







 本文介绍了使用Scrapy框架和requests、BeautifulSoup库来爬取股票数据的过程,包括安装、框架结构、创建Spider、编写Pipelines、获取股票列表和个股信息的步骤,最终将数据存储为txt文档。文章详细讲解了每个步骤,包括解决安装问题、爬取股票列表和个股详情,以及数据处理与存储。
本文介绍了使用Scrapy框架和requests、BeautifulSoup库来爬取股票数据的过程,包括安装、框架结构、创建Spider、编写Pipelines、获取股票列表和个股信息的步骤,最终将数据存储为txt文档。文章详细讲解了每个步骤,包括解决安装问题、爬取股票列表和个股详情,以及数据处理与存储。
Scrapy
中文名:抓取
一个功能强大、快速、优秀的第三方库
它是软件结构与功能组件的结合,可以帮助用户快速实现爬虫。
Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
框架安装
使用管理员权限启动command控制台
\>pip install scrapy
测试安装
输入指令查看所有scrpy命令
\>scrapy -h
出现以下界面则可视为安装成功
我们还可以通过指令查看帮助信息:
\>scrapy --help
命令提示符输出如下:
Scrapy框架常用命令:
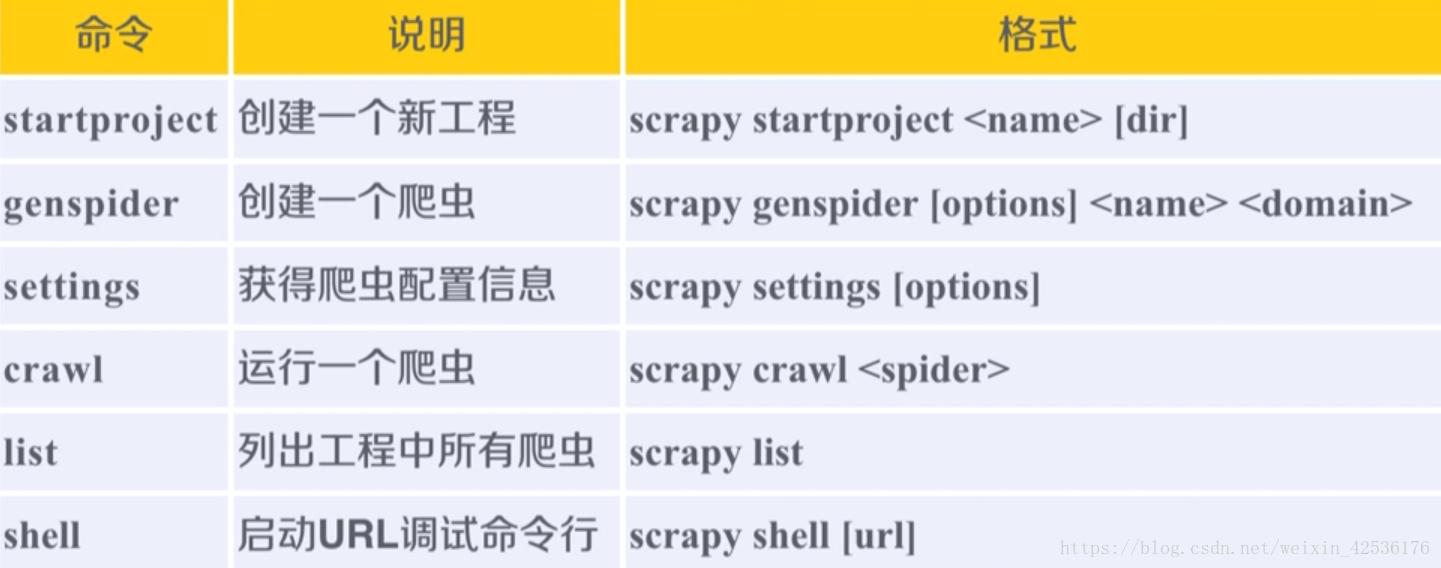
我们本次实验只用到了startproject、genspider和crawl命令
Scrapy“5+2”框架结构
5个主体部分:
已有的功能实现:
Engine 控制模块间的数据流、根据条件触发事件
Schedule 对所有爬取请求进行调度
Downloader 根据请求下载网页
需要配置实现:
Spiders 解析返回的响应、产生爬取项与新的爬取请求
Item Pipelines 清理、检验和查重爬取项中的数据与数据存储
2个中间键(可配置):
SpiderMiddleware 修改、丢弃、新增请求或爬取项
Downloader Middleware 修改、丢弃、新增请求或响应
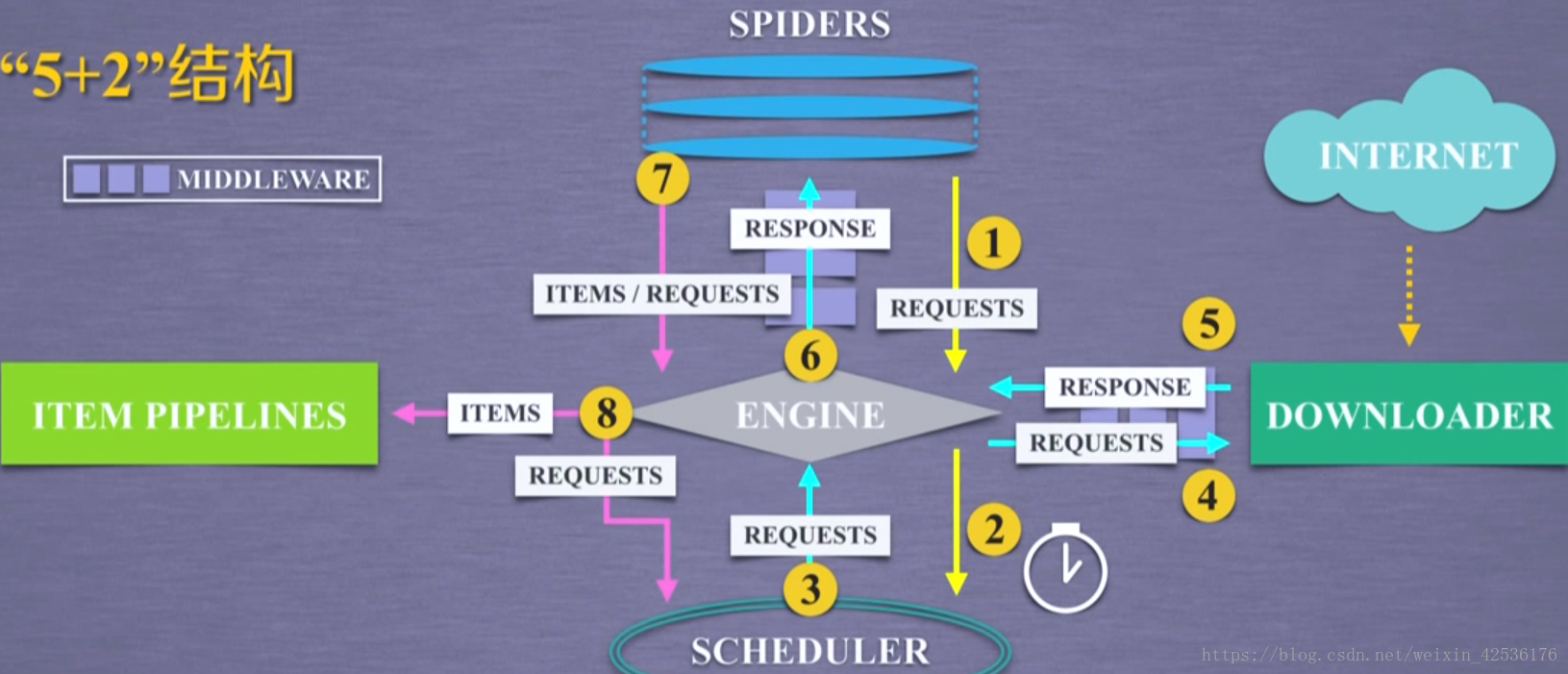
