






 本文详细介绍了在CentOS7环境下安装ClickHouse的过程,包括使用yum安装、启动服务、修改用户和密码以及配置监听非本机IP。还探讨了ClickHouse的列式存储优势、SQL支持、高吞吐写入能力、数据分区与并行处理,以及其在OLAP场景中的应用。此外,文章还展示了如何使用Python连接ClickHouse进行建表和数据写入。
本文详细介绍了在CentOS7环境下安装ClickHouse的过程,包括使用yum安装、启动服务、修改用户和密码以及配置监听非本机IP。还探讨了ClickHouse的列式存储优势、SQL支持、高吞吐写入能力、数据分区与并行处理,以及其在OLAP场景中的应用。此外,文章还展示了如何使用Python连接ClickHouse进行建表和数据写入。
1.环境准备
1.1 联网VM虚拟机centos7
1.2 yum可用
2.安装clickhouse
2.1 查看yum 安装包
yum list |grep clickhouse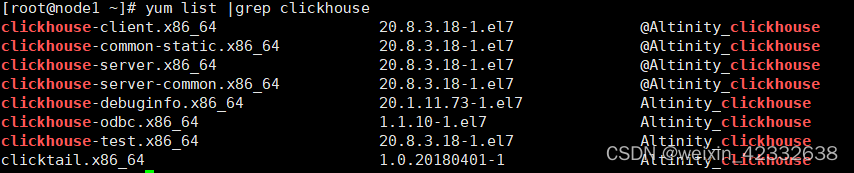
2.2 yum 安装clickhouse
yum install clickhouse-server
yum install clickhouse-client2.3 启动clickhouse服务
--service clickhouse-server status
systemctl status clickhouse-server.service
## 查看clickhouse服务端状态
--service clickhouse-server start
systemctl start clickhouse-server.service
## 启动clickhouse服务2.4 登录clickhouse
clickhouse-client此时没有给数据库配置用户名和密码 ,默认登录参数--host=localhost --user=default --password=空,可以直接登录
2.5 修改用户名和密码,配置监听非本机ip
停止clickhouse 服务
systemctl stop clickhouse-server.service修改配置文件 /etc/clickhouse-server/config.xml 配置监听所有端口
vi /etc/clickhouse-server/config.xml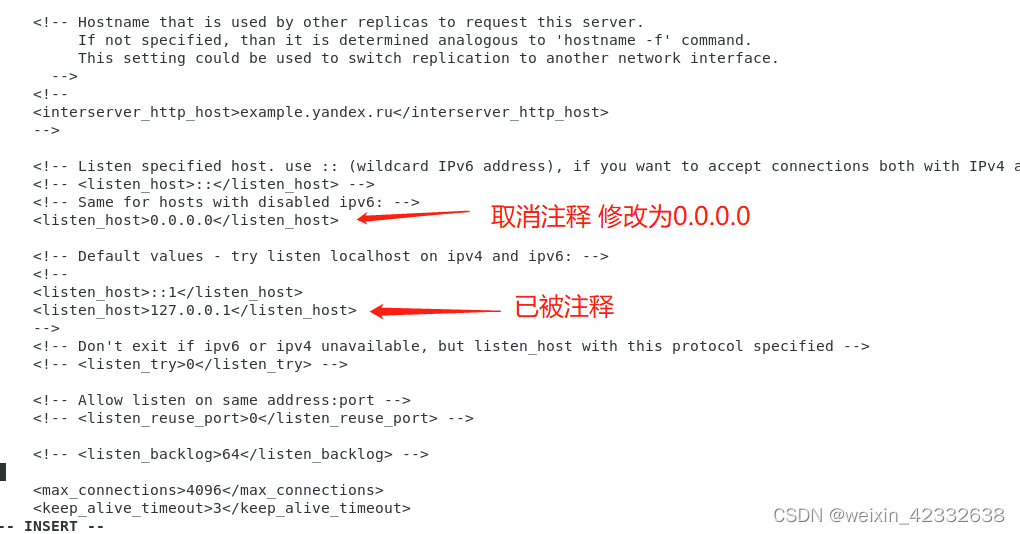
修改配置 /etc/clickhouse-server/users.xml 配置用户名和密码

重新启动clickhouse-server
systemctl start clickhouse-server.service
输入
clickhouse-client --host=127.0.0.1 --user=default --password=666666
登录成功。
3.clickhouse 简介
3.1 简介
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的用于在线分析处理查询(OLAP :Online Analytical Processing)MPP架构的列式存储数据库(DBMS:Database Management System),能够使用 SQL 查询实时生成分析数据报告。ClickHouse的全称是Click Stream,Data WareHouse。
clickhouse可以做用户行为分析,流批一体
线性扩展和可靠性保障能够原生支持 shard + replication
clickhouse没有走hadoop生态,采用 Local attached storage 作为存储
3.2 特点
3.2.1 列式存储:
行式存储的好处:
想查找某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以;但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
列式存储的好处
- 对于列的聚合、计数、求和等统计操作优于行式存储
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重
- 数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间
- 列式存储不支持事务
3.2.2 DBMS功能:
