}; \color{blue}{\tilde{\boldsymbol{\mu}}}(\mathbf{x}_t, \mathbf{x}_0), \color{red}{\tilde{\beta}_t} \mathbf{I})
q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0),β~tI)
也就是说,给定
x
t
x_t
xt,和
x
0
x_0
x0,我们是可以计算出
x
t
−
1
x_{t-1}
xt−1
注意:高斯分布的概率密度函数是
f
(
x
)
=
1
2
π
σ
e
−
(
x
−
μ
)
2
2
σ
2
f(x)=\frac{1}{\sqrt{2\pi\sigma}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}
f(x)=2πσ1e−2σ2(x−μ)2
注意: a x 2 + b x = a ( x + b 2 a ) 2 + C ax^2+bx=a(x+\frac{b}{2a})^2+C ax2+bx=a(x+2ab)2+C
使用贝叶斯规则,我们有
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
t
∣
x
0
)
∝
exp
(
−
1
2
(
(
x
t
−
α
t
x
t
−
1
)
2
β
t
+
(
x
t
−
1
−
α
ˉ
t
−
1
x
0
)
2
1
−
α
ˉ
t
−
1
−
(
x
t
−
α
ˉ
t
x
0
)
2
1
−
α
ˉ
t
)
)
=
exp
(
−
1
2
(
x
t
2
−
2
α
t
x
t
x
t
−
1
+
α
t
x
t
−
1
2
β
t
+
x
t
−
1
2
−
2
α
ˉ
t
−
1
x
0
x
t
−
1
+
α
ˉ
t
−
1
x
0
2
1
−
α
ˉ
t
−
1
−
(
x
t
−
α
ˉ
t
x
0
)
2
1
−
α
ˉ
t
)
)
=
exp
(
−
1
2
(
(
α
t
β
t
+
1
1
−
α
ˉ
t
−
1
)
x
t
−
1
2
−
(
2
α
t
β
t
x
t
+
2
α
ˉ
t
−
1
1
−
α
ˉ
t
−
1
x
0
)
x
t
−
1
+
C
(
x
t
,
x
0
)
)
)
\begin{aligned} q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) &= q(\mathbf{x}_t \vert \mathbf{x}_{t-1}, \mathbf{x}_0) \frac{ q(\mathbf{x}_{t-1} \vert \mathbf{x}_0) }{ q(\mathbf{x}_t \vert \mathbf{x}_0) } \\ &\propto \exp \Big(-\frac{1}{2} \big(\frac{(\mathbf{x}_t - \sqrt{\alpha_t} \mathbf{x}_{t-1})^2}{\beta_t} + \frac{(\mathbf{x}_{t-1} - \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_0)^2}{1-\bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_t - \sqrt{\bar{\alpha}_t} \mathbf{x}_0)^2}{1-\bar{\alpha}_t} \big) \Big) \\ &= \exp \Big(-\frac{1}{2} \big(\frac{\mathbf{x}_t^2 - 2\sqrt{\alpha_t} \mathbf{x}_t \color{blue}{\mathbf{x}_{t-1}} \color{black}{+ \alpha_t} \color{red}{\mathbf{x}_{t-1}^2} }{\beta_t} + \frac{ \color{red}{\mathbf{x}_{t-1}^2} \color{black}{- 2 \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_0} \color{blue}{\mathbf{x}_{t-1}} \color{black}{+ \bar{\alpha}_{t-1} \mathbf{x}_0^2} }{1-\bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_t - \sqrt{\bar{\alpha}_t} \mathbf{x}_0)^2}{1-\bar{\alpha}_t} \big) \Big) \\ &= \exp\Big( -\frac{1}{2} \big( \color{red}{(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}})} \mathbf{x}_{t-1}^2 - \color{blue}{(\frac{2\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{2\sqrt{\bar{\alpha}_{t-1}}}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)} \mathbf{x}_{t-1} \color{black}{ + C(\mathbf{x}_t, \mathbf{x}_0) \big) \Big)} \end{aligned}
q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))=exp(−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉt(xt−αˉtx0)2))=exp(−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0)))
