






四 检索优化
在前面获得查询引擎和向量索引后,接下来可以考虑如何优化检索结果。
前面提到检索器的构建比较简单,也没太多自定义选项。但对检索结果的优化却有多种方案, 整体可划分为检索前优化和检索后优化。
- 检索前处理(Pre-Retrieval):检索前处理通常用于完成诸如查询转换、查询扩充、检索路由等处理工作,其目的是为后面的检索与检索后处理做必要准备,以提高检索阶段召回知识的精确度与最终生成的质量。
- 检索后处理(Post-Retrieval):与检索前处理相对应,这是在完成检索后对检索出的相关知识块做必要补充处理的阶段。比如,对检索的结果借助更专业的排序模型与算法进行重排序或者过滤掉一些不符合条件的知识块等,使得最需要、最合规的知识块处于上下文的最前端,这有助于提高大模型的输出。
质量。
(一)中描述的架构,top agents也可归类为一种检索前优化,即对检索工具进行分发,让它们去调用tool agent完成相应检索。
(一)中描述的架构,更准确地说是一种对多文档知识库的检索架构。
4.1 检索前处理
在后端后端 Agent 模块中,通过两级的 Agent 之间的配合,结合底层的 RAG 查询引擎来完成更复杂的知识型任务。这种分层检索,由于其在技术上通常通过递归的形式来完成,因此也称为递归检索。
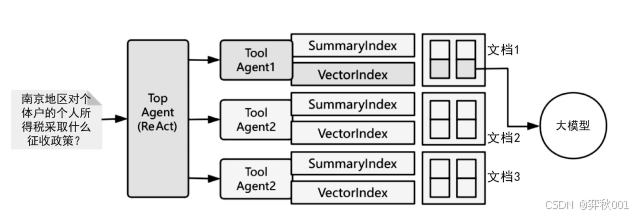
(1)为每一个文档或知识库都创建一个知识 Agent ( 这里称作 Tool Agent)。这个 Agent 的能力是可以使用一个或者多个 RAG 查询引擎来回答问题。
(2)在多个知识 Agent 之上创建一个语义路由的 Agent(这里称作 Top Agent),这个 Agent 会借助推理功能使用后端的知识 Agent 完成查询任务。
多个 Tool Agent 可以通过协作完成联合型任务。比如,对比与汇总两个不同文档中的知识,这也是经典的问答型 RAG 应用无法完成的任务。
4.2 检索后处理
后处理主要是对检索出的节点 Node 进行转换、过滤或者重排序等操作,会影响RAG准确率与召回精度。这里我使用融合检索器来完成。
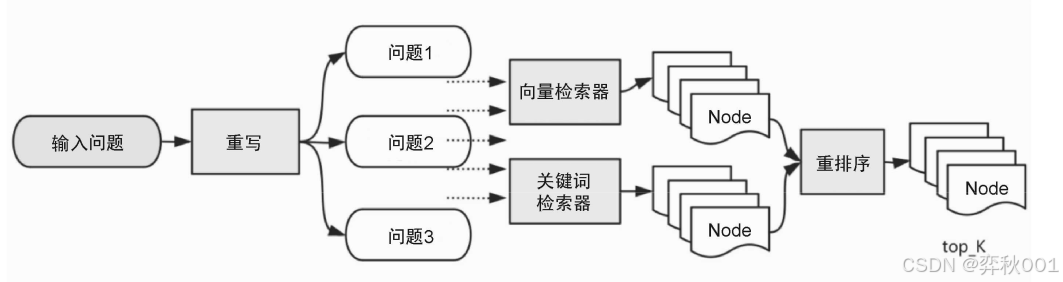
融合检索器是通过多个不同的检索方法进行检索,并对检索的结果使用 RRF 算法(或其他算法)重排序后输出,它可以组合多个不同的输入问题或者不同类型索引的检索结果,以弥补单个索引在检索精确性上的不足。融合检索器包括检索后处理外的其他模块,不过仍然可以作为后处理模块来使用。
4.3 主要代码展示
- 使用官方已封装好的融合检索器,作为当前模块的引擎。
class FusionRetriever2:
def __init__(self, retrievers,retriever_llm, similarity_top_k=3, num_queries=4):
# 两个检索器
# vector_retriever = create_vector_index_retriever('南京市')
# kw_retriever = create_kw_index_retriever('南京市')
# QueryFusionRetriever封装全面,有子问题转换器, mode是只融合检索后方法排序方法
# 可以为当前融合检索指定大模型,否则使用全局模型
fusion_retriever = QueryFusionRetriever(
retrievers=retrievers, # [vector_retriever,kw_retriever]
llm=retriever_llm,
similarity_top_k=similarity_top_k,
num_queries=num_queries, # set this to 1 to disable query generation
mode=FUSION_MODES.RECIPROCAL_RANK, # "reciprocal_rerank",
use_async=True,
verbose=True
)
# 查询引擎,不再外面暴露
self._query_engine = RetrieverQueryEngine(fusion_retriever)
def query(self, query_question: str):
return self._query_engine.query(query_question)
整合之前创建的所有组件,融入当前架构中, 这里使用向量存储索引和关键词索引组成的融合检索替代VectorIndex, 实现更全面的内容检索及对检索内容的重排序:
# -*- coding: utf-8 -*-
# @Time : 2025/2/19 下午2:23
# @Author : yblir
# @File : legal_rag.py
# explain :
# =======================================================
from llama_index.core import Settings
from llama_index.core.callbacks import CallbackManager
from llama_index.embeddings.ollama import OllamaEmbedding
from pathlib2 import Path
