







 本文探讨了数据模型复用性差的问题,指出其主要源于设计问题。通过分析数据平台任务和查询统计,揭示了模型完善度、复用度和规范度的重要性。提出了衡量模型的三个指标:完善度、复用度和规范度,并提供了具体的量化方法。此外,文章还介绍了如何通过接管ODS层、划分主题域、构建一致性维度和事实表整合等步骤实现数据共享,以构建高效的数据中台。
本文探讨了数据模型复用性差的问题,指出其主要源于设计问题。通过分析数据平台任务和查询统计,揭示了模型完善度、复用度和规范度的重要性。提出了衡量模型的三个指标:完善度、复用度和规范度,并提供了具体的量化方法。此外,文章还介绍了如何通过接管ODS层、划分主题域、构建一致性维度和事实表整合等步骤实现数据共享,以构建高效的数据中台。
摘要:通过本文的学习你将收货一些实实在在的干货,尤其对于数仓的小伙伴而言,我相信会有一些新的的认识。本文主要内容包括:
1、什么才是好的数据模型
2、如何衡量模型的完善度、复用度、规范度
3、如何实现数据共享
引言
上篇文章咱们一起讨论了如何管理指标从快手的指标规范出发聊一聊如何管理杂乱的数据指标,如果把指标比喻成一棵树上的果实,那me模型就是这棵大树的躯干,想让果实结的好,必须让树干变得粗壮。
首先来举个栗子(这可是真实场景奥):
大多数公司的分析师会结合业务做一些数据分析,通过报表的方式服务于业务部门的运营。但在公司数据建设初期,分析师经常发现自己没有可以复用的数据,不得不每次使用原始数据进行加工、计算指标。