其中, C ( x t , x 0 ) C(\mathbf{x}_t, \mathbf{x}_0) C(xt,x0) 是一个不涉及 x t − 1 x_{t-1} xt−1的函数,细节略。按照标准的高斯密度函数,均值和方差可以如下参数化( α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt, α ˉ t = ∏ i = 1 T α i \bar{\alpha}_t = \prod_{i=1}^T \alpha_i αˉt=∏i=1Tαi):
β ~ t = 1 / ( α t β t + 1 1 − α ˉ t − 1 ) = 1 / ( α t − α ˉ t + β t β t ( 1 − α ˉ t − 1 ) ) = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t μ ~ t ( x t , x 0 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) / ( α t β t + 1 1 − α ˉ t − 1 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \begin{aligned} \tilde{\beta}_t &= 1/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) = 1/(\frac{\alpha_t - \bar{\alpha}_t + \beta_t}{\beta_t(1 - \bar{\alpha}_{t-1})}) = \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\ \tilde{\boldsymbol{\mu}}_t (\mathbf{x}_t, \mathbf{x}_0) &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) \\ &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0) \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\ &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \mathbf{x}_0\\ \end{aligned} β~tμ~t(xt,x0)=1/(βtαt+1−αˉt−11)=1/(βt(1−αˉt−1)αt−αˉt+βt)=1−αˉt1−αˉt−1⋅βt=(βtαtxt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11)=(βtαtxt+1−αˉt−1αˉt−1x0)1−αˉt1−αˉt−1⋅βt=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
由于这个很好的性质,我们可以表示
x
0
=
1
α
ˉ
t
(
x
t
−
1
−
α
ˉ
t
z
t
)
\mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\mathbf{z}_t)
x0=αˉt1(xt−1−αˉtzt),代入上述方程得到
μ
~
t
=
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
1
α
ˉ
t
(
x
t
−
1
−
α
ˉ
t
z
t
)
=
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
z
t
)
\begin{aligned} \tilde{\boldsymbol{\mu}}_t &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\mathbf{z}_t) \\ &= \color{cyan}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_t \Big)} \end{aligned}
μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−1−αˉtzt)=αt1(xt−1−αˉtβtzt)
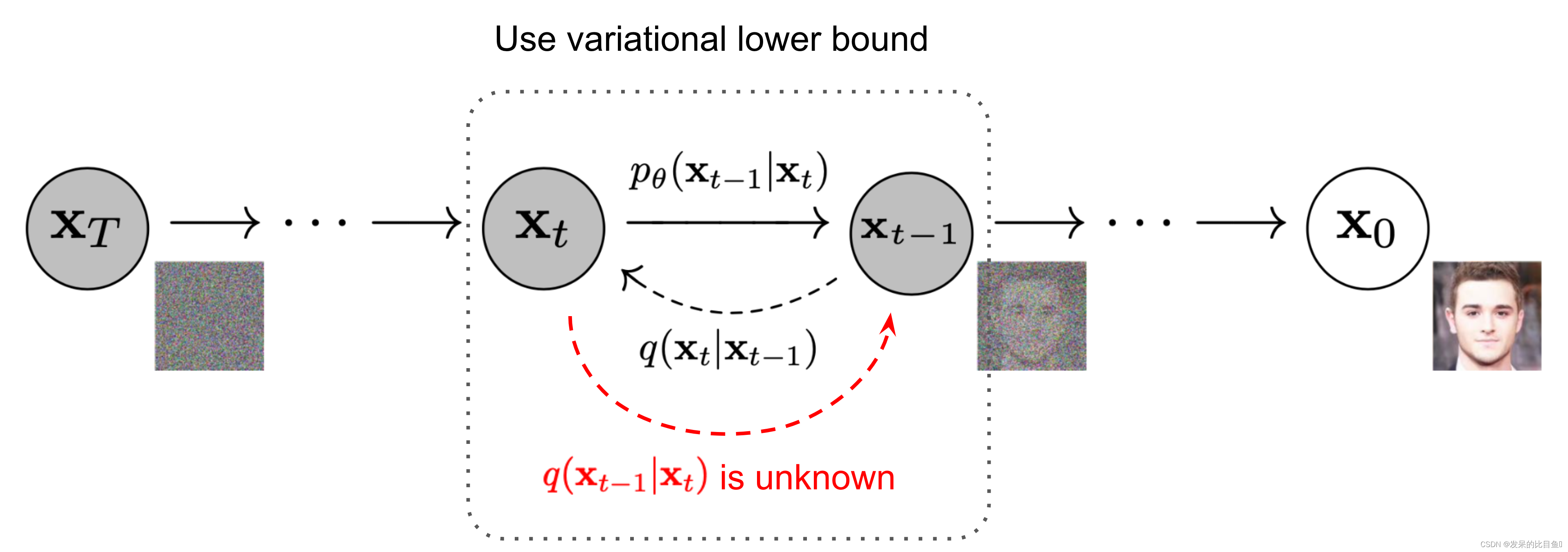
在如图2中。这样的设置与VAE非常相似,因此我们可以使用变分下界来优化负对数似然。
log p θ ( x 0 ) ≤ − log p θ ( x 0 ) + D KL ( q ( x 1 : T ∣ x 0 ) ∥ p θ ( x 1 : T ∣ x 0 ) ) = − log p θ ( x 0 ) + E x 1 : T ∼ q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) / p θ ( x 0 ) ] = − log p θ ( x 0 ) + E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) + log p θ ( x 0 ) ] = E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] Let L VLB = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] ≥ − E q ( x 0 ) log p θ ( x 0 ) \begin{aligned} \log p_\theta(\mathbf{x}_0) &\leq - \log p_\theta(\mathbf{x}_0) + D_\text{KL}(q(\mathbf{x}_{1:T}\vert\mathbf{x}_0) \| p_\theta(\mathbf{x}_{1:T}\vert\mathbf{x}_0) ) \\ &= -\log