






基于NNLM的词向量训练
通过NNLM训练词向量
一、语料库

二、完整代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
dtype = torch.FloatTensor
sentence = ["i like dog","i love coffee","i hate milk"]
word_list = " ".join(sentence).split()#根据空格分单词
word_list = list(set(word_list))#用set去除重复的词
word_dict = {w:i for i,w in enumerate(word_list)}#给word一个id
#{'i': 0, 'like': 1, 'dog': 2, 'coffee': 3, 'hate': 4, 'milk': 5, 'love': 6}
number_dict = {i:w for i,w in enumerate(word_list)}
#{0: 'i', 1: 'like', 2: 'dog', 3: 'coffee', 4: 'hate', 5: 'milk', 6: 'love'}
n_class = len(word_dict)#7
n_step =2
n_hidden=2
m=2
def make_batch(sentence):
input_batch = []
target_batch =[]
for sen in sentence:
word = sen.split()
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(input)
target_batch.append(target)
return input_batch,target_batch
class NNLM(nn.Module):
def __init__(self):
super(NNLM,self).__init__()
self.C = nn.Embedding(n_class,m)
self.H = nn.Parameter(torch.randn(n_step*m,n_hidden).type(dtype))
self.W = nn.Parameter(torch.randn(n_step*m,n_class).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden,n_class).type(dtype))
self.b = nn.Parameter(torch.randn(n_class).type(dtype))
def forward(self,X):
X = self.C(X)
X = X.view(-1, n_step * m)
tanh = torch.tanh(self.d + torch.mm(X,self.H))
output = self.b +torch.mm(X,self.W)+torch.mm(tanh,self.U)
return output
model = NNLM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=0.001)
input_batch,target_batch = make_batch(sentence)
input_batch = Variable(torch.LongTensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch))
for epoch in range(5000):
optimizer.zero_grad()
output = model(input_batch)
loss = criterion(output,target_batch)
if(epoch+1)%1000 == 0 :
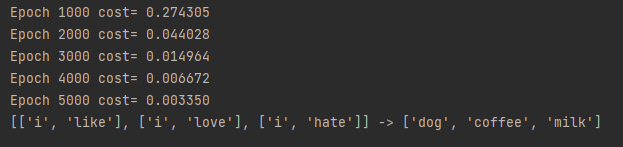
print('Epoch','%04d' %(epoch+1),'cost=','{:.6f}'.format(loss))
loss.backward()
optimizer.step()
predict = model(input_batch).data.max(1,keepdim= True)[1]
print([sen.split()[:2] for sen in sentence],'->',[number_dict[n.item()] for n in predict.squeeze()])
实验结果

















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









