



为了防止一次加载太多数据到内存,对内存占用和IO读取开销太大,一般使用limit 关键字进行分页加载数据。
查询employess表中第[N,N+m]条记录,先看下测试数据集大小
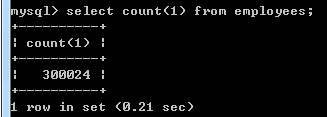
分别查询[10000,10003]三条记录和[100000,100003]三条记录,并观察执行时间。
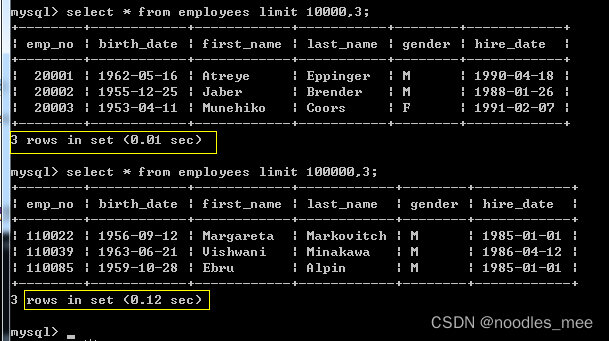
那么到底是什么原因导致limit 10000,3 和limit 100000,3性能差距那么大的呢?
- 根本原因在于:对于limit的操作,innodb是扫描足够的行记录,然后返回给server层。然后server层再根据offset抛弃掉对应数量的行记录。
- 例如:limit 10000,3。
- innodb根据相应条件获取到10000+3行记录,然后返回给server层。
- 然后server层抛弃掉前10000条记录。
- 所以,性能差距大,那是因为获取行记录的数量大所导致的!
优化方案
普通查询
在employees表中,emp_no是主键,也即聚集索引,在birth_date列创建一个普通非聚集索引。
mysql> select * from employees
where birth_date > '1955-01-01'
order by emp_no
limit 100000,3;
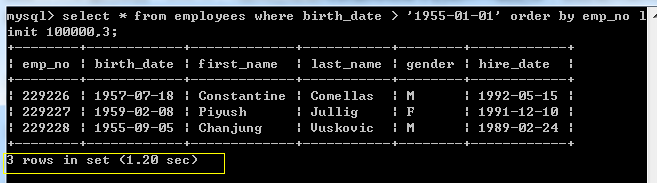
查询过程:
- 通过非聚簇索引找到对应数据的id。(100000+3条)
- 再回表,根据id查找对应数据。
- 丢掉前100000条,保留后面3条。
优化方案1(通过子查询优化)
mysql> select * from employees
where emp_no >=
(select emp_no from employees
where birth_date > '1955-01-01'
order by emp_no limit 100000,1)
limit 3;
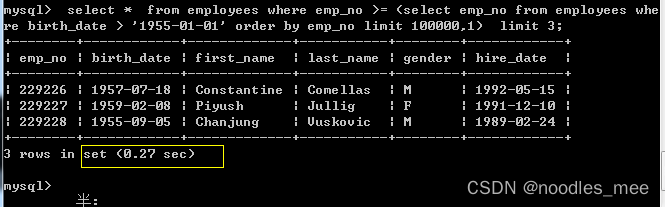
查询过程:
- 先进行子查询,通过非聚簇索引找到对应的id。(此时,查出100000+1条返回给server层,然后server层扔掉前100000条。只保留了1个id。子查询可以优化的原因是:只返回了id这一列,而不是返回你查询的数据。因此,所消耗的资源和时间并不会那么大!)
- 再根据主键,找到符合条件的那3条记录。
上面是基于主键查询的流程分析,如果非主键,基于索引的流程是怎么样的呢?(假设:limit a,b)
- 先通过索引查找a+b条记录所对应的id。
- 然后后面的步骤就和上面主键查询的流程一致了。
也就是说非主键索引的limit过程,比主键索引的limit过程,多了个回表的消耗。
优化方案2(使用inner join优化)
mysql> select e1.* from employees e1
inner join
(select emp_no from employees
where birth_date > '1955-01-01'
order by emp_no limit 100000,3) as e2
on e2.emp_no=e1.emp_no;
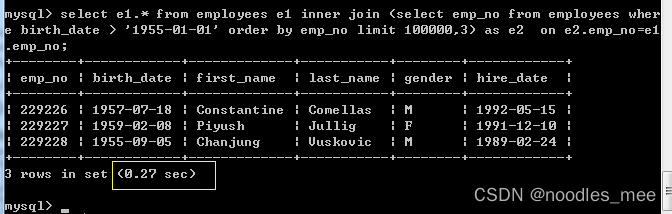
原理:与基于子查询的优化方式类似,只不过是换了一种形式。
其他
和产品谈论一下,这么多的翻页(几十万)是否有必要且合理呢?用户是否真的会一页页翻下去呢?
如果在产品上可以做出限制,例如:只允许翻页前1千条。后面的只能记录只能通过下一页的形式来查询,这样子会不会更好呢。
(Google搜索中只允许滚动翻页了!即:只能下一页。抖音也是这样,滑动一个个视频,不也是”下一页“的一种体现吗?)
补充:如果只支持下一页的时候,可以让前端直接传这一页最大的主键id。我们直接通过这个主键id作为条件进行过滤,效率会更高哦!

















 8487
8487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