p_\theta(\mathbf{x}_0) + \mathbb{E}_{\mathbf{x}_{1:T}\sim q(\mathbf{x}_{1:T} \vert \mathbf{x}_0)} \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T}) / p_\theta(\mathbf{x}_0)} \Big] \\ &= -\log p_\theta(\mathbf{x}_0) + \mathbb{E}_q \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} + \log p_\theta(\mathbf{x}_0) \Big] \\ &= \mathbb{E}_q \Big[ \log \frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \\ \text{Let }L_\text{VLB} &= \mathbb{E}_{q(\mathbf{x}_{0:T})} \Big[ \log \frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \geq - \mathbb{E}_{q(\mathbf{x}_0)} \log p_\theta(\mathbf{x}_0) \end{aligned} logpθ(x0)Let LVLB≤−logpθ(x0)+DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))=−logpθ(x0)+Ex1:T∼q(x1:T∣x0)[logpθ(x0:T)/pθ(x0)q(x1:T∣x0)]=−logpθ(x0)+Eq[logpθ(x0:T)q(x1:T∣x0)+logpθ(x0)]=Eq[logpθ(x0:T)q(x1:T∣x0)]=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]≥−Eq(x0)logpθ(x0)
使用詹森不等式也可以直接得到相同的结果。假设我们想要最小化交叉熵作为学习目标:
L
CE
=
−
E
q
(
x
0
)
log
p
θ
(
x
0
)
=
−
E
q
(
x
0
)
log
(
∫
p
θ
(
x
0
:
T
)
d
x
1
:
T
)
=
−
E
q
(
x
0
)
log
(
∫
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
q
(
x
1
:
T
∣
x
0
)
d
x
1
:
T
)
=
−
E
q
(
x
0
)
log
(
E
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
q
(
x
1
:
T
∣
x
0
)
)
≤
−
E
q
(
x
0
:
T
)
log
p
θ
(
x
0
:
T
)
q
(
x
1
:
T
∣
x
0
)
=
E
q
(
x
0
:
T
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
]
=
L
VLB
\begin{aligned} L_\text{CE} &= - \mathbb{E}_{q(\mathbf{x}_0)} \log p_\theta(\mathbf{x}_0) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \int p_\theta(\mathbf{x}_{0:T}) d\mathbf{x}_{1:T} \Big) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \int q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} d\mathbf{x}_{1:T} \Big) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \mathbb{E}_{q(\mathbf{x}_{1:T} \vert \mathbf{x}_0)} \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} \Big) \\ &\leq - \mathbb{E}_{q(\mathbf{x}_{0:T})} \log \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} \\ &= \mathbb{E}_{q(\mathbf{x}_{0:T})}\Big[\log \frac{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})}{p_\theta(\mathbf{x}_{0:T})} \Big] = L_\text{VLB} \end{aligned}
LCE=−Eq(x0)logpθ(x0)=−Eq(x0)log(∫pθ(x0:T)dx1:T)=−Eq(x0)log(∫q(x1:T∣x0)q(x1:T∣x0)pθ(x0:T)dx1:T)=−Eq(x0)log(Eq(x1:T∣x0)q(x1:T∣x0)pθ(x0:T))≤−Eq(x0:T)logq(x1:T∣x0)pθ(x0:T)=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=LVLB
为了将方程中的每一项转化为可解析计算,目标可以进一步改写为几个KL-散度和熵项的组合(Sohl-Dickstein et al., 2015)
L
VLB
=
E
q
(
x
0
:
T
)
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
]
=
E
q
[
log
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
p
θ
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
1
T
