



 本文介绍了一种基于深度卷积神经网络的人体姿态识别系统,该系统利用一个相机和两个红外光源生成的投影阴影来增强姿势识别的准确性。通过对比实验,验证了CNN模型在人体姿态识别上的优越性,特别是当结合阴影和身体轮廓信息时,识别效果更佳。
本文介绍了一种基于深度卷积神经网络的人体姿态识别系统,该系统利用一个相机和两个红外光源生成的投影阴影来增强姿势识别的准确性。通过对比实验,验证了CNN模型在人体姿态识别上的优越性,特别是当结合阴影和身体轮廓信息时,识别效果更佳。
题目:Learning cast shadow appearance for human posture recognition
该篇文章自己建立了一个数据集,想必也是很繁琐的工作,采用了多个光源,来实现人体姿势的识别,对该领域并不了解,可能有它的意义,但是整理来自多个光源的图片绝对不是一件简单事。把多个光源形成的阴影合成一幅图片也是有难度的,我认为该篇最可贵之处在于此。另外,该篇文章还与一些传统方法进行对比分析,但是对CNN本身结构并没有什么创新,只是一幅图片包含的信息多了而已。
摘要:这篇文章展示了一个人体姿态识别系统,使用了一个相机和两个红外光源。该系统输入依靠身体轮廓和肉眼可见的投影。不同的姿势可能在透视投影上看起来相似,因此应用单一相机的常规监控视频可能不能正确的推断姿势。幸运的是,红外光源生成的投影身体阴影提供了额外的姿势信息,单一相机可能不能直接获取这些姿势信息。每一阴影可能被投射到不同的表面(如地面,墙面和家具),生成复杂的身体投影,这些投影在相同的姿势分类中呈现不同的形状。这些阴影图片是非常具有挑战性的并且很难用传统方法去描述。但是,一个深度卷积神经网络能够在大范围数据集中学习更好的数据特征。目前缺少一个大规模真实的数据集,我们使用合成数据来训练CNN分类器。由于合成数据与真实数据之间的差距,学习合成数据是一个挑战。因此,我们提出了一项正则技术来弥补这一差距并且帮助分类器利用真实的数据更好的生成。我们利用一个新的真实数据集来评价提出的这一系统,新的真实数据集由我们实验室制作利用电脑画图工具仿真而成。实验结果验证了CNN模型相对于其他卷积模型的高效性。另外,正如我们期望的那样,投影和身体轮廓的结合比只使用身体轮廓效果更好。
1.引言
2.提出的方法
2.1动机和系统设置
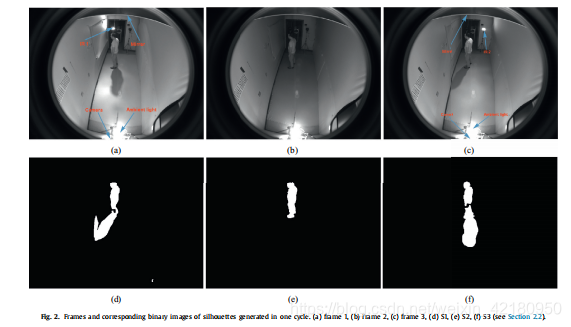
2.2去掉背景和统一数据
怎么合成和怎么统一的,看图就明白了

2.3卷积神经网络
2.4 卷积神经网络结构和混合参数调节
3.实验结果与分析
3.1 数据集及其预处理
3.1.1 真实数据集设置
3.1.2 合成数据集设置
3.2 结果与讨论
4. 总结

















 8
8

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









