




 本文介绍了一个基于Requests、Re和BeautifulSoup的爬虫项目,详细讲解了如何从网站爬取特定信息,包括分析网页结构、发送HTTP请求、解析HTML文档和提取所需数据。
本文介绍了一个基于Requests、Re和BeautifulSoup的爬虫项目,详细讲解了如何从网站爬取特定信息,包括分析网页结构、发送HTTP请求、解析HTML文档和提取所需数据。
爬虫路线Requests-Re-BeautifulSoup技术路线总结
最近工作中需要用到爬虫,于是自己学习了一下,项目难度不算大,因此不需要用到框架,主要用到requests、bs4、re三个模块,正好最近爬取某某佳缘用户图片正好用到了这三个模块,以此项目为例总结一下:
首先,盗亦有道,先看一下网站的robots协议,方法为网址+/robots.txt,发现并没有相关协议。robots协议是网站与爬取者之间的约束规则,没有强制效应,全靠自觉。如果网站有相关规定,最好还是遵守。
然后开始爬取过程,第一步需要明确目的,假设我的目的为,在xx佳缘的搜索引擎上找到符合我搜索条件的用户基本信息。有了目标后第二步开始分析如何达成目标。
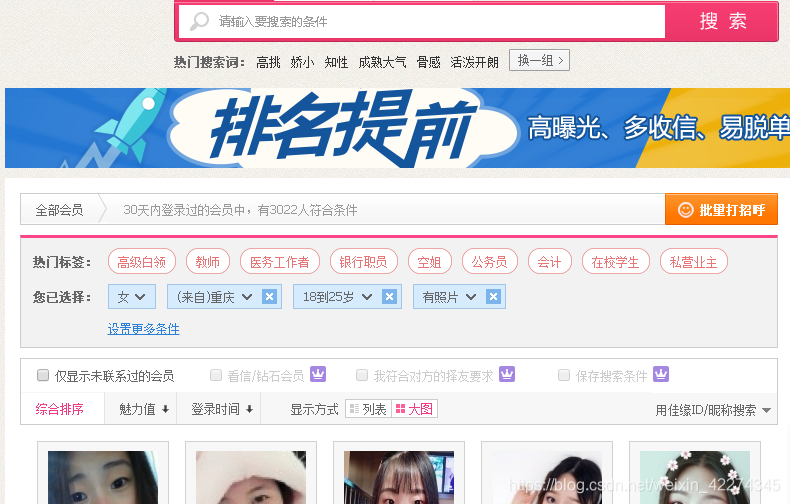
一.requests库的使用
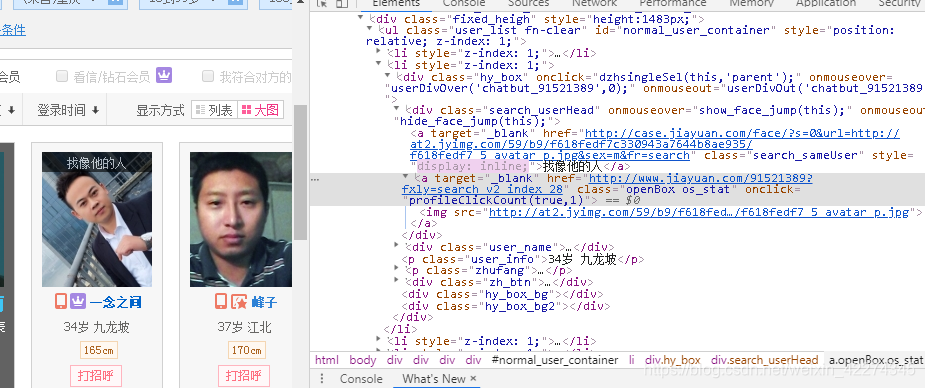
进入网站,点击搜索栏,可以看到,网站提供了丰富的搜索条件,下方展示了与搜索条件相关的用户。可以在chrome右键检查相应位置的html代码,发现网页上有直接导向用户主页的链接,再使用requests库验证返回的html文件中是否包含用户信息。requests库为python上常用于爬虫的第三方库,需要额外安装导入。
import requests
def getHtmlText():
try:
url = 'http://search.jiayuan.com/v2/index.php?key=&sex=f&stc=1:50,2:18.23,3:155.170,23:1&sn=default&sv=1&p=1&pt=1073&ft=off&f=select&mt=u'
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('出现异常')
r = requests.get(url,timeout=30),右边构造一个向服务器发出资源请求的Request对象,左边为包含服务器返回资源的Response对象。
r.raise_for_status()作用为,若发生连接问题则抛出异常。
r.encoding = r.apparent_encoding 表示将Response的编码方式更改为从内容中分析的响应内容编码方式。
Response对象常用的属性有r.status_code、r.text、r.encoding、r.apparent_encoding、r.content。
requests库最常用方法为get和post
调用上述函数后返回的文本中并没有用户相关的信息或链接,说明网页存在其他的网络活动,需要查看网络请求获取相关信息。
二、查看网络活动
在chrome上按F12,在network一栏查看网络活动,发现由
http://search.jiayuan.com/v2/search_v2.php使用post方法可以得到返回的json值
def getHtmlText(url, formData,proxy):
headers = {
'user-agent': random.choice(user_agents)
}
formData = {'sex': 'f', 'key': '', 'stc': '23:1', 'sn': 'default', 'sv': '1', 'p': '1',
'f': 'select', 'pt': '3011', 'ft': 'off', 'mt': 'd'}
try:
r = requests.post(url, timeout=10, headers=headers, data=formData, proxies=proxy)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
三、re库的使用:
根据返回的文本信息,利用正则表达式提取出我们想要的信息。

根据返回的json信息,获取用户ID
主要使用re.search()、re.findall()
re.search(pattern,string,flags = 0):pattern为正则表达式字符串表示,string为待匹配表达式,flages为控制标记如re.I忽略大小写匹配,返回match对象,使用match.group[0]得到匹配的字符串。
re.findall()参数相同,返回列表。
def getIdList(res):
try:
#注意正则表达式也需要转义如:想匹配\需要写\\
idLst = re.findall(r'"realUid":\d+', res)
return idLst
except:
print("无法获取列表")
四、BeautifulSoup库的使用
根据得到的ID组合成用户主页,经过检查网页,发现页面内存在用户信息,可以使用BeautifulSoup库解析HTML网页。
<p class='side'>Hello</p>:标签
p:名称 class:属性 Hello:非属性字符串
常用soup.find_all()和soup.find(),soup.find_all()返回列表,soup.find()返回字符
参数为:name、attrs、recursive、string
如想找到上述标签可使用如:soup.find('p','side')、soup.find(string = 'Hello')、soup.find(string = re.cpmpile('he'))
进入用户主页,查看网页源码,可看到如下信息,用soup.find_all()找到相应标签:

def parsePage(page):
try:
soup = BeautifulSoup(page, "html.parser")
ite = soup.find_all('div', 'fl f_gray_999')
info = soup.find_all('em')
return ite,info
except:
print("解析网页失败")

















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