log
q
(
x
t
∣
x
t
−
1
)
p
θ
(
x
t
−
1
∣
x
t
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
2
T
log
q
(
x
t
∣
x
t
−
1
)
p
θ
(
x
t
−
1
∣
x
t
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
2
T
log
(
q
(
x
t
−
1
∣
x
t
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
⋅
q
(
x
t
∣
x
0
)
q
(
x
t
−
1
∣
x
0
)
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
2
T
log
q
(
x
t
−
1
∣
x
t
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
+
∑
t
=
2
T
log
q
(
x
t
∣
x
0
)
q
(
x
t
−
1
∣
x
0
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
[
−
log
p
θ
(
x
T
)
+
∑
t
=
2
T
log
q
(
x
t
−
1
∣
x
t
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
+
log
q
(
x
T
∣
x
0
)
q
(
x
1
∣
x
0
)
+
log
q
(
x
1
∣
x
0
)
p
θ
(
x
0
∣
x
1
)
]
=
E
q
[
log
q
(
x
T
∣
x
0
)
p
θ
(
x
T
)
+
∑
t
=
2
T
log
q
(
x
t
−
1
∣
x
t
,
x
0
)
p
θ
(
x
t
−
1
∣
x
t
)
−
log
p
θ
(
x
0
∣
x
1
)
]
=
E
q
[
D
KL
(
q
(
x
T
∣
x
0
)
∥
p
θ
(
x
T
)
)
⏟
L
T
+
∑
t
=
2
T
D
KL
(
q
(
x
t
−
1
∣
x
t
,
x
0
)
∥
p
θ
(
x
t
−
1
∣
x
t
)
)
⏟
L
t
−
1
−
log
p
θ
(
x
0
∣
x
1
)
⏟
L
0
]
\begin{aligned} L_\text{VLB} &= \mathbb{E}_{q(\mathbf{x}_{0:T})} \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \\ &= \mathbb{E}_q \Big[ \log\frac{\prod_{t=1}^T q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{ p_\theta(\mathbf{x}_T) \prod_{t=1}^T p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t) } \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=1}^T \log \frac{q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \log\frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \Big( \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)}\cdot \frac{q(\mathbf{x}_t \vert \mathbf{x}_0)}{q(\mathbf{x}_{t-1}\vert\mathbf{x}_0)} \Big) + \log \frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \sum_{t=2}^T \log \frac{q(\mathbf{x}_t \vert \mathbf{x}_0)}{q(\mathbf{x}_{t-1} \vert \mathbf{x}_0)} + \log\frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \log\frac{q(\mathbf{x}_T \vert \mathbf{x}_0)}{q(\mathbf{x}_1 \vert \mathbf{x}_0)} + \log \frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big]\\ &= \mathbb{E}_q \Big[ \log\frac{q(\mathbf{x}_T \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_T)} + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1) \Big] \\ &= \mathbb{E}_q [\underbrace{D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T))}_{L_T} + \sum_{t=2}^T \underbrace{D_\text{KL}(q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t))}_{L_{t-1}} \underbrace{- \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)}_{L_0} ] \end{aligned}
