







原理大家参考这篇文章,我主要是根据自己的理解和整个流程图以及代码进行对应,这样更有利于深入理解:
下图是解码器结构图,编码器没动和deter一样的
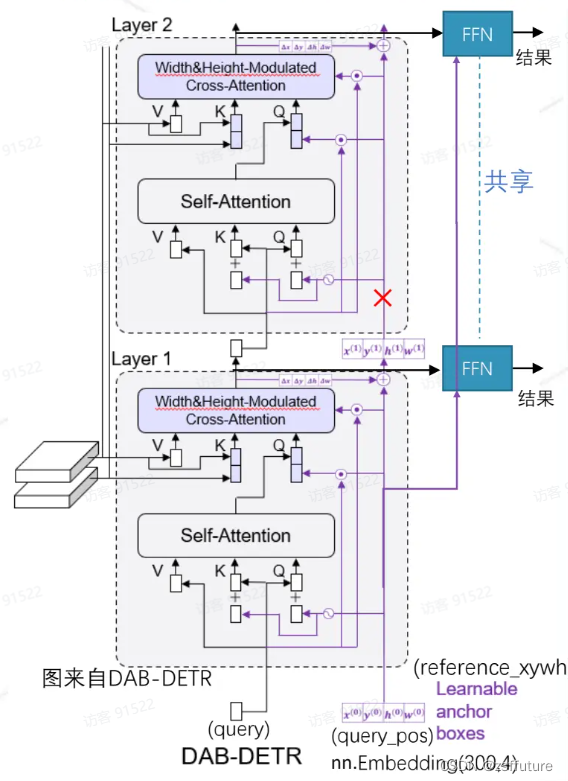
这张图片基本上说清了模型的结构和传递过程,红色×代表切断梯度反向传播,每层都会进行单独的反向传播,这里需要几点特别注意:
从下往上看
1. 解码器的自注意力层输入Q仍然有两部分构成query 和query_pose,正常的query的shape是[batch,300,256],query_pose的shape是[batch,300,4], 而且query初始化任然全为0向量,而query_pose是可学习的,因为作为输入都是向量,而query_pose是坐标,因此需要通过位置编码把坐标编码为向量即shape由[batch,300,4]->[batch,300,256],然后二者就可以相加作为Q了。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









