



 本文介绍了如何在官方社区的新版本中使用自定义device_map来部署一个72B的大模型,包括git克隆代码、安装依赖、配置device_map以在两张GPU上分配模型参数,以及使用auto-gptq进行量化权重安装。作者还提供了日志截取和测试步骤。
本文介绍了如何在官方社区的新版本中使用自定义device_map来部署一个72B的大模型,包括git克隆代码、安装依赖、配置device_map以在两张GPU上分配模型参数,以及使用auto-gptq进行量化权重安装。作者还提供了日志截取和测试步骤。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
一直想找机会试试更大的模型,奈何钱包不给力。
最近发现官方社区更新了一版自定义device_map(PS:之前一直是失败)
这次有新东西了 我们来看看2张卡部署72B大模型 - 百亿大模型部署系列
一、git clone
git clone https://github.com/QwenLM/Qwen.git
二、安装依赖
#1.切换至项目目录下
cd Qwen-main
#2.安装项目依赖
pip install -r requirements.txt
#使用镜像源加速 pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
#3.使用web_demo.py 还需要安装web依赖
pip install -r requirements_web_demo.txt
三 .flash-attention(可选)
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# 下方安装可选,安装可能比较缓慢。
# pip install csrc/layer_norm
# 如果flash-attn版本高于2.1.1,下方无需安装。
# pip install csrc/rotary
四.自定义device_map
- 编辑web_demo.py
- device_map可以参考这篇文章介绍利用 device_map、torch.dtype、bitsandbytes 压缩模型参数控制使用设备
# 48行附近 找到device_map = "auto" 修改为如下指定内容
device_map={'transformer.wte': 0, 'transformer.drop': 0, 'transformer.rotary_emb': 0, 'transformer.h.0': 0,'transformer.h.1': 0, 'transformer.h.2': 0, 'transformer.h.3': 0, 'transformer.h.4': 0, 'transformer.h.5': 0, 'transformer.h.6': 0, 'transformer.h.7': 0, 'transformer.h.8': 0, 'transformer.h.9': 0, 'transformer.h.10': 0, 'transformer.h.11': 0, 'transformer.h.12': 0, 'transformer.h.13': 0, 'transformer.h.14': 0, 'transformer.h.15': 0, 'transformer.h.16': 0, 'transformer.h.17': 0, 'transformer.h.18': 0, 'transformer.h.19': 0, 'transformer.h.20': 0, 'transformer.h.21': 0, 'transformer.h.22': 0, 'transformer.h.23': 0, 'transformer.h.24': 0, 'transformer.h.25': 0, 'transformer.h.26': 0, 'transformer.h.27': 0, 'transformer.h.28': 0, 'transformer.h.29': 0, 'transformer.h.30': 0, 'transformer.h.31': 0, 'transformer.h.32': 0, 'transformer.h.33': 0, 'transformer.h.34': 0, 'transformer.h.35': 0, 'transformer.h.36': 0, 'transformer.h.37': 0, 'transformer.h.38': 0, 'transformer.h.39': 0, 'transformer.h.40': 1, 'transformer.h.41': 1, 'transformer.h.42': 1, 'transformer.h.43': 1, 'transformer.h.44': 1, 'transformer.h.45': 1, 'transformer.h.46': 1, 'transformer.h.47': 1, 'transformer.h.48': 1, 'transformer.h.49': 1, 'transformer.h.50': 1, 'transformer.h.51': 1, 'transformer.h.52': 1, 'transformer.h.53': 1, 'transformer.h.54': 1, 'transformer.h.55': 1, 'transformer.h.56': 1, 'transformer.h.57': 1, 'transformer.h.58': 1, 'transformer.h.59': 1, 'transformer.h.60': 1, 'transformer.h.61': 1, 'transformer.h.62': 1, 'transformer.h.63': 1, 'transformer.h.64': 1, 'transformer.h.65': 1, 'transformer.h.66': 1, 'transformer.h.67': 1, 'transformer.h.68': 1, 'transformer.h.69': 1, 'transformer.h.70': 1, 'transformer.h.71': 1, 'transformer.h.72': 1, 'transformer.h.73': 1, 'transformer.h.74': 1, 'transformer.h.75': 1, 'transformer.h.76': 1, 'transformer.h.77': 1, 'transformer.h.78': 1, 'transformer.h.79': 1, 'transformer.ln_f': 1, 'lm_head': 1}
# 18行附近修改模型文件地址
DEFAULT_CKPT_PATH = '/root/.cache/huggingface/hub/Qwen-72B-Chat-Int4'
五.安装auto-gptq使用量化后的权重
pip install auto-gptq optimum
安装完成后运行web_demo.py
python web_demo.py
日志截取
python web_demo.py
2024-01-11 13:15:30.812947: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-01-11 13:15:32.179653: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
CUDA extension not installed.
CUDA extension not installed.
Try importing flash-attention for faster inference...
Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
Warning: import flash_attn fail, please install FlashAttention to get higher efficiency https://github.com/Dao-AILab/flash-attention
Loading checkpoint shards: 100%|████████████████████████████████████████████| 21/21 [00:23<00:00, 1.12s/it]
Running on local URL: http://0.0.0.0:8000
To create a public link, set `share=True` in `launch()`.
六.测试

