









 本文介绍了BatchNormalization、LayerNormalization、InstanceNormalization及GroupNormalization等归一化技术,并解释了这些技术如何解决深度学习中梯度消失的问题,加快训练速度。
本文介绍了BatchNormalization、LayerNormalization、InstanceNormalization及GroupNormalization等归一化技术,并解释了这些技术如何解决深度学习中梯度消失的问题,加快训练速度。
几种缩写分别对应
- Batch Normalization
- Layer Normalization
- Instance Normalization
- Group Normalization
需要normalization的原因
(1)深度学习包含很多隐含层,每层参数都会随着训练而改变优化,所以隐层的输入分布总会变化,会使得每层输入不再是独立同分布。这就造成,上一层数据需要适应新的输入分布,数据输入激活函数时,会落入饱和区,使得学习效率过低,甚至梯度消失。
(2)深度学习会使激活输入分布偏移,落入饱和区,导致反向传播时出现梯度消失,这是训练收敛越来越慢的本质原因。而通过归一化手段,将每层输入强行拉回均值0方差为1的标准正态分布,这样使得激活输入值分布在非线性函数梯度敏感区域,从而避免梯度消失问题,大大加快训练速度。
图解
给出一次训练iteration时某层数据示例:
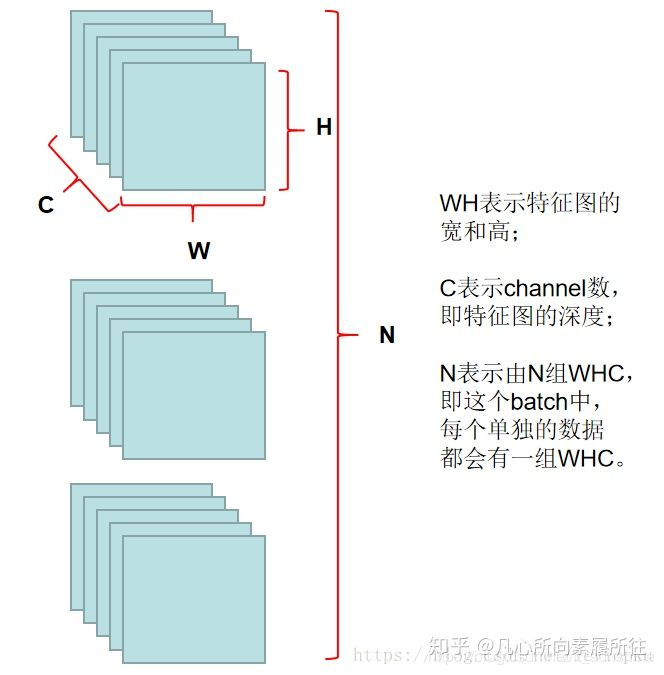
转知乎
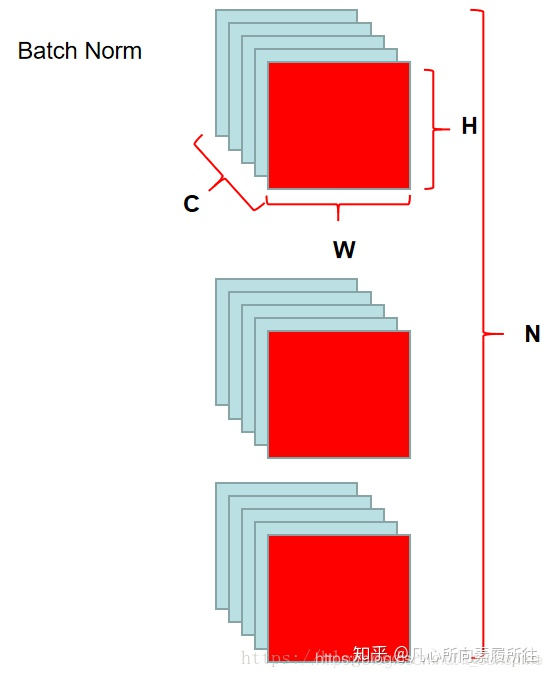
那么BN的归一化范围就是下图红色部分:
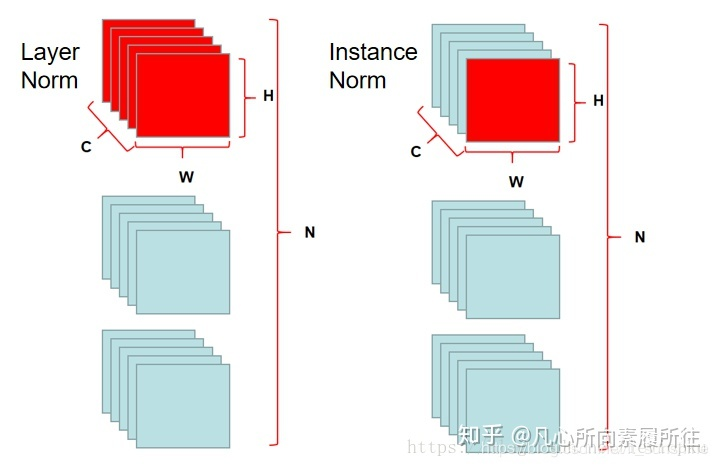
LN和IN如下图
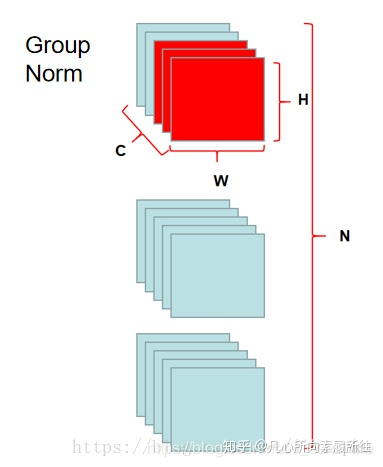
GN如下图
一个比较生动的解释
类比为一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 W 个字符。
- 计算均值时BN 相当于把这些书按页码一一对应地加起来(例如:第1本书第36页,加第2本书第36页…),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字)
- LN 相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”
- IN 相当于把一页书中所有字加起来,再除以该页的总字数:H×W,即求每页书的“平均字”
- GN 相当于把一本 C 页的书平均分成 G 份,每份成为有 C/G 页的小册子,对这个 C/G 页的小册子,求每个小册子的“平均字”


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









