







 本文讨论了在评估大模型时,如何使用opencompass工具处理客观和主观问题,涉及expression-based方法的应用、数据污染的影响以及如何通过TURBOMINDAPI进行评测。实践中遇到的错误和解决步骤也进行了分享。
本文讨论了在评估大模型时,如何使用opencompass工具处理客观和主观问题,涉及expression-based方法的应用、数据污染的影响以及如何通过TURBOMINDAPI进行评测。实践中遇到的错误和解决步骤也进行了分享。
学习:https://www.bilibili.com/video/BV1Gg4y1U7uc/?spm_id_from=333.788&vd_source=d5e90f8fa067b4804697b319c7cc88e4
文档:https://github.com/InternLM/tutorial/blob/main/opencompass/opencompass_tutorial.md
repo: https://github.com/open-compass/opencompass
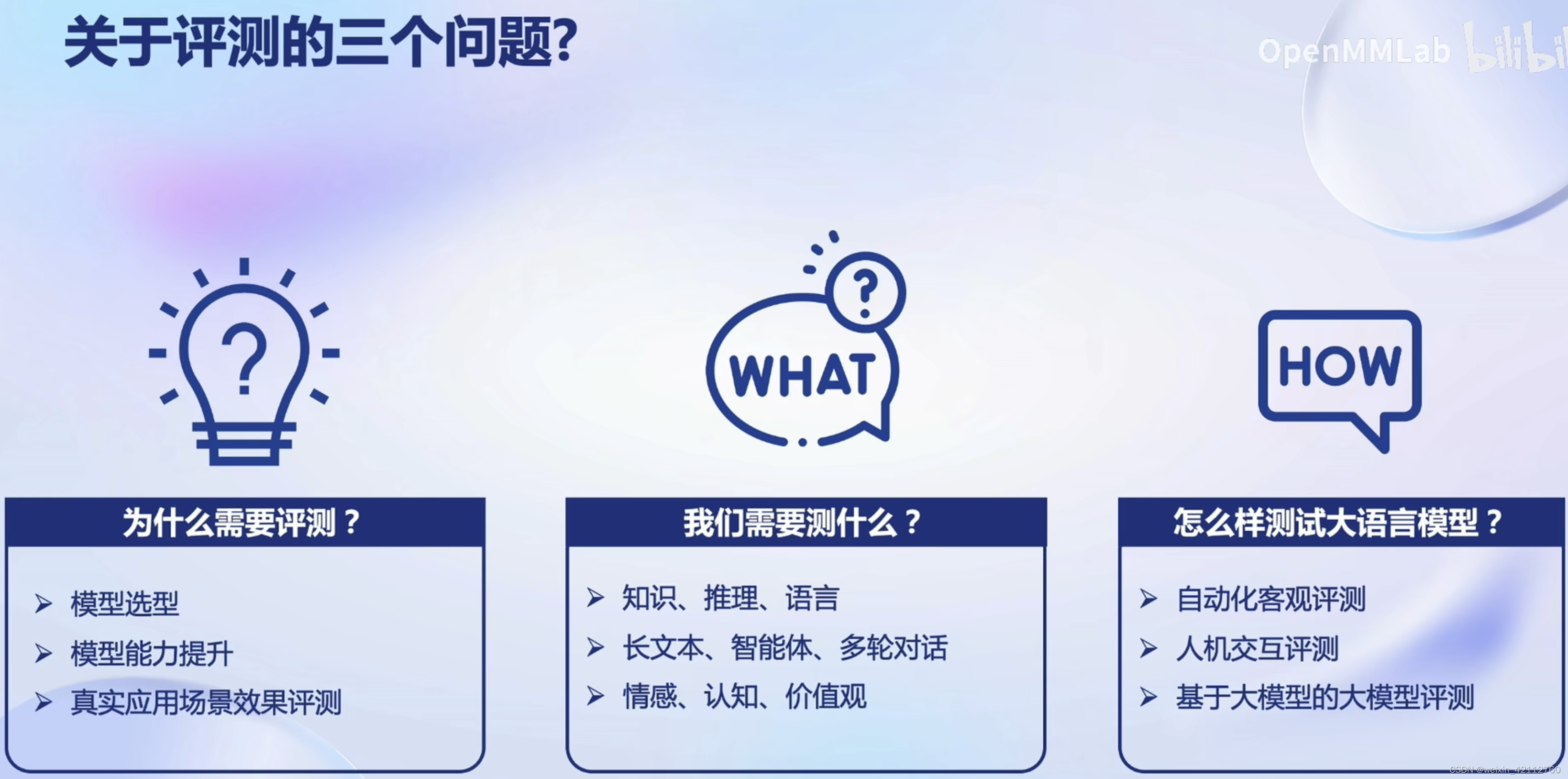
了解大模型评测,完成作业


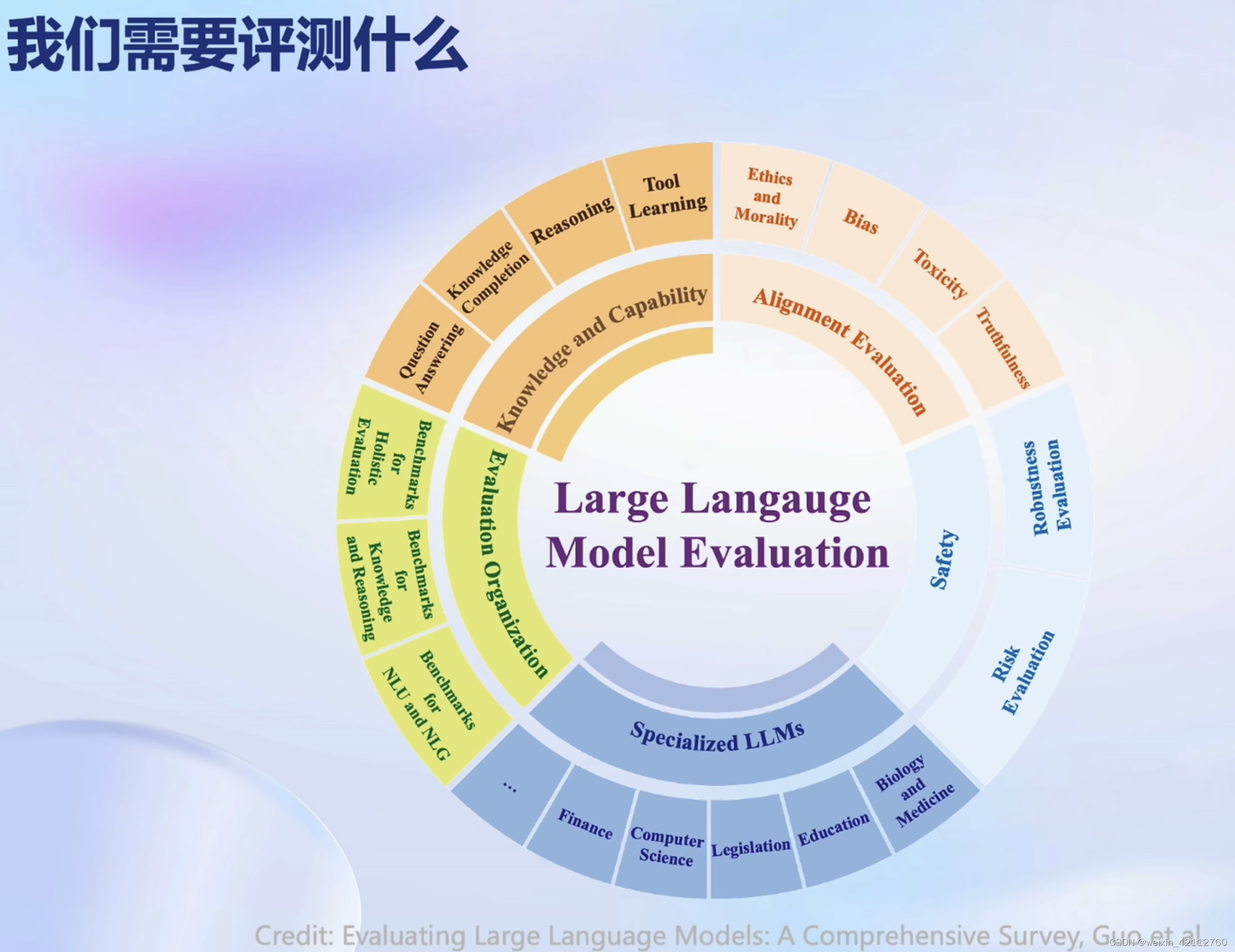


客观题基于rollbase。回答形式不一样,但是客观上都是对的。基于表达式的方法提取关键词,对了就是客观正确的。

主管题就是要靠人工打分,用模型评价。用GPT4自动化工具去评价。