几乎覆盖了标准 SQL 的大部分语法,包括 DDL 和 DML、以及配套的各种函数;用户管理及权限管理、数据的备份与恢复
3.2.3 多样化引擎:
目前包括合并树、日志、接口和其他四大类20多种引擎。
3.2.4 高吞吐写入能力:
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类 LSM tree的结构, ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力。
3.2.5 数据分区与线程及并行:
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity(索引粒度),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下, 单条 Query 就能利用整机所有 CPU。 极致的并行处理能力,极大的降低了查询延时。
所以, ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务并不是强项。
3.2.6 OLAP特性
ClickHouse 像很多 OLAP 数据库一样,单表查询速度优于关联查询,而且 ClickHouse的两者差距更为明显。
关联查询:clickhouse会将右表加载到内存。
3.2.7 优缺点
优点

缺点

3.2.8 clickhouse为什么快
- C++可以利用硬件优势
- 摒弃了hadoop生态
- 数据底层以列式存储
- 利用单节点的多核并行处理
- 为数据建立索引一级、二级、稀疏索引
- 使用大量的算法处理数据
- 支持向量化处理
- 预先设计运算模型-预先计算
- 分布式处理数据
3.2.9 clickhouse数据库和表的基本概念
- 分片:ClickHouse的集群由分片 ( Shard ) 组成,而每个分片又通过副本 ( Replica ) 组成。ClickHouse的1个节点只能拥有1个分片。
- 分区 :ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区。
- 副本:数据存储副本,在集群模式下实现高可用。
- 引擎:不同的引擎决定了表数据的存储特点和表数的操作行为。
clickhouse 5种数据库引擎
- ·Ordinary:默认引擎,在绝大多数情况下我们都会使用默认引擎,使用时无须刻意声明。在此数据库下可以使用任意类型的表引擎
- ·Dictionary:字典引擎,此类数据库会自动为所有数据字典创建它们的数据表。
- ·Memory:内存引擎,用于存放临时数据。此类数据库下的数据表只会停留在内存中,不会涉及任何磁盘操作,当服务重启后数据会被清除。
- ·Lazy:日志引擎,此类数据库下只能使用Log系列的表引擎。
- ·MySQL:MySQL引擎,此类数据库下会自动拉取远端MySQL中的数据,并为它们创建MySQL表引擎的数据表。

3.2.10 clickhouse数据类型
1.数值类型
1.1 Int 整数
| ClickHouse | 关系型数据库 | 字节数 | 范围 |
| Int8 | TinyInt | 1 | -2^7到2^7-1 |
| Int16 | SmallInt | 2 | -2^15到2^15-1 |
| Int32 | Int | 4 | -2^31到2^31-1 |
| Int64 | BigInt | 8 | -2^63到2^63-1 |
| Uint8 | TinyInt正整数 | 1 | 0到2^8-1 |
| UInt16 | SmallInt正整数 | 2 | 0到2^16-1 |
| UInt32 | Int正整数 | 4 | 0到2^32-1 |
| UInt64 | BigInt正整数 | 8 | 0到2^64-1 |
1.2 float 小数
| ClickHouse | 精度 | 字节数 |
|---|---|---|
| Float32 | 7位 | 4 |
| Float64 | 16位 | 8 |
1.3 decimal
| ClickHouse | 原生写法 | 简写 |
| Decimal32 | Decimal32(P,S) | Decimal32(S),等效于Decimal(1~9,S) |
| Decimal64 | Decimal64(P,S) | Decimal64(S),等效于Decimal(10~18,S) |
| Decimal128 | Decimal128(P,S) | Decimal128(S),等效于Decimal(19~38,S) |