LVLB=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=Eq[logpθ(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]=Eq[−logpθ(xT)+t=1∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0)⋅q(xt−1∣x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+t=2∑Tlogq(xt−1∣x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+logq(x1∣x0)q(xT∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[logpθ(xT)q(xT∣x0)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)−logpθ(x0∣x1)]=Eq[LT
DKL(q(xT∣x0)∥pθ(xT))+t=2∑TLt−1
DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0
−logpθ(x0∣x1)]
让我们分别标记变分下限损失中的每个分量
L
VLB
=
L
T
+
L
T
−
1
+
⋯
+
L
0
where
L
T
=
D
KL
(
q
(
x
T
∣
x
0
)
∥
p
θ
(
x
T
)
)
L
t
=
D
KL
(
q
(
x
t
∣
x
t
+
1
,
x
0
)
∥
p
θ
(
x
t
∣
x
t
+
1
)
)
for
1
≤
t
≤
T
−
1
L
0
=
−
log
p
θ
(
x
0
∣
x
1
)
\begin{aligned} L_\text{VLB} &= L_T + L_{T-1} + \dots + L_0 \\ \text{where } L_T &= D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T)) \\ L_t &= D_\text{KL}(q(\mathbf{x}_t \vert \mathbf{x}_{t+1}, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_t \vert\mathbf{x}_{t+1})) \text{ for }1 \leq t \leq T-1 \\ L_0 &= - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1) \end{aligned}
LVLBwhere LTLtL0=LT+LT−1+⋯+L0=DKL(q(xT∣x0)∥pθ(xT))=DKL(q(xt∣xt+1,x0)∥pθ(xt∣xt+1)) for 1≤t≤T−1=−logpθ(x0∣x1)
L V L B L_{VLB} LVLB中的每一个KL项(除了 L 0 L_0 L0)比较两个高斯分布,因此它们可以以封闭形式计算。 L T L_T LT是常数,在训练时可以忽略,因为 q q q没有可学习的参数,而 x T x_T xT是高斯噪声。Ho et al. 2020模型 L 0 L_0 L0使用分离的离散解码器导出 N ( x 0 ; μ θ ( x 1 , 1 ) , Σ θ ( x 1 , 1 ) ) \mathcal{N}(\mathbf{x}_0; \boldsymbol{\mu}_\theta(\mathbf{x}_1, 1), \boldsymbol{\Sigma}_\theta(\mathbf{x}_1, 1)) N(x0;μθ(x1,1),Σθ(x1,1))。
训练损失的 L t L_t Lt参数化
回想一下,我们需要学习一个神经网络来近似反向扩散过程中的条件概率分布 p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))我们想训练 μ θ \boldsymbol{\mu}_\theta μθ来预测 μ ~ t = 1 α t ( x t − β t 1 − α ˉ t z t ) \tilde{\boldsymbol{\mu}}_t = \frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_t \Big) μ~t=αt1(xt−1−αˉtβtzt)。因为 x t x_t xt在训练时可用作输入,我们可以重新参数化高斯噪声项,使其在时间步长 t t t时从输入 x t x_t xt预测 z t z_t zt。
μ θ ( x t , t ) = 1 α t ( x t − β t 1 − α ˉ t z θ ( x t , t ) ) 因此 x t − 1 = N ( x t − 1 ; 1 α t ( x t − β t 1 − α ˉ t z θ ( x t , t ) ) , Σ θ ( x t , t ) ) \begin{aligned} \boldsymbol{\mu}_\theta(\mathbf{x}_t, t) &= \color{cyan}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_\theta(\mathbf{x}_t, t) \Big)} \\ \text{因此}\mathbf{x}_{t-1} &= \mathcal{N}(\mathbf{x}_{t-1}; \frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_\theta(\mathbf{x}_t, t) \Big), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) \end{aligned} μθ(xt,t)因此xt−1=αt1(xt−1−αˉtβtzθ(xt,t))=N(xt−1;αt1(xt−1−αˉtβtzθ(xt,t)),Σθ(xt,t))
将损耗项
L
t
L_t
Lt参数化,使
μ
~
\tilde{\boldsymbol{\mu}}
μ~的差值最小化
L
t
=
E
x
0
,
z
[
1
2
∥
Σ
θ
(
x
t
,
t
)
∥
2
2
∥
