







目标检测任务描述
(1)输入一张图片,图片上有个目标,那么该如何描述目标在图像上的位置呢?我们知道,图像是长*宽的尺寸的像素点组成的,可以在图像上设置图像坐标系(比如以左上角为坐标原点,向右向下分别为x,y轴正方向),然后就可以使用边界框选中目标,边界框使用在图像坐标系上的坐标来表示,如下图,x,y,w,h,其中(x,y)是边界框左上角的像素坐标,w,h分别是边界框的宽和高。

(2)边界框还有其它表示方法,核心就是描述边界框在整张图像上的位置,如下:
p1,p2,p3,p4(4个点坐标)
cx,cy,w,h(cx,cy为中心点坐标)
x,y,w,h,angle(还有的目标是有角度的,这时叫做Rotated Bounding Box)
- 那么该如何预测这个边界框呢?传统方法是设定很多很多个边界框,从图像的左上角直到右下角,每个像素点都设置多个边界框(边界框的大小可以变化),如下图所示,这也是R-CNN系列模型所采用的思想,但这种思路的最大问题是耗时和操作复杂,需要手动生成大量的样本。比如输入图片大小是(800,1000)也就意味着有800000个位置。窗口大小最小1*1 ,最大800*1000(极限,具体应用时会优化) ,所以这个遍历的次数是无限次。

(4)边界框的表示方法可以变化,但是其描述都是一个含有4个值的向量,那么在检测目标的时候是不是就可以直接预测这个向量呢?自然是可以的,就是像分类网络预测类别一样根据提取的特征预测边界框的位置(后续会优化成偏移量)。
即分类网络是:img cbrp16 cbrp32 cbrp64 cbrp128 ...fc256-fc[10]
现在变成:img cbrp16 cbrp32 cbrp64 cbrp128 ... fc256-fc[5],这个输出是(x,y,w,h,c),不就变成了一个检测器吗?
这里的cbrp指的是conv,bn,relu,pooling的串联。由于输入要是one-hot形式,所以最后我们设计了2个fc层(fully connencted layer),称之为“分类头”或者“决策层”。
(5)前面只是说了一张图片检测一个目标,若是一个图片上需要检测多个目标,以及目标较小时又该如何做呢?是不是输出N个向量就行了呢?但具体输出多少个合适呢?有的图片有几百个目标,这个N又该如何调整呢?

(6)上面还仅仅是目标位置的检测,还需要识别目标的类别,这个是否可以直接参考分类网络的方法呢?
综上所述,我们的任务就是在一张图片上检测出所有目标(目标数量和种类不定)的位置(边界框),同时识别预测出每个目标的类别。接下来,我们就针对这几个问题介绍学习一下YOLO系列的网络模型。
YOLO v1网络架构
我们先来学习一下YOLO V1网络模型,然后在此基础上看一下后续是如何进行优化的。
前面讲到传统方法是先枚举出大量的边界框,然后在判断边界框是否包含目标,R-CNN系列在这个思想的基础上进行了优化改进,包括设置边界框的数量和格式,以及根据真实框去调整边界框的偏移量。
那么YOLO v1是如何做的呢?YOLO v1模型将输入的图片划分成S*S个区域,如果目标的中心落在该区域,那么该区域就负责检测该物体,一次性输出所检测到的目标信息,包括类别和位置。下面我们详细学习一下细节。
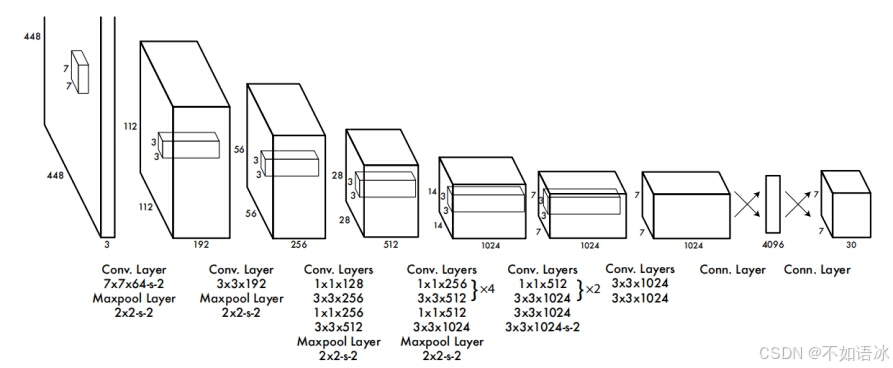
网络输入:448 x 448 x 3的RGB图片。
中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
全连接层:由两个全连接层组成,用来预测目标的位置和类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