P代表精度,决定总位数(整数部分+⼩数部分),取值范围是1~38。
S代表规模,决定⼩数位数,取值范围是0~P。
1.4 string
1.4.1 String
字符串由 String 定义,长度不限,因为在使用 String 的时候无需声明大小。它完全代替了传统意义上的 Varchar、Text、Clob 和 Blob 等字符类型。String 类型不限定字符集,因为它根本没有这个概念,所以可以将任意编码的字符串存入其中。但是为了程序的规范性和可维护性,在同一套程序中使用统一的编码,比如 utf-8,就是一种很好的约定。
1.4.2 FiexedString
FixedString 类型和传统意义上的 Char 类型有些类似,对于一些有着明确长度的场合,可以使用 FixedString(N) 来声明固定长度的字符串。但与 char 不同的是,FixedString 使用 NULL 字节来填充末尾字符,而 char 通常使用空格填充。
可以使用 toFixedString 生成 FixedString。
1.4.3 UUID
UUID 是一种数据库常见的主键类型,在 ClickHouse 中直接把它作为一种数据类型。UUID 共有 32 位,它的格式为 8-4-4-4-12。如果一个 UUID 类型的字段在写入数据的时候没有被赋值,那么它会按照相应格式用 0 填充。
1.5 时间
1.5.1 DateTime
DateTime类型包含时、分、秒信息,精确到秒,支持使用字符串形式写入:
CREATE TABLE Datetime_TEST (c1 Datetime) ENGINE = Memory;
--以字符串形式写入
INSERT INTO Datetime_TEST VALUES('2019-06-22 00:00:00');
SELECT c1, toTypeName(c1) FROM Datetime_TEST;
┌──────────────────c1─┬─toTypeName(c1)─┐
│ 2019-06-22 00:00:00 │ DateTime │
└─────────────────────┴────────────────┘1.5.2 DateTime64
DateTime64可以记录亚秒,它在DateTime之上增加了精度的设置
1.5.3 Date
Date类型不包含具体的时间信息,只精确到天,它同样也支持字符串形式写入
CREATE TABLE Date_TEST (c1 Date) ENGINE = Memory;
INSERT INTO Date_TEST VALUES('2019-06-22');
SELECT c1, toTypeName(c1) FROM Date_TEST;
┌─────────c1─┬─toTypeName(c1)─┐
│ 2019-06-22 │ Date │
└────────────┴────────────────┘1.6 复杂类型
复杂类型分为Array数组、Enum枚举、Tuple元组、Nested嵌套四类
4. python连接clickhouse 建表写入数据
pip install clickhouse-dirverpython通过tcp与clickhouse建立通信
clickhouse默认 http连接端口8123
clickhouse默认 TCP连接端口9000
可以通过 /etc/clickhouse-server/config.xml 修改配置
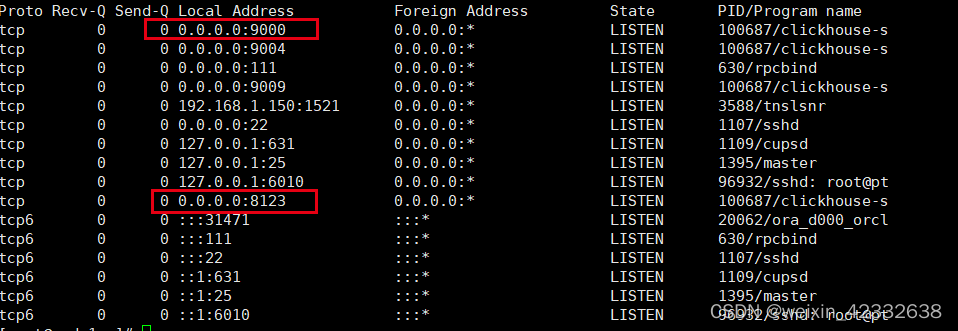
python连接建表写数据:
4.1 建表写数
# -*- coding: utf-8 -*-
import clickhouse_driver
conn = clickhouse_driver.connect(host='192.168.1.150', database='default', user='default', password='******', port='9000')
# conn.close()
cur = conn.cursor()
cur.execute('show tables')
print(cur.fetchall())
sql1 = 'create table if not exists tb_test(id Int8 ,name String) engine=Memory'
cur.execute(sql1)
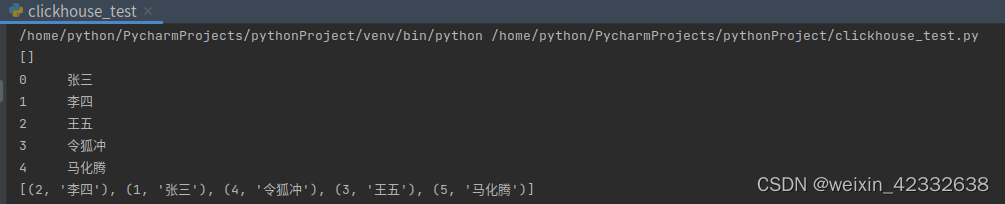