μ
~
t
(
x
t
,
x
0
)
−
μ
θ
(
x
t
,
t
)
∥
2
]
=
E
x
0
,
z
[
1
2
∥
Σ
θ
∥
2
2
∥
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
z
t
)
−
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
z
θ
(
x
t
,
t
)
)
∥
2
]
=
E
x
0
,
z
[
β
t
2
2
α
t
(
1
−
α
ˉ
t
)
∥
Σ
θ
∥
2
2
∥
z
t
−
z
θ
(
x
t
,
t
)
∥
2
]
=
E
x
0
,
z
[
β
t
2
2
α
t
(
1
−
α
ˉ
t
)
∥
Σ
θ
∥
2
2
∥
z
t
−
z
θ
(
α
ˉ
t
x
0
+
1
−
α
ˉ
t
z
t
,
t
)
∥
2
]
\begin{aligned} L_t &= \mathbb{E}_{\mathbf{x}_0, \mathbf{z}} \Big[\frac{1}{2 \| \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t) \|^2_2} \| \color{blue}{\tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t, \mathbf{x}_0)} - \color{green}{\boldsymbol{\mu}_\theta(\mathbf{x}_t, t)} \|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \mathbf{z}} \Big[\frac{1}{2 \|\boldsymbol{\Sigma}_\theta \|^2_2} \| \color{blue}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \mathbf{z}_t \Big)} - \color{green}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\mathbf{z}}_\theta(\mathbf{x}_t, t) \Big)} \|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \mathbf{z}} \Big[\frac{ \beta_t^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\Sigma}_\theta \|^2_2} \|\mathbf{z}_t - \mathbf{z}_\theta(\mathbf{x}_t, t)\|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \mathbf{z}} \Big[\frac{ \beta_t^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\Sigma}_\theta \|^2_2} \|\mathbf{z}_t - \mathbf{z}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\mathbf{z}_t, t)\|^2 \Big] \end{aligned}
Lt=Ex0,z[2∥Σθ(xt,t)∥221∥μ~t(xt,x0)−μθ(xt,t)∥2]=Ex0,z[2∥Σθ∥221∥αt1(xt−1−αˉtβtzt)−αt1(xt−1−αˉtβtzθ(xt,t))∥2]=Ex0,z[2αt(1−αˉt)∥Σθ∥22βt2∥zt−zθ(xt,t)∥2]=Ex0,z[2αt(1−αˉt)∥Σθ∥22βt2∥zt−zθ(αˉtx0+1−αˉtzt,t)∥2]
简化
从经验上看,Ho et al. (2020)发现训练扩散模型时,忽略加权项的简化目标效果更好
L
t
simple
=
E
x
0
,
z
t
[
∥
z
t
−
z
θ
(
α
ˉ
t
x
0
+
1
−
α
ˉ
t
z
t
,
t
)
∥
2
]
L_t^\text{simple} = \mathbb{E}_{\mathbf{x}_0, \mathbf{z}_t} \Big[\|\mathbf{z}_t - \mathbf{z}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\mathbf{z}_t, t)\|^2 \Big]
Ltsimple=Ex0,zt[∥zt−zθ(αˉtx0+1−αˉtzt,t)∥2]
最后一个简单的目标是
L
simple
=
L
t
simple
+
C
L_\text{simple} = L_t^\text{simple} + C
Lsimple=Ltsimple+C
C
C
C是常数,不依赖于
θ
θ
θ

代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_s_curve
import torch
# Setp1. 加载数据
s_curve, _ = make_s_curve(10**4, noise=0.1)
s_curve = s_curve[:,[0, 2]]/10.0
## 可视化
fig, ax = plt.subplots()
ax.scatter(*data, color="red", edgecolors="white")
ax.axis("off")
dataset = torch.Tensor(s_curve).float()
#Step2 确定超参数的值
num_steps = 100 ## 对于步骤, 一开始可以由beta, 分布的均值和标准差来共同决定
#制定每一步的beta
betas = torch.linspace(-6, 6, num_steps) # 返回一个1维张量,包含在区间start和end上均匀间隔的step个点