1. Spiders向Engine发送网页信息爬取请求
2. Scheduler从Engine接收爬取请求并进行调度
3,4. Engine从Scheduler获得下一个网页信息爬取请求,通过中间键发送给Downloader
5,6. Downloader连接互联网爬取网页内容,形成响应(爬取内容)通过中间键与Engine发送给Spiders
7. Spiders处理获得的响应(爬取内容),形成爬取项与新的网页信息爬取请求发送给Engine
8. Engine将爬取项发送给Item Pipelines,将新的爬取请求发送给Scheduler进行调度,形成循环为数据处理与再次启动爬虫进行爬取提供数据。
功能概述:
· 技术:Scrapy
· 目标:获取上交所和深交所的股票名称与交易信息
· 输出:txt文档
获取股票列表:
· 东方财富网:http://quote.eastmoney.com/stocklist.html
获取个股信息:
· 股市通:https://gupiao.baidu.com/stock/sz002338.html
过程概述:
1. 编写spider爬虫处理链接的爬取和网页解析
2. 编写pipeline处理解析后的股票数据并存储
具体流程
· 相关安装
使用管理员权限启动command控制台
\>pip install requests
\>pip install scrapy
====================================
接下来的工程我刚开始运行失败,后通过以下四步才得以运行
(视个人情况而定)
#先卸载scrapy框架
1. pip uninstall scrapy
#再卸载twisted框架
2. pip uninstall twisted
重新安装scrapy以及16.6.0版本的twisted
#先安装twisted框架
3. pip install twisted==16.6.0
#再安装scrapy,--no-deps指不安装依赖的twisted
4. pip install scrapy--no-deps
如仍不能运行可能需要安装pywin32模块
