







快速链接:
.
👉👉👉 个人博客笔记导读目录(全部) 👈👈👈
- 付费专栏-付费课程 【购买须知】:
- 【精选】ARMv8/ARMv9架构入门到精通-[目录] 👈👈👈
- 联系方式-加入交流群 ----联系方式-加入交流群

多核 ARM SoC 面临缓存一致性困境
ARM 正在通过多核处理器将其固有的低功耗架构提升到更高的性能水平。
如果ARM继续拥有移动CPU插槽,四核及以上处理器将成为高端智能手机和平板电脑的标准。虽然多核 SoC 承诺提供高性能和低功耗,但这些芯片的设计人员也将面临非常严峻的技术挑战——实现硬件缓存一致性。
高速缓存一致性确保每个核心都运行最新的数据,无论数据驻留在其高速缓存、另一个核心的高速缓存还是主内存中。这听起来很简单,但当您有多个核心并行工作并不断更新其缓存内容时,实际上很难。过去,内核上运行的软件用于保持缓存内容最新。然而,由于这是一项相对较慢且消耗电力的活动,因此最好在硬件中执行。
为了支持实现缓存一致性系统的标准方法,ARM 于 2011 年发布了 AXI 一致性扩展 (ACE) 规范,以添加到他们的 AMBA 协议集中。ARM 还发布了 CCI-400 互连 IP,它提供了缓存一致性互连来链接移动 SoC 中的组件。正是这些关键构建块、ACE 规范和 CCI-400 互连(将 A7 或 A15 等内核连接在一起)实现了多核缓存一致性系统。然而,它们也给验证工程师带来了新的挑战,他们必须确保移动 SoC 正常运行。
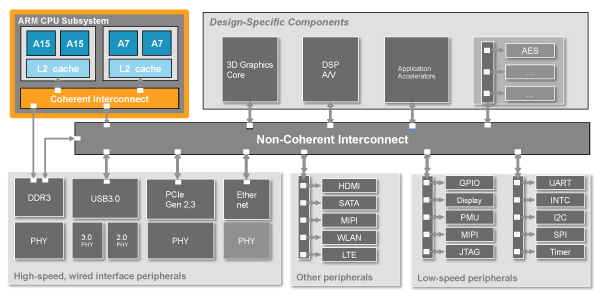
ACE 验证挑战
验证任何多核系统中的一致性都很困难,因为合法和非法操作之间通常存在细微差别。为了了解这一点,让我们看一下 4 核系统中 2 种不同类型的读取命令的示例,如图 1 所示。我们将该系统中的内核命名为 M1 到 M4。在第一种情况下,我们假设 M1 发出ReadClean命令来检索某个数据项。该数据项的最新版本可能驻留在主存储器中或者可能位于M2、M3或M4的各个高速缓存中。
互连需要找到最新版本并将其发送到 M1,因此执行的第一步是监听其他内核的缓存。在这种情况下,M3 恰好拥有最新数据,因此互连会获取该数据,将其写入主存储器,然后将其发送到 M1。您可以看到互连“清理”了主内存,因此得名ReadClean。
现在让我们考虑第二种类型的读操作。这次M1针对某个数据项发出ReadUnique命令。互连执行窥探并再次发现 M3 具有最新版本的数据。然而,互连并不更新主存储器,而是简单地将数据发送到 M1。主存数据项仍然过时,M3 有责任在以后更新它。ACE规范中定义了近20种读写操作,因此构建验证场景来测试每种类型的操作是一项重大挑战。
验证基于 ACE 的系统的另一个主要挑战是验证空间的巨大规模。事务类型、响应类型、域和缓存状态等 ACE 规范元素的组合(被验证工程师称为“叉积”或简称“交叉”)数量巨大,每种组合和排列都必须经过完全验证。一般经验法则是,需要使用 ACE 互连进行验证的交叉数量约为 7000 x N,其中 N 是主设备的数量。因此,在四核系统中,需要验证28,000个叉积。
考虑到这一点,为什么 CCI-400(ARM 开发的第一个缓存一致性互连)只有 2 个完整的 ACE 主设备似乎就很明显了。挑战不仅在于设计的复杂性,还在于验证工作的范围。其他非一致性互连,如 NIC-400(另一种 ARM 互连)可以配置超过 100 个主设备和从设备,但是当需要一致性时,就不可能提供这种灵活性。
现在让我们更深入地研究一下验证问题。用 ACE 的说法,“场景”是以下因素的组合:事务类型、发起主缓存状态、响应主缓存状态和响应值。例如,如果互连中完整 ACE 主设备的数量为 8,那么实际上需要验证 8*7000= 56,000 个场景吗?嗯,不一定。许多交叉是不合法的(例如,不能存在两个主设备都在Unique状态或Dirty状态下保存相同的缓存数据项的情况)。因此,有效的验证需要将验证空间减少到仅包含相关排列。