from custom_components import CustomVllmLLM, CustomSynthesizer
from custom_query_engine import OnceQueryEngine, ChatQueryEngine
from data_and_index import VectorIndex
from query_agents import create_tool_agent, create_top_agent
from fusion_retriever import FusionRetriever2
import nltk
Settings.embed_model = OllamaEmbedding(model_name="milkey/dmeta-embedding-zh:f16")
nltk.data.path.append('/mnt/e/PyCharm/PreTrainModel/nltk_data')
class LegalRAG:
def __init__(self, llm_path):
# 自定义大模型
self.custom_model = CustomVllmLLM(llm_path)
# 自定义响应器
self.custom_synthesizer = CustomSynthesizer(self.custom_model)
# 从文件构建索引,并保存
self.index = VectorIndex()
self.callback_manager = CallbackManager()
def top_agent(self, file_paths: str):
agents = {}
for file_path in Path(file_paths).rglob('*'):
file_name = file_path.stem
file_path = str(file_path)
# 自定义查询引擎, 构建单次对话向量查询引擎
# 使用融合检索引擎
vector_index = self.index.create_vector_index(file_path)
# vector_engine = OnceQueryEngine(
# vector_index.as_retriever(similarity_top_k=5),
# self.custom_model
# )
kw_index = self.index.create_keyword_index(file_path)
fusion_retriever_engine = FusionRetriever2(
retrievers=[vector_index.as_retriever(), kw_index.as_retriever()],
retriever_llm=self.custom_model,
)
# 构建语义检索引擎, 这里使用直接构建的方式, 使用自定义的大模型
summary_index = self.index.create_summary_index(
file_path,
self.custom_model
)
summary_engine = summary_index.as_query_engine(
llm=self.custom_model,
response_mode="tree_summarize"
)
# 构建工具agent
tool_agent = create_tool_agent(
# query_engine=vector_engine,
query_engine=fusion_retriever_engine,
summary_engine=summary_engine,
name=file_name,
agent_llm=self.custom_model,
)
agents[file_name] = tool_agent
top_agent_ = create_top_agent(
agents,
self.callback_manager,
agent_llm=self.custom_model
)
return top_agent_
if __name__ == '__main__':
rag = LegalRAG('/media/xk/D6B8A862B8A8433B/data/qwen2_05b')
top_agent = rag.top_agent('/home/xk/PycharmProjects/llamaindexProjects/falv_rag/data')
# rag = LegalRAG('/mnt/e/PyCharm/PreTrainModel/qwen2_05b')
# rag = LegalRAG('/mnt/e/PyCharm/PreTrainModel/qwen2_7b_instruct_awq_int4')
# top_agent = rag.top_agent('../data')
# rag = LegalRAG(r'E:\PyCharm\PreTrainModel\qwen_7b_chat_int4')
# top_agent = rag.top_agent('../data')
res = top_agent.streaming_chat_repl()
# print(res)
# print('333')

















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