betas = torch.sigmoid(betas)*(0.5e-2 - 1e-5) + 1e-5
## 计算alpha, apha_prod, alpha_prod_previous, alpha_bar_sqrt等变量值
alphas = 1-betas
alphas_prod = torch.cumprod(alphas, 0) # 竖着累积
alphas_prod_p = torch.cat([torch.tensor([1]).float(), alphas_prod[:-1]], 0)
## 保证逆扩散过程也是正态的
alphas_bar_sqrt = torch.sqrt(alphas_prod)
one_minus_alphas_bar_log = torch.log(1-alphas_prod)
one_minus_alphas_bar_sqrt = torch.sqrt(1-alphas_prod)
assert alphas.shape==alphas_prod.shape==alphas_prod_p.shape==\
alphas_bar_sqrt.shape==one_minus_alphas_bar_log.shape\
==one_minus_alphas_bar_sqrt.shape
print("all the same shape",betas.shape)
#Step3 确定扩散过程任意时刻的采样值
## 公式:
## $q(x_t|x_0) = N(x_t; \sqrt{\bar{a_t}}x_0, \sqrt{1-\bar{a_t}}I)$
# 计算任意时刻x的采样值,基于x_0和重参数化
def q_x(x_0, t):
"""可以基于x[0]得到任意时刻t的x[t]"""
noise = torch.rand_like(x_0)
alphas_t = alphas_bar_sqrt[t]
alphas_1_m_t = one_minus_alphas_bar_sqrt[t]
return (alphas_t * x_0 + alphas_1_m_t * noise)#在x[0]的基础上添加噪声
# Step4 原始数据分布加噪100步后的结果
num_shows = 20
fig,axs = plt.subplots(2,10,figsize=(28,3))
plt.rc('text',color='black')
#共有10000个点,每个点包含两个坐标
#生成100步以内每隔5步加噪声后的图像
for i in range(num_shows):
j = i//10
k = i%10
q_i = q_x(dataset,torch.tensor([i*num_steps//num_shows]))#生成t时刻的采样数据
axs[j,k].scatter(q_i[:,0],q_i[:,1],color='red',edgecolor='white')
axs[j,k].set_axis_off()
axs[j,k].set_title('$q(\mathbf{x}_{'+str(i*num_steps//num_shows)+'})$')
# Step5 拟合逆扩散过程高斯分布的模型
### 对应$\epsilon_\theta$函数 $\epsilon_\theta(\sqrt{\bar{a_t}}x_0+\sqrt{1-\bar{a_t}}\epsilon, t)$
import torch
import torch.nn as nn
class MLPDiffusion(nn.Module):
def __init__(self, n_steps, num_units=128):
"""
n_steps: 经历多少步
num_units: 中间维度
"""
super().__init__()
self.linears = nn.ModuleList(
[
nn.Linear(2, num_units),
nn.ReLU(),
nn.Linear(num_units, num_units),
nn.ReLU(),
nn.Linear(num_units, num_units),
nn.ReLU(),
nn.Linear(num_units,2),
]
)
self.step_embeddings = nn.ModuleList(
[
nn.Embedding(n_steps, num_units),
nn.Embedding(n_steps, num_units),
nn.Embedding(n_steps, num_units),
]
)
def forward(self,x,t):
# x = x_0
for idx,embedding_layer in enumerate(self.step_embeddings):
t_embedding = embedding_layer(t)
x = self.linears[2*idx](x)
x += t_embedding
x = self.linears[2*idx+1](x)
x = self.linears[-1](x)
return x
# Step6 训练误差函数
## $L(\theta) = E_{t,x_0,\epsilon[||\epsilon-\epsilon_\theta{(\sqrt{\bar{a_t}}x_0+\sqrt{1-\bar{a_t}}\epsilon, t)}||^2]}$
def diffusion_loss_fn(model,
x_0,
alphas_bar_sqrt,
one_minus_alphas_bar_sqrt,
n_steps):
"""对任意时刻t进行采样计算loss"""
batch_size = x_0.shape[0]
#对一个batchsize样本生成随机的时刻t,覆盖到更多不同的t
t = torch.randint(0, n_steps, size=(batch_size//2,))
t = torch.cat([t, n_steps-1-t], dim=0)
t = t.unsqueeze(-1)
#x0的系数
a = alphas_bar_sqrt[t]
#eps的系数