不幸的是,测试各个内核和互连之间的逻辑握手虽然很复杂,但只是验证问题的一部分。我们谈论的是多核系统,每个核心可能并行发出命令。对于互连来说,将其全部整理出来是一项非常艰巨的任务,对于验证工程师来说也是一个巨大的挑战,他们必须创建足够复杂的测试场景,以发现系统中隐藏的极端情况错误。
另一个复杂的因素是 ACE 支持 Barrier 交易的概念。障碍会导致处理流程停止,直到满足某些条件。当主设备发送屏障事务时,它要求在屏障发出之前启动的命令允许在屏障生效之前完成。同样,由于多个核心可能会发出屏障事务,互连(和验证工程师)的负担会成倍增加。
到目前为止,我们讨论的所有内容都仅涉及包含内核(例如 A7、A15)和相干互连(例如 CCI-400)的处理器子系统。该处理器子系统通过非一致互连(例如 ARM NIC-400)连接到 SoC 的其余部分。因此,通过非一致性互连运行的验证场景应与处理器子系统测试并行运行,以找出仅在整个芯片运行时出现的错误。
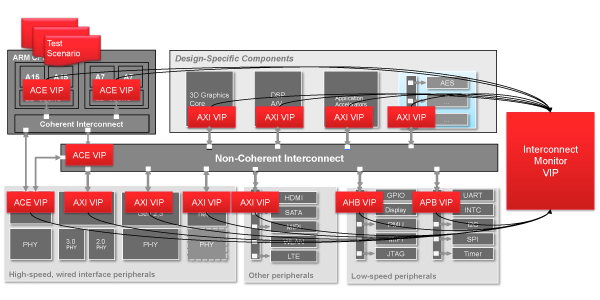
验证IP要求
鉴于上述困难的验证挑战,以某种方式卸载部分验证工作至关重要。正如 IP 组件减轻了设计工作量一样,验证 IP (VIP) 组件也减轻了验证工作量。验证我们一直在考虑的 SoC 类型所需的 VIP 组件的类型和布局如图 2 所示。为了有效,VIP 必须提供验证基于 ACE 的设计所需的三个主要功能。他们是:
- 1)模拟所有可能的场景以覆盖完整的验证空间
-
- 确保一致性和系统符合 ACE 规范
-
- 测量覆盖率并确保验证完整性。
- 刺激的产生
验证基于 ACE 的设计非常复杂,需要使用验证 IP,该 IP 可了解系统中各种类型 ACE 主站和从站的协议行为。这使得用户不必了解创建合法(或非法)交易所需的协议细节。
旨在模仿处理器行为的 VIP 必须创建考虑协议规则的刺激,包括缓存模型,并在生成事务时纳入任何特定于设计的约束。VIP还必须根据总线状态正确计算时序。
2)一致性检查
每个主设备和从设备必须单独进行验证,以确保其符合规范,但这还不够。VIP 必须与互连监视器配合使用,以监视互连上的所有流量。这对于确保整个系统的一致性是必要的。这意味着 ACE 和互连监视器 VIP 需要执行两项关键任务:
- A. 确保每个单独的组件(例如处理器、内存)运行正常。
- b. 监控互连以确保所有块之间的通信准确且符合 ACE 规范。
项目(a)由VIP的主代理和从代理启用。一旦用户将块 RTL 与互连集成在一起,VIP 将用作被动代理,因此它必须监视每个单独的总线接口以确保协议合规性。
为了启用项目 (b),还需要一个单独的互连监视器。如果没有这样的互连监视器,就不可能确保完整的系统一致性。该监视器必须检查互连本身的数据完整性和正确性,以确保其行为符合 ACE 规范。
例如,只有了解设计中所有主控器和域的互连监视器才能检查由主控器发起的一致事务是否导致互连在正确的域和主控器中创建监听事务。
3)覆盖范围
如前所述,与基于 ACE 的设计相关的巨大状态空间提出了关键的验证挑战。简单地定义所有复杂的场景本身就需要大量投资。然而,这还不够。ACE 验证解决方案必须使您能够测量并确保验证空间的完整性。
覆盖模型用作确定验证完整性的指标。因此,VIP提供基于ACE规范的完整覆盖图势在必行。如上所述,有效地执行验证需要缩小覆盖范围以仅监控合法的交叉产品。覆盖模型就起到了这个作用。



















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











