




 数据中台模型设计核心是追求复用和共享。差的模型设计自下而上是一条线,理想的是交织的发散型结构。用模型引用系数衡量复用度,其指一个模型被读取直接产出下游模型的平均数量,如 DWD 层表有相应引用系数及平均引用系数,经验值低于 2 较差,3 以上较好。
数据中台模型设计核心是追求复用和共享。差的模型设计自下而上是一条线,理想的是交织的发散型结构。用模型引用系数衡量复用度,其指一个模型被读取直接产出下游模型的平均数量,如 DWD 层表有相应引用系数及平均引用系数,经验值低于 2 较差,3 以上较好。
数据中台模型设计的核心是追求模型的复用和共享,通过元数据中心的数据血缘图,我们可以看到,一个比较差的模型设计,自下而上是一条线。而一个理想的模型设计,它应该是交织的发散型结构。
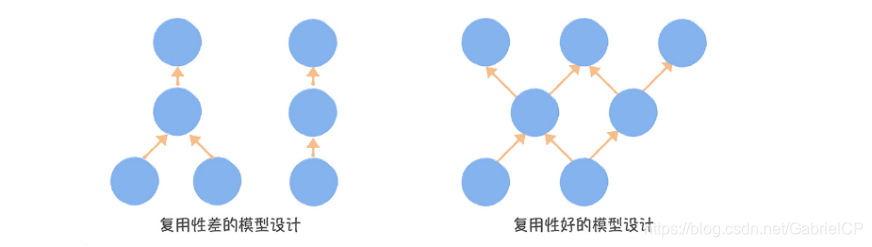
用模型引用系数作为指标,衡量数据中台模型设计的复用度。引用系数越高,说明数仓的复用性越好。
模型引用系数:一个模型被读取,直接产出下游模型的平均数量。
比如一张 DWD 层表被 5 张 DWS 层表引用,这张 DWD 层表的引用系数就是 5,如果把所有 DWD 层表(有下游表的)引用系数取平均值,则为 DWD 层表平均模型引用系数,一般低于 2 比较差,3 以上相对比较好(经验值)。

















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