aml = one_minus_alphas_bar_sqrt[t]
#生成随机噪音eps
e = torch.randn_like(x_0)
#构造模型的输入
x = x_0*a+e*aml
#送入模型,得到t时刻的随机噪声预测值
output = model(x,t.squeeze(-1))
#与真实噪声一起计算误差,求平均值
return (e - output).square().mean()
# Step7 逆扩散采样函数(inference)
"""
在DDPM论文中,作者选择了方案【3】,即让$D_{\theta}$网络的输出等于$\epsilon$,预测噪音法。于是,新的逆向条件分布的均值可以表示成(下式中的$\epsilon$相当于我们定义的广义的$D_{\theta}$网络的具体目标形式):
p_sample采样的函数是$\mu_\theta{(x_t, t)}=\tilde{\mu}_t(x_t, \frac{1}{\sqrt{\bar{a_t}}}(x_t-\sqrt{1-\bar{a_t}}\epsilon_{\theta}(x_t)))=\frac{1}{\sqrt{a_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{a_t}}}\epsilon_{\theta}(x_t, t))$
"""
def p_sample_loop(model,
shape,
n_steps,
betas,
ones_minus_alphas_bar_sqrt):
"""从x[T]恢复x[T-1]、x[T-2]|...x[0]"""
cur_x = torch.randn(shape)
x_seq = [cur_x]
for i in reversed(range(n_steps)):
cur_x = p_sample(model,cur_x,i,betas,one_minus_alphas_bar_sqrt)
x_seq.append(cur_x)
return x_seq
def p_sample(model,
x,
t,
betas,
one_minus_alphas_bar_sqrt):
"""从x[T]采样t时刻的重构值"""
t = torch.tensor([t])
coeff = betas[t] / one_minus_alphas_bar_sqrt[t]
eps_theta = model(x, t)
mean = (1/(1-betas[t]).sqrt())*(x-(coeff*eps_theta))
z = torch.randn_like(x)
sigma_t = betas[t].sqrt()
sample = mean + sigma_t * z
return (sample)
# Step8 开始训练模型,打印loss及中间重构效果
seed = 1234
class EMA():
def __init__(self, mu=0.01):
self.mu = mu
self.shadow = {}
def register(self, name, val):
self.shadow[name] = val.clone()
def __call__(self, name, x):
assert name in self.shadow
new_average = self.mu * x + (1.0-self.mu) * self.shadow[name]
self.shadow[name] = new_average.clone()
return new_average
"""
ema = EMA(0.5)
for name , param in model.named_parameters():
if param.requires_grad:
ema.register(name, param.data)
"""
batch_size = 128
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
num_epoch = 4000
plt.rc("text", color="blue")
model = MLPDiffusion(num_steps)#输出维度是2,输入是x和step
optimizer = torch.optim.Adam(model.parameters(),lr=1e-3)
for t in range(num_epoch):
for idx, batch_x in enumerate(dataloader):
loss = diffusion_loss_fn(model,
batch_x,
alphas_bar_sqrt,
one_minus_alphas_bar_sqrt,
num_steps)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.)
optimizer.step()
if(t%100==0):
print(loss)
x_seq = p_sample_loop(model, dataset.shape, num_steps, betas, one_minus_alphas_bar_sqrt)
fig,axs = plt.subplots(1,10,figsize=(28,3))
for i in range(1,11):
cur_x = x_seq[i*10].detach()
axs[i-1].scatter(cur_x[:,0],cur_x[:,1],color='red',edgecolor='white');
axs[i-1].set_axis_off();
axs[i-1].set_title('$q(\mathbf{x}_{'+str(i*10)+'})$')
参考
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/

















 6695
6695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