a = ['张三', '李四', '王五', '令狐冲', '马化腾']
cur.execute('truncate table tb_test')
# 清空后给表tb_test写入数据 这里应该也可以用数组一次性sql写入
for i in range(len(a)):
print(i, ' ', a[i])
sql_insert = "insert into tb_test values({0},'{1}')".format(i+1, a[i])
try:
cur.execute(sql_insert)
conn.commit()
except Exception as e:
print(e)
sql_select = 'select * from tb_test'
cur.execute(sql_select)
print(cur.fetchall())
4.2 UUID字符测试
# uuid
print('*'*100)
sql2 = 'CREATE TABLE if not exists uuid_test(c1 UUID, c2 String) ENGINE = Memory'
cur.execute(sql2)
cur.execute('show tables')
print(cur.fetchall())
cur.execute("truncate table uuid_test")
try:
cur.execute("insert into uuid_test select generateUUIDv4(),'row1'")
cur.execute("insert into uuid_test(c2) select 'row2'")
cur.execute("select * from uuid_test")
for i in cur.fetchall():
print(i)
except Exception as e1:
print(e1)
4.3 datetime字符类型测试
# datetime
print('*'*100)
sql3 = "CREATE TABLE if not exists datetime_test1 (c1 Datetime) ENGINE = Memory"
cur.execute(sql3)
cur.execute('show tables')
print(cur.fetchall())
cur.execute("truncate table datetime_test1")
try:
cur.execute("insert into datetime_test1 values (toDateTime('2022-09-16 21:21:55'))")
cur.execute("insert into datetime_test1 values (toDateTime('2022-08-20 01:05:33'))")
cur.execute("select * from datetime_test1")
for i in cur.fetchall():
print(i)
except Exception as e2:
print(e2)
4.4 array数组
# array数组
print('*'*100)
sql4 = "create table if not exists test_array(name String ,hobby Array(String)) engine=Log"
cur.execute(sql4)
cur.execute('show tables')
print(cur.fetchall())
cur.execute("truncate table test_array")
try:
cur.execute("insert into test_array values('于谦',['抽烟','喝酒','烫头'])")
cur.execute("insert into test_array values('班长',['抽烟','于谦'])")
cur.execute("select * from test_array")
for i in cur.fetchall():
print(i)
except Exception as e3:
print(e3)
4.5 tuple元组
# tuple元组
print('*'*100)
sql5 = "create table if not exists test_tuple(name String ,info Tuple(String,String,UInt8))engine=Memory"
