







什么是Seq2seq
Seq2seq就是把一段输入序列挖掘提取特征“编码”存储到中间量里,然后根据中间量,然后训练“解码”输出想要的结果。
这里举两个例子:
- 机器翻译:把一种语言翻译成另一种语言
- 语音识别:把一段语音识别出来,用文字表示
从这两个例子可以看出,输入的是一段序列(一种语言文字和一段语音),就,(经过中间向量),然后输出也是一段序列(另一种语言文字和和语音对应的文字),即Sequence-to-sequence。
所谓的Sequence2Sequence任务主要是泛指一些Sequence到Sequence的映射问题,Sequence在这里可以理解为一个字符串序列,当我们在给定一个字符串序列后,希望得到与之对应的另一个字符串序列(如 翻译后的、如语义上对应的)时,这个任务就可以称为Sequence2Sequence了。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
seq2seq和RNN的关系是什么样的
前面介绍了seq2seq的任务,那它和我们之前学的CNN和RNN模型有什么关系呢?Seq2seq是一个解决任务的框架,像word2vec那样,根据不同的任务可以选择不同的编码器和解码器(例如,CNN、RNN、LSTM、GRU等)。只是在处理序列任务时,一般选用RNN系列模型作为seq2seq的组件。
编码器和解码器分别对应输入序列和输出序列的两个循环神经网络。在Seq2Seq结构中,编码器Encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻t-1的输出作为后一个时刻t的输入,循环解码,直到输出停止符为止。
为什么LSTM等也可以输入输出不等长,为什么还需要seq2seq?
Seq2seq的框架
概述
Seq2seq的本质是Encoder-Decoder结构,Encoder-Decoder的一个显著特征就是:它是一个end-to-end的学习算法。只要符合这种框架结构的模型都可以统称为Encoder-Decoder模型。
Seq2Seq可以看作是Encoder-Decoder针对某一类任务(序列任务)的模型框架,它们的范围关系如下所示:

Encoder-Decoder强调的是模型设计(编码-解码的一个过程),Seq2Seq强调的是任务类型(序列到序列的问题)。
Seq2seq模型由三个部分组成:编码器、中间状态向量和解码器。其中中间状态向量是编码器的输出,也是解码器的输入,如何设定中间状态向量也是学习研究的重点之一。
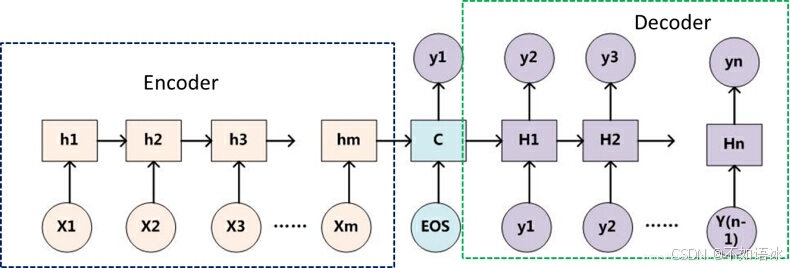
不论输入和输出的长度是什么,中间的“向量c”长度都是固定的(这是它的缺陷所在)。
信息丢失的问题
通过上文可以知道编码器和解码器之间有一个共享的中间向量(上图中的向量c)来传递信息,而且它的长度是固定的,意味着编码器要将整个序列的信息压缩进一个固定长度的向量中去。
这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,二是先输入的内容携带的信息会被后输入的信息稀释覆盖掉。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息,那么解码的准确度自然也就要打个折扣了。这个问题后续介绍注意力方法的时候会有所缓解。
便于理解,我们把“编码-解码”的过程类比为图片“压缩-解压”的过程:将一张800X800 像素的图片压缩成 100KB,看上去还比较清晰。而将一张 3000X3000 像素的图片也压缩到 100KB,看上去就模糊了。
下面具
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









