







 文章详细介绍了DETR中多尺度可变形注意力的设计,包括其公式解释,如何通过减少query与所有key的计算来降低计算量,以及单尺度和多尺度特征融合的过程。
文章详细介绍了DETR中多尺度可变形注意力的设计,包括其公式解释,如何通过减少query与所有key的计算来降低计算量,以及单尺度和多尺度特征融合的过程。
原理大家可以参考这篇文章,我这边主要介绍几个公式和整体源码理解。
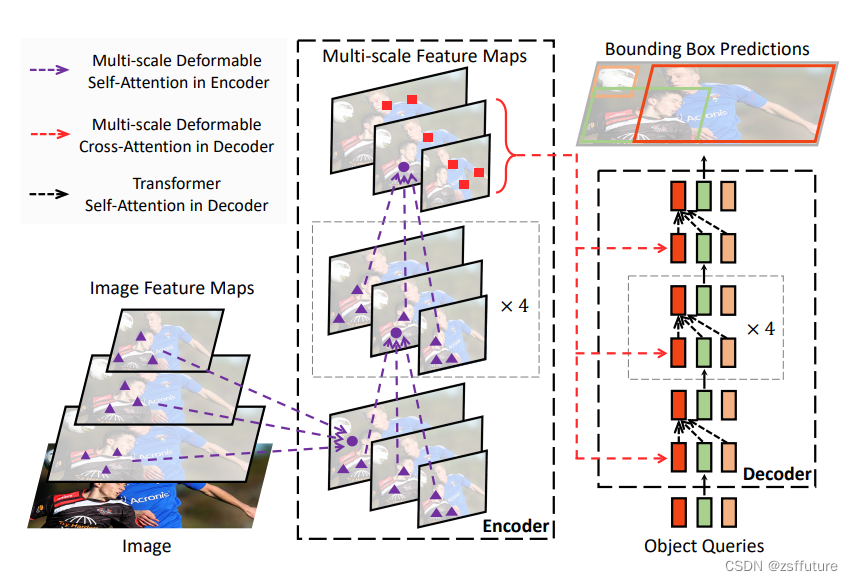
- 提出了多尺度可变形注意力(Multi-scale Deformable Attention, MSDA).基于此设计了 DETR 特有的利用多尺度特征检测的流程,对之后的很多工作有指导意义。
- 提出了两阶段 DETR 的思路,利用编码器输出特征来初始化解码器的 query及其对应的位置。
- 最早提出在解码器层之间优化 query对应位置的思路(iterative box refinement)
公式理解
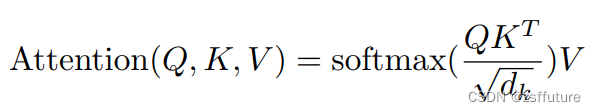

其实大家看到最多的注意力公式是第一个,第一个是针对一句话或者一个通道或者一张图片而言,即Q代表所有的query,K代表所有的键key,V代表所有的value,但是对于DeformableDETR他们的公式也是类似的,只是他针对的是一个query进行描述了注意力机制,这是从单个query的角度进行描述
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









