










DSSM是把句子映射为向量,利用距离公式来表示文本间的相似度。DSSM在信息检索,文本排序,问答,图片描述,机器翻译等由广泛应用。
网络结构
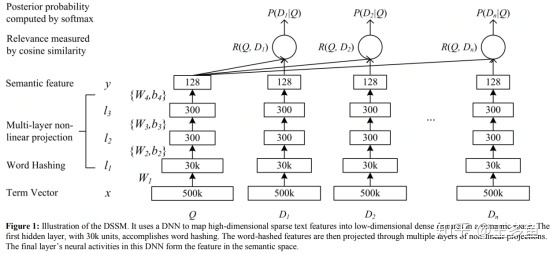
DSSM模型的整体结构图如图所示,Q代表Query信息,D表示Document信息。
(1)Term Vector:表示文本的Embedding向量;
(2)Word Hashing技术:为解决Term Vector太大问题,对bag-of-word向量降维;
(3)Multi-layer nonlinear projection:表示深度学习网络的隐层;

(4)Semantic feature :表示Query和Document 最终的Embedding向量;
(5)Relevance measured by cosine similarity:表示计算Query与Document之间的余弦相似度;即:
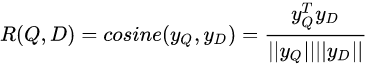
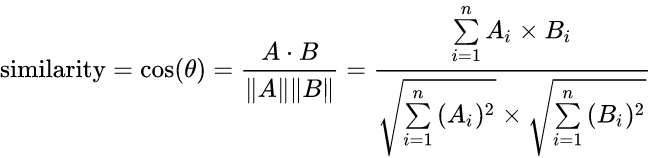
(6)Posterior probability computed by softmax:表示通过Softmax 函数把Query 与正样本Document的语义相似性转化为一个后验概率;即:
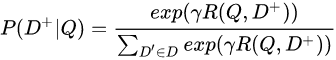