\>pip install pywin32
· 建立工程和Spider模板
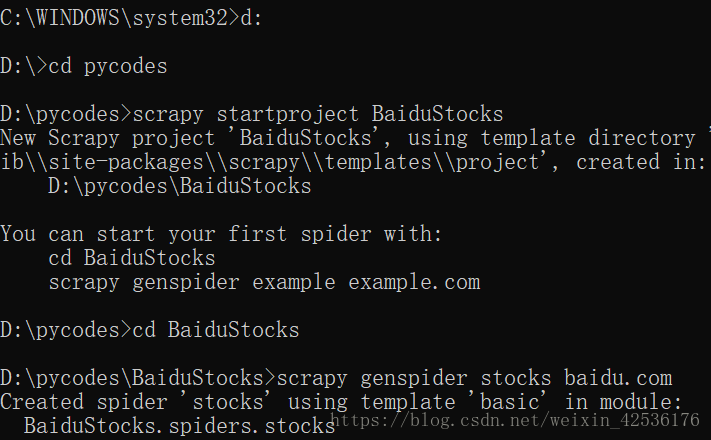
1. 转到目标目录
\>d:
\>cd pycodes
(注:目录位置不限定)
2. 生成BaiduStocks项目
\>scrapy startproject BaiduStocks
3. 修改当前目录
\>cd BaiduStocks
4. 生成stocks爬虫
\>scrapy genspider stocks baidu.com
· 编写spider
配置stocks.py
修改对返回页面与新增的URL爬取请求的处理,使其解析返回的信息
- import scrapy
- import re # 引入正则表达式库
- class StocksSpider(scrapy.Spider):
- name = "stocks"
- # 设置初始链接为股票列表页面链接
- start_urls = ['http://quote.eastmoney.com/stocklist.html']
- def parse(self, response): # 获取页面中股票代码并生成对应股票页面链接
- # for循环提取页面中所有<a>标签中的链接
- for href in response.css('a::attr(href)').extract():
- # 使用try...except忽略错误信息
- try:
- # 通过正则表达式获取股票代码
- stock = re.findall(r"[s][hz]\d{6}", href)[0]
- # 生成对应股票代码的页面链接
- url = 'https://gupiao.baidu.com/stock/' + stock + '.html'
- # 使用yield将函数定义为生成器将新请求重新提交给scrapy
- yield scrapy.Request(url, callback=self.parse_stock)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









