







 本文通过实例探讨了深度学习中的过拟合问题,包括过拟合的表现、原因及解决方法。首先介绍了过拟合的特征,即训练集上表现优秀但测试集上预测准确性低。接着,通过 Dropout 抑制过拟合,解释了 Dropout 的工作原理,并展示了其在训练和测试准确率上的改善效果。此外,还提到了 L2 正则化作为另一种抑制过拟合的手段。最后,总结了网络参数选择的总原则,强调在避免欠拟合和过拟合之间找到平衡的重要性。
本文通过实例探讨了深度学习中的过拟合问题,包括过拟合的表现、原因及解决方法。首先介绍了过拟合的特征,即训练集上表现优秀但测试集上预测准确性低。接着,通过 Dropout 抑制过拟合,解释了 Dropout 的工作原理,并展示了其在训练和测试准确率上的改善效果。此外,还提到了 L2 正则化作为另一种抑制过拟合的手段。最后,总结了网络参数选择的总原则,强调在避免欠拟合和过拟合之间找到平衡的重要性。
过拟合实例
import keras
from keras import layers
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv('./Desktop/Keras/Data/credit-a.csv', header=None)#该数据没有columns即头部,为避免将第一行当作头部标签所以加上header=None
- 未加header=None
data.head()

- 加header=None
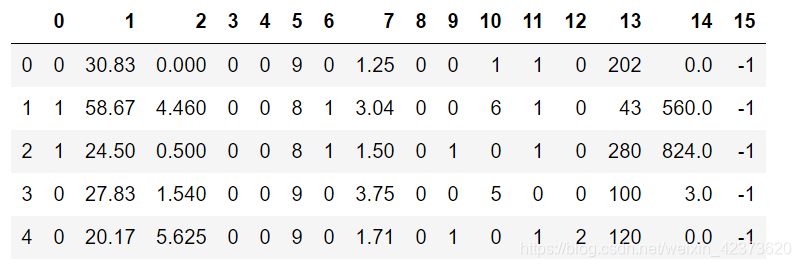
0—14是特征,最后一列是预测目标
data.iloc[:, -1].unique()##查看目标种类,是二元分类
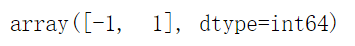
取出x,y
x = data.iloc[:, :-1].values #取出前15列
##取出数值为ndarray形式,之前为DataFrame形式,Keras都可以接受
x

##y = data.iloc[: , -1].values.reshape(-1, 1)
y = data.iloc[: , -1].replace(-1, 0).values.reshape(-1, 1)
##取出value,并将653个数据reshape为每个数据维度为1.reshape(-1,1)中-1是自动计算的意思,第二个1是维度为1
y
因为sigmoid输出是在(0,1)之间,因此我们需要将y中数据-1替换为0,所以用了replace(-1,0)
y.shape, x.shape
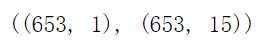
y中有653个长度为1的数据,x中有653个长度为15的数据
model = keras.Sequential()
model.add(layers.Dense(128, input_dim=15, activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()

隐藏层3层,有35201个参数训练
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
history = model.fit(x, y, epochs=1000)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1410
1410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