代码解析
#代表查询信息 [batch_size,embedding_size]
query_encoder = build_query_model(features, mode)
#代表正文本信息 [batch_size,embedding_size]
doc_encoder = build_doc_model(features, mode)
with tf.name_scope("fd-rotate"):
# 正文本信息复制一份 注意里面是batch_size个
tmp = tf.tile(doc_encoder, [1, 1])
doc_encoder_fd = doc_encoder
for i in range(FLAGS.NEG):
rand = random.randint(1, FLAGS.batch_size + i) % FLAGS.batch_size
s1 = tf.slice(tmp, [rand, 0], [FLAGS.batch_size - rand, -1])
s2 = tf.slice(tmp, [0, 0], [rand, -1])
# 通过slice从batch_size里面随机选择样本 相当于打乱了顺序
doc_encoder_fd = tf.concat([doc_encoder_fd, s1, s2], axis=0)
# 计算q向量的模长 同样需要复制
query_norm = tf.tile(tf.sqrt(tf.reduce_sum(tf.square(query_encoder), axis=1, keepdims=True)), [FLAGS.NEG + 1, 1])
#计算正负样本的模长
doc_norm = tf.sqrt(tf.reduce_sum(tf.square(doc_encoder_fd), axis=1, keepdims=True))
#复制q矩阵
query_encoder_fd = tf.tile(query_encoder, [FLAGS.NEG + 1, 1])
# 计算q复制后的向量 和 正负样本的 ×成 余弦相似度的分子
prod = tf.reduce_sum(tf.multiply(query_encoder_fd, doc_encoder_fd), axis=1, keepdims=True)
# 计算余弦相似度的分母
norm_prod = tf.multiply(query_norm, doc_norm)
#求的对应位置的相似度
cos_sim_raw = tf.truediv(prod, norm_prod)
# 矩阵转换 转换成为【batch_size ,正负样本数量】
cos_sim = tf.transpose(tf.reshape(tf.transpose(cos_sim_raw), [FLAGS.NEG + 1, -1])) * 20
with tf.name_scope("loss"):
prob = tf.nn.softmax(cos_sim)
# 正样本只在第一个位置
hit_prob = tf.slice(prob, [0, 0], [-1, 1])
loss = -tf.reduce_mean(tf.log(hit_prob))
correct_prediction = tf.cast(tf.equal(tf.argmax(prob, 1), 0), tf.float32)
accuracy = tf.reduce_mean(correct_prediction)
把整个逻辑走下来是这样 batch_size = 4 三个负样本
************** doc_encoder_fd ******************
[[1. 2. 1. 1.]
[2. 3. 2. 2.]
[3. 4. 3. 3.]
[4. 5. 5. 4.]
[1. 2. 1. 1.] #会发现 有可能吧正样本也当做负样本
[2. 3. 2. 2.]
[3. 4. 3. 3.]
[4. 5. 5. 4.]
[3. 4. 3. 3.] # 负样本
[4. 5. 5. 4.]
[1. 2. 1. 1.]
[2. 3. 2. 2.]
[4. 5. 5. 4.] #负样本
[1. 2. 1. 1.]
[2. 3. 2. 2.]
[3. 4. 3. 3.]]
**************** query_norm 模长 ****************
[[ 3.1622777]
[ 7.071068 ]
[11.045361 ]
[15.033297 ]
[ 3.1622777]
[ 7.071068 ]
[11.045361 ]
[15.033297 ]
[ 3.1622777]
[ 7.071068 ]
[11.045361 ]
[15.033297 ]
[ 3.1622777]
[ 7.071068 ]
[11.045361 ]
[15.033297 ]]
*************** doc_norm 模长 *****************
[[2.6457512]
[4.5825753]
[6.557438 ]
[9.055385 ]
[2.6457512]
[4.5825753]
[6.557438 ]
[9.055385 ]
[6.557438 ]
[9.055385 ]
[2.6457512]
[4.5825753]
[9.055385 ]
[2.6457512]
[4.5825753]
[6.557438 ]]
******************** query_encoder_fd Q ************
[[1. 2. 1. 2.]
[3. 4. 3. 4.]
[5. 6. 5. 6.]
[7. 8. 7. 8.]
[1. 2. 1. 2.]
[3. 4. 3. 4.]
[5. 6. 5. 6.]
[7. 8. 7. 8.]
[1. 2. 1. 2.]
[3. 4. 3. 4.]
[5. 6. 5. 6.]
[7. 8. 7. 8.]
[1. 2. 1. 2.]
[3. 4. 3. 4.]
[5. 6. 5. 6.]
[7. 8. 7. 8.]]
************** prod 余弦相似度 分子 ******************
[[ 8.]
[ 32.]
[ 72.]
[135.]
[ 8.]
[ 32.]
[ 72.]
[135.]
[ 20.]
[ 63.]
[ 28.]
[ 68.]
[ 27.]
[ 18.]
[ 50.]
[ 98.]]
****************** norm_prod 余弦相似度 分母 **************
[[ 8.3666 ]
[ 32.4037 ]
[ 72.42927 ]
[136.13228 ]
[ 8.3666 ]
[ 32.4037 ]
[ 72.42927 ]
[136.13228 ]
[ 20.736439]
[ 64.03124 ]
[ 29.223276]
[ 68.89121 ]
[ 28.635641]
[ 18.708286]
[ 50.616196]
[ 98.57991 ]]
*************** cos_sim_raw 比例 *****************
[[0.9561829 ]
[0.9875415 ]
[0.9940733 ]
[0.9916825 ]
[0.9561829 ]
[0.9875415 ]
[0.9940733 ]
[0.9916825 ]
[0.96448576]
[0.9838947 ]
[0.9581404 ]
[0.98706347]
[0.9428809 ]
[0.9621405 ]
[0.9878261 ]
[0.9941174 ]]
*************** cos_sim 转置 reshape成结果 我们只需要人为一个维是正样本就可以* ****************
[[0.9561829 0.9561829 0.96448576 0.9428809 ]
[0.9875415 0.9875415 0.9838947 0.9621405 ]
[0.9940733 0.9940733 0.9581404 0.9878261 ]
[0.9916825 0.9916825 0.98706347 0.9941174 ]]
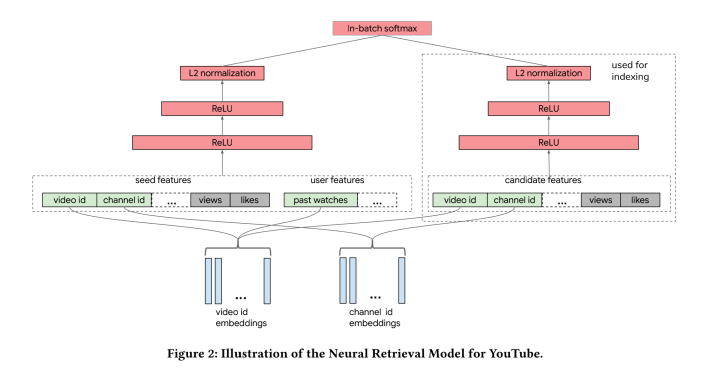
推荐中双塔模型最后一层为什么要用L2正则?


















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