cur.execute(sql5)
cur.execute('show tables')
print(cur.fetchall())
cur.execute("truncate table test_tuple")
try:
cur.execute("insert into test_tuple values('于谦', ('男','班长',22))")
cur.execute("insert into test_tuple values('zss',('M','coder',23)),('lss',('F','coder',33))")
cur.execute("select * from test_tuple")
for i in cur.fetchall():
print(i)
except Exception as e4:
print(e4)

4.6 enum枚举类型
# enum枚举类型
print('*'*100)
sql6 = "create table if not exists test_enum(id UInt8 ,color Enum('RED'=1,'GREEN'=2 ,'BLUE'=3))engine=Memory"
cur.execute(sql6)
cur.execute('show tables')
print(cur.fetchall())
cur.execute("truncate table test_enum")
try:
cur.execute("insert into test_enum values(1,'RED')")
cur.execute("insert into test_enum values(2,'GREEN'),(3,'BLUE')")
cur.execute("insert into test_enum values(5,'BLUE')")
cur.execute("insert into test_enum values(6,1)") # 可以用数字替代red 写入数据
cur.execute("select * from test_enum")
for i in cur.fetchall():
print(i)
except Exception as e5:
print(e5)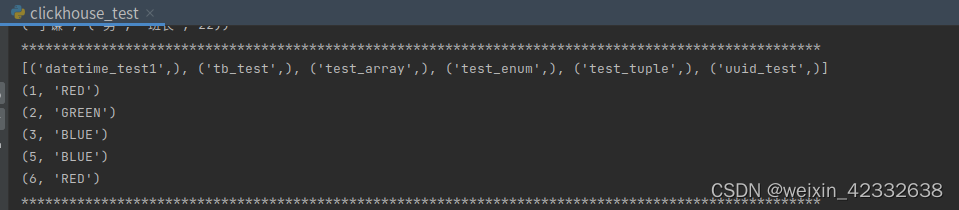
4.7 Nested嵌套类型
# Nested嵌套类型
print('*'*100)
sql6 = "create table if not exists test_nested(uid Int8 ,name String ,hobby Nested(id Int8 ,hname1 String ,hname2 String))engine=Memory"
cur.execute(sql6)
cur.execute('show tables')
print(cur.fetchall())
cur.execute("truncate table test_nested")
try:
cur.execute("insert into test_nested values (1,'aaa',[1,2,3],['吃','喝','睡'],['eat','drink','sleep'])")
cur.execute("insert into test_nested values (2,'bbb',[1,2],['吃','喝'],['eat','drink'])")
cur.execute("insert into test_nested values (3,'ccc',[1],['吃'],['eat'])")
cur.execute("insert into test_nested values (4,'dddd',[1,2,4],['吃','喝','玩'],['eat','drink','play'])")
cur.execute("select * from test_nested")
for i in cur.fetchall():
print(i)
except Exception as e5:
print(e5)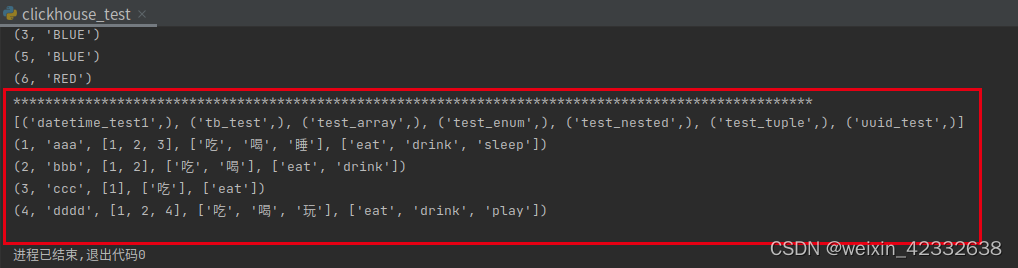
完

















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