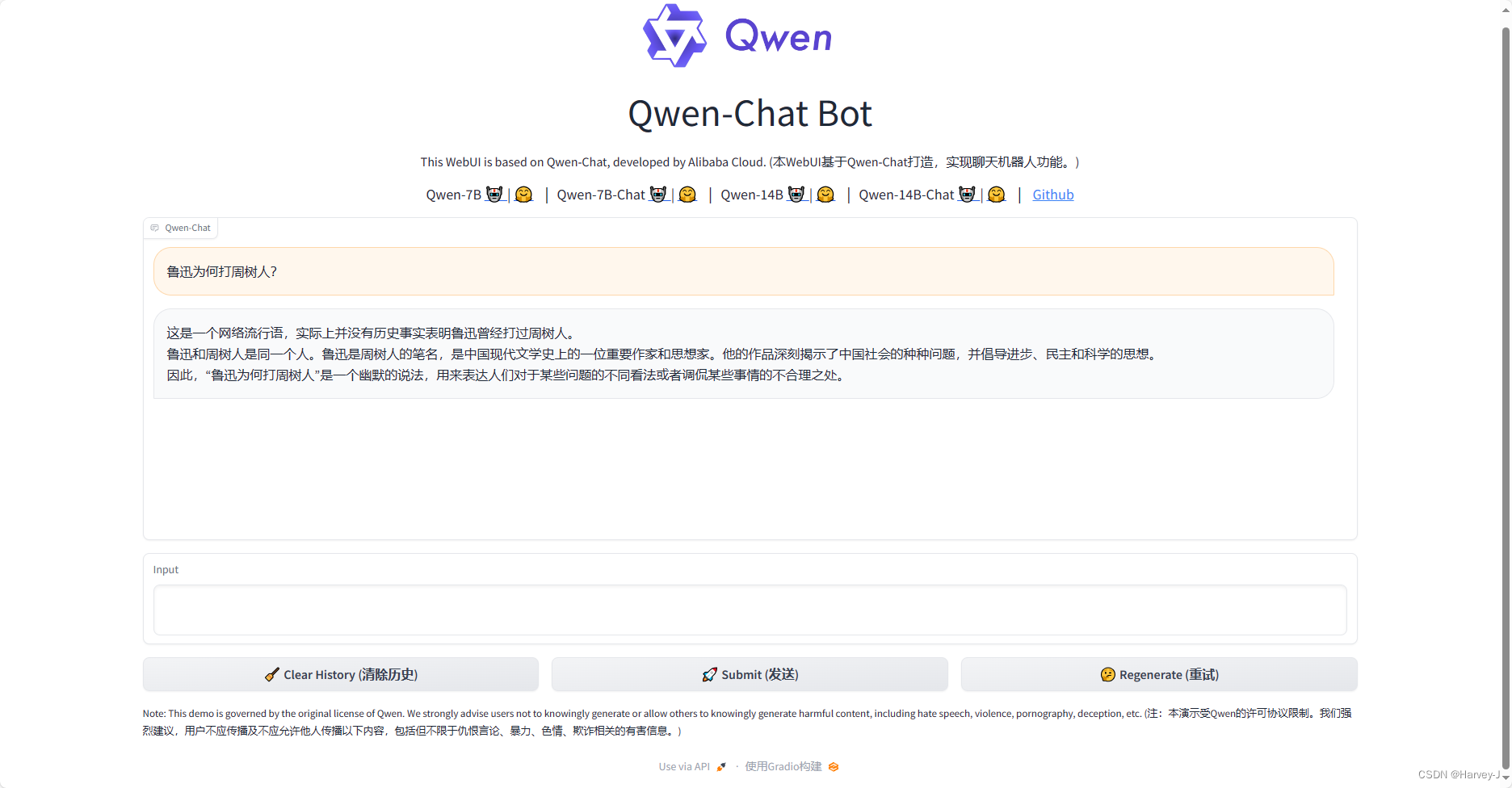
七.显存占用
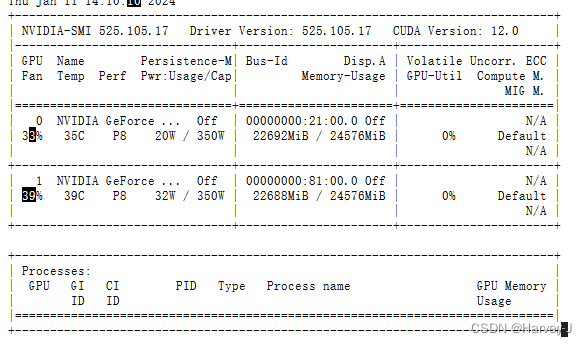
写在最后
欢迎移步我的Github仓库,https://github.com/Jun-Howie/erniebot-openai-api
本仓库使用飞桨星河社区接入ernie-4.0联网功能,如果你需要可以Fork我的仓库,还请给个Star让我知道




















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