由于很多分析师并不是技术出身,所以SQL写起来比较随性,导致资源消耗较大,然后引起一系列不必要的麻烦...
这些问题根源还是在于数据模型无法复用,数据开发是烟囱式的,每次遇到新的需求,都要从原始数据进行清洗、计算。要解决这个问题,我们要思考的就是数据模型应该设计成什么样子。引出:数据模型无法复用,归根到底还是设计的问题。那么,如何设计好的模型呢,咱们慢慢聊。
数据模型设计之好坏
下面咱们来看一组数据,这两个表格是基于元数据提供的血缘信息,分别对大数据平台上运行的任务和分析查询(Ad-hoc)进行的统计。
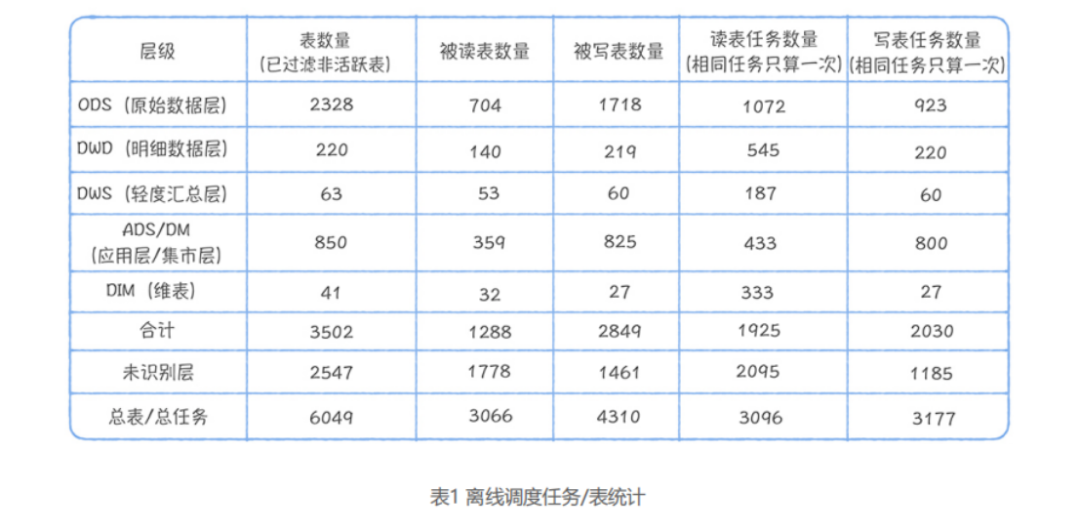
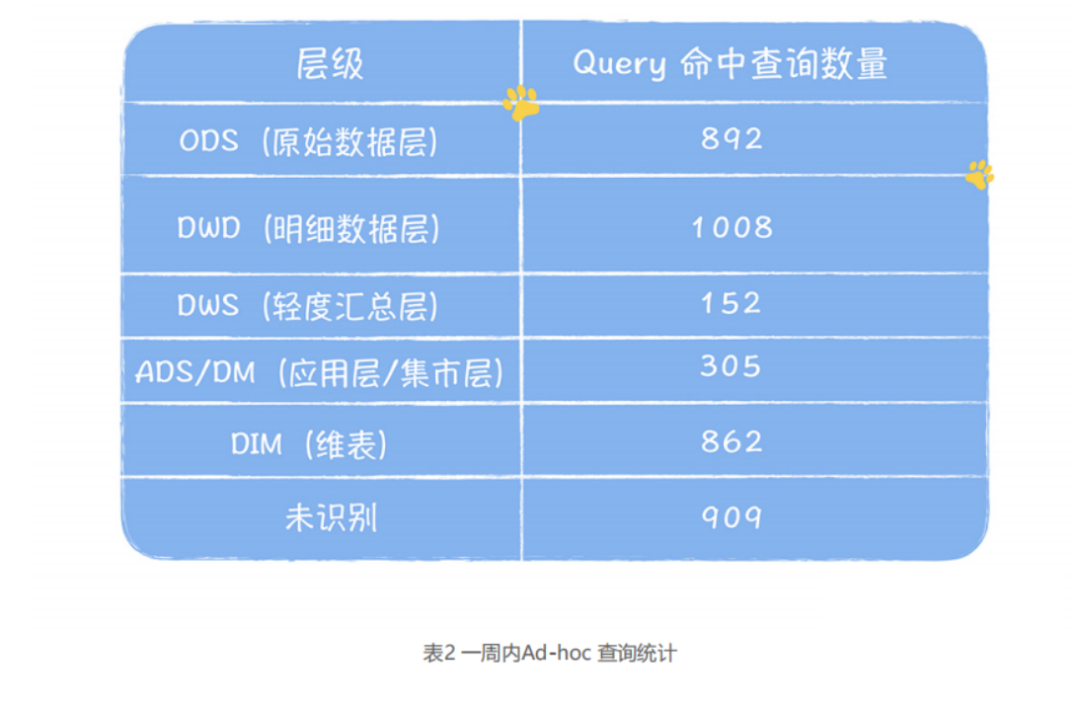
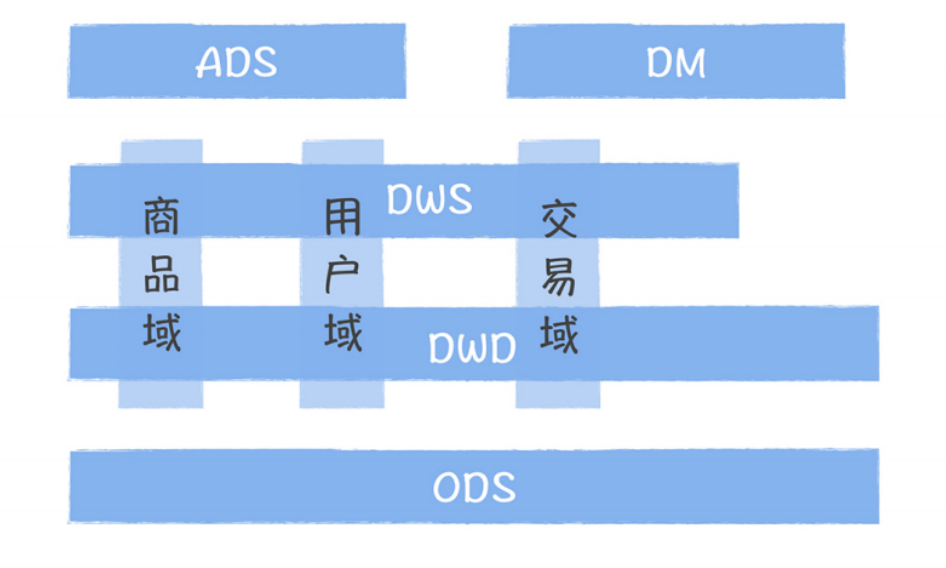
下面是数仓分层架构图,方便咱回忆数据分层的设计架构:
首先来看图1。图1 中有2547 张未识别分层的表,占总表 6049 的 40%,它们基本没办法复用。重点是在已识别分层的读表任务中,ODS:DWD:DWS:ADS 的读取任务分别是 1072:545:187:433,直接读取 ODS 层任务占这四层任务总和的 47.9%,这说明有大量任务都是基于原
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









