




 本文介绍了PyTorch中常见的优化器,包括SGD、Momentum、Adagrad、RMSProp和Adam,详细阐述了它们的工作原理和优缺点,并提供了PyTorch中选择优化器的参考建议。
本文介绍了PyTorch中常见的优化器,包括SGD、Momentum、Adagrad、RMSProp和Adam,详细阐述了它们的工作原理和优缺点,并提供了PyTorch中选择优化器的参考建议。
(六)Pytorch理解更多神经网络优化方法
1.了解不同优化器
参考:神经网络中的各种优化方法,其中主要包括GD、SGD、BGD、Momentum、Nesterov、RMSProp、Adagrad、AdaDelta和Adam,其中后三种是自适应的方法。
2.书写优化器代码
import torch
import torch.nn as nn
import torch.nn.init as init
import pandas as pd
import numpy as np
import random
# 参数
ratio = 0.8
epochs = 500
learning_rate = 0.01
# 加载数据,划分数据集
datas = torch.from_numpy(pd.read_csv('diabetes.csv').values)
length = len(datas)
indices = list(range(length))
random.shuffle(indices)
train_idx, test_idx = indices[:int(ratio*length)], indices[int(ratio*length):]
train, test = datas[train_idx], datas[test_idx]
x_train, y_train = train[:,:-1], train[:,-1]
x_test, y_test = test[:,:-1], test[:,-1]
# 搭建网络
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.bn = nn.BatchNorm1d(8)
self.linear1 = torch.nn.Linear(8, 10)
self.linear2 = torch.nn.Linear(10, 20)
self.linear3 = torch.nn.Linear(20, 10)
self.linear4 = torch.nn.Linear(10, 1)
def forward(self, x):
x = self.bn(x.type(torch.FloatTensor))
x = torch.tanh(self.linear1(x))
x = torch.tanh(self.linear2(x))
x = torch.tanh(self.linear3(x))
return self.linear4(x)
m_SGD = Model()
m_Momentum = Model()
m_Adagrad = Model()
m_RMSProp = Model()
m_Adam = Model()
models = [m_SGD, m_Momentum, m_Adagrad, m_RMSProp, m_Adam]
opt_SGD = torch.optim.SGD(m_SGD.parameters(), lr=learning_rate)
opt_Momentum = torch.optim.SGD(m_Momentum.parameters(), lr=learning_rate, momentum=0.9)
opt_Adagrad = torch.optim.Adagrad(m_Adagrad.parameters(), lr=learning_rate)
opt_RMSProp = torch.optim.RMSProp(m_RMSProp.parameters(), lr=learning_rate, alpha=0.9)
opt_Adam = torch.optim.Adam(m_Adam.parameters(), lr=learning_rate, betas=(0.9,0.99))
opts = [opt_SGD, opt_Momentum, opt_Adagrad, opt_RMSProp, opt_Adam]
criterion = torch.nn.BCEWithLogitsLoss()
loss_list = [0,0,0,0]
# 训练
for epoch in range(epochs):
for model,opt,loss in zip(models,opts,loss_list):
y_pred = model(x_train)
loss = criterion(y_pred, y_train.float().view(-1, 1))
opt.zero_grad()
loss.backward()
opt.step()
# 测试
for model in models:
y_pred = model(x_test)
preds = (y_pred >= 0).clone().detach()
corrects = torch.sum(preds.byte() == y_test.view(-1,1).byte())
acc = corrects.item()/len(x_test)
print(acc)
3.随机梯度下降法
SGD是最基础的优化方法,普通的训练方法, 需要重复不断的把整套数据放入神经网络NN中训练,
这样消耗的计算资源会很大.当我们使用SGD会把数据拆分后再分批不断放入 NN 中计算. 每次使用批数据, 虽然不能反映整体数据的情况,
不过却很大程度上加速了 NN 的训练过程, 而且也不会丢失太多准确率.
4.Momentum
带momentum(动量)的梯度下降法也是一种很常用的的优化算法。这种方法因为引入了momentum量,所以能够对梯度下降法起到加速的作用。
5.Ada自适应梯度调节法
特点: 在训练过程中,每个不参数都有自己的学习率,并且这个学习率会根据自己以前的梯度平方和而进行衰减。
优点:在训练的过程中不用认为的调整学习率,一般设置好默认的初始学习率就行了缺点:随着迭代的进行,公式(6)中的学习率部分会因为分母逐渐变大而变得越来越小,在训练后期模型几乎不再更新参数。
6.RMSProp
参考:https://www.jianshu.com/p/e3458bf9710f
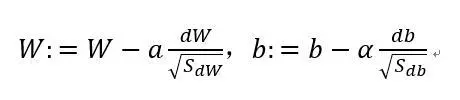
7.Adam
Adam方法就是根据上述思想而提出的,对于每个参数,其不仅仅有自己的学习率,还有自己的Momentum量,这样在训练的过程中,每个参数的更新都更加具有独立性,提升了模型训练速度和训练的稳定性。
8.Pytorch中优化器选择
参考:https://blog.youkuaiyun.com/blue_jjw/article/details/50650248
adagrad相比于sgd和momentum更加稳定,即不需要怎么调参。而精调的sgd和momentum系列方法无论是收敛速度还是precision都比adagrad要好一些。在精调参数下,一般Nesterov优于momentum优于sgd。而adagrad一方面不用怎么调参,另一方面其性能稳定优于其他方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