很多问题其实是一个意思,修改prompt的形式,如果答得不好说明鲁棒性差。



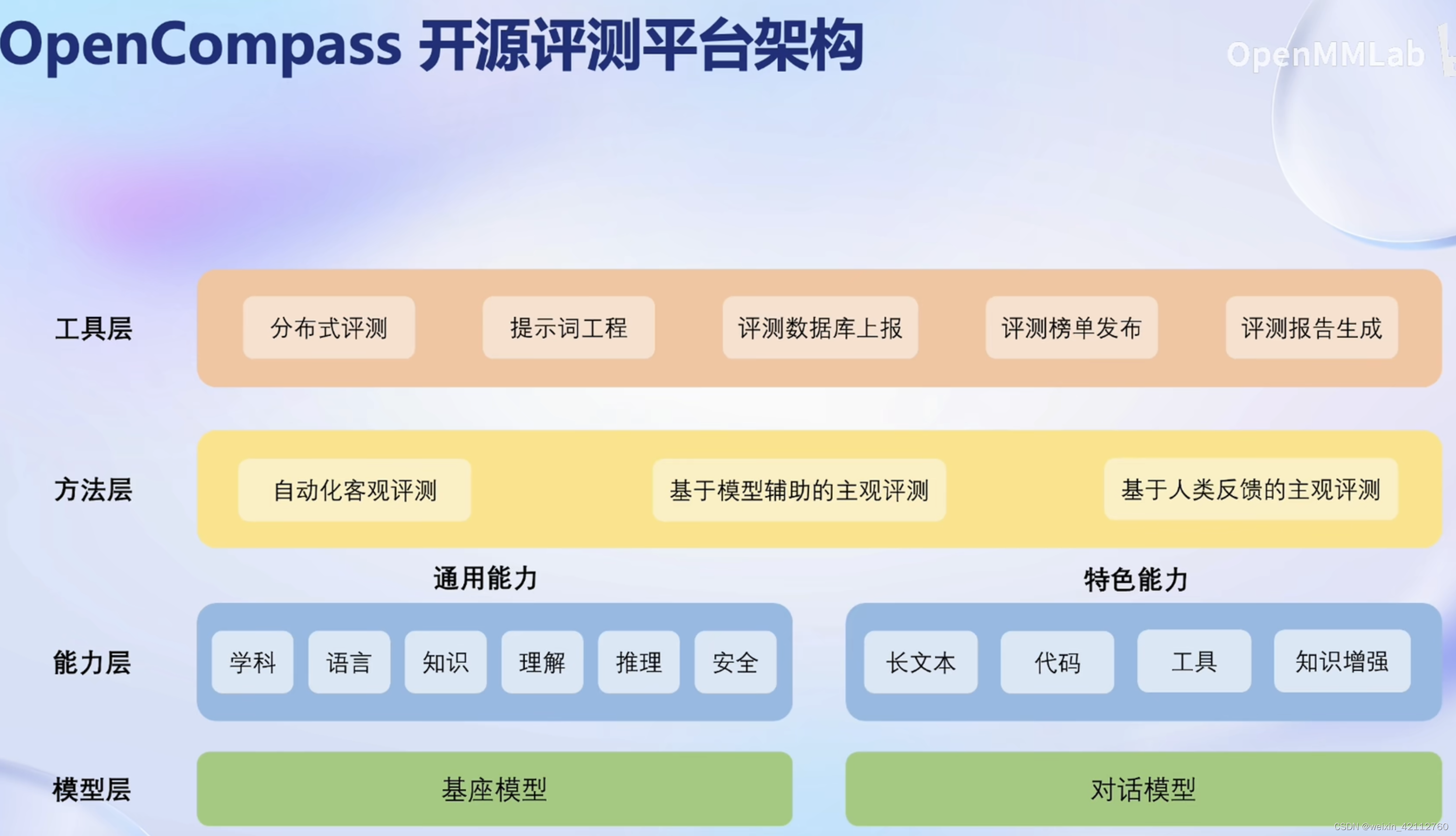
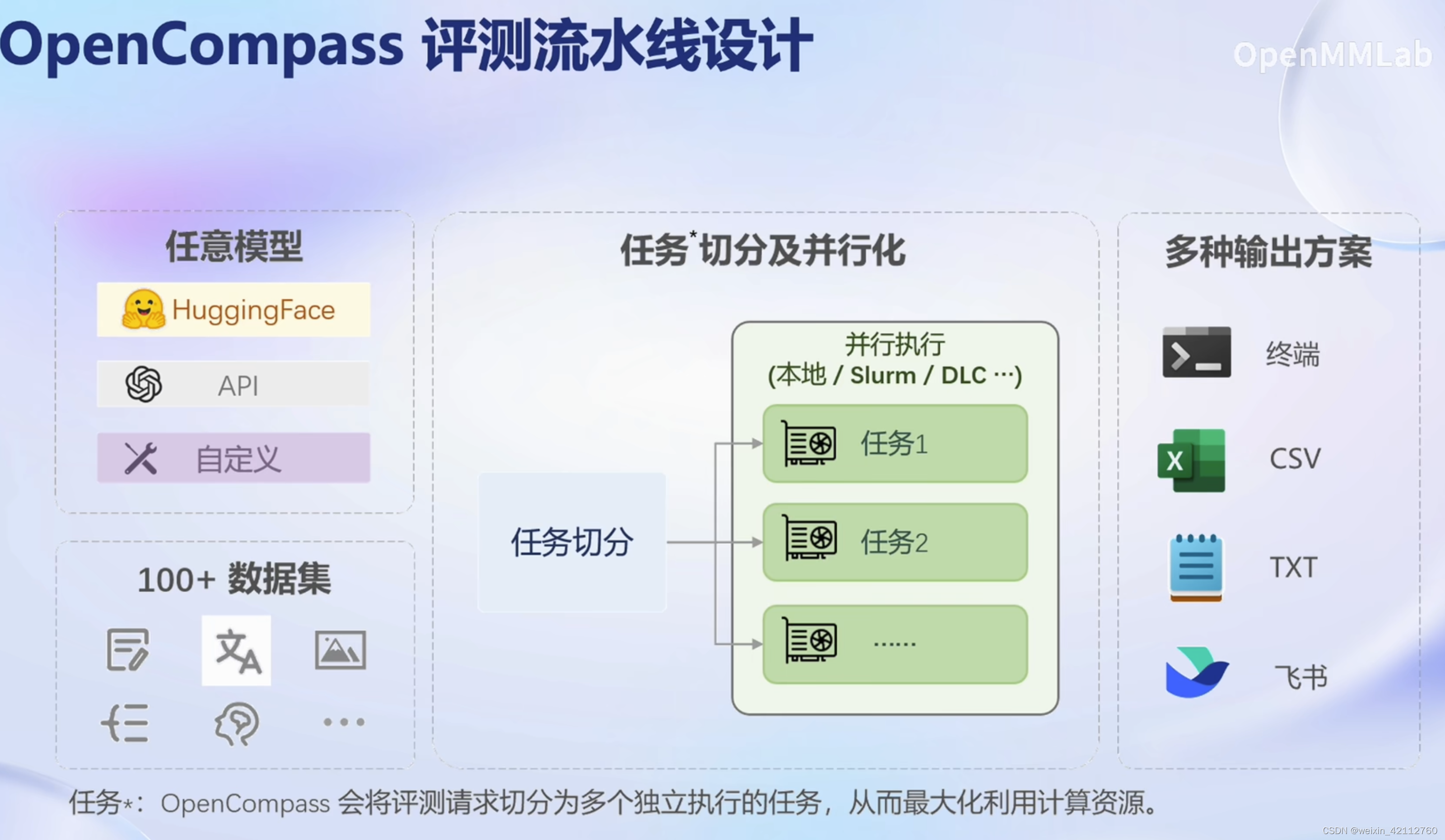
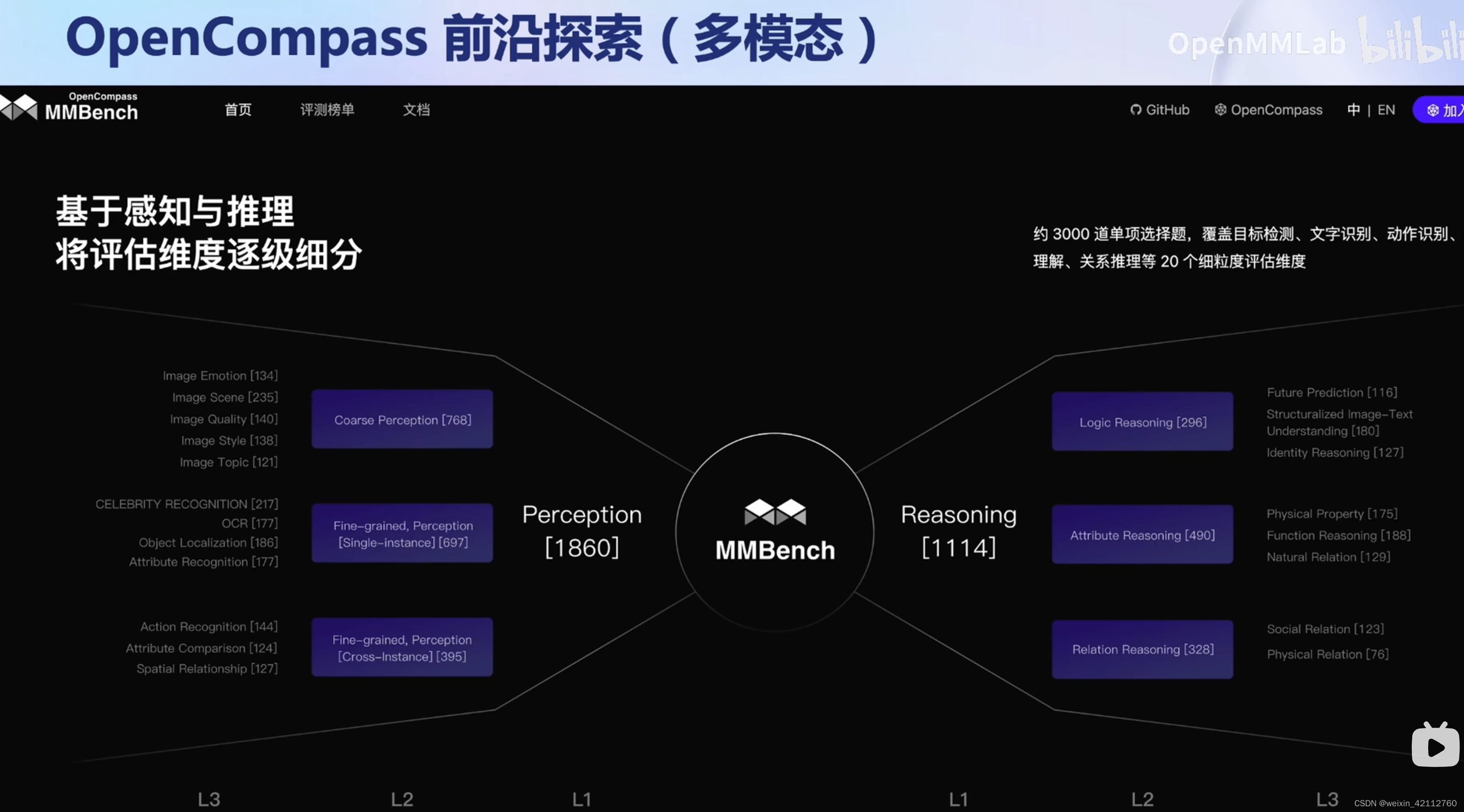
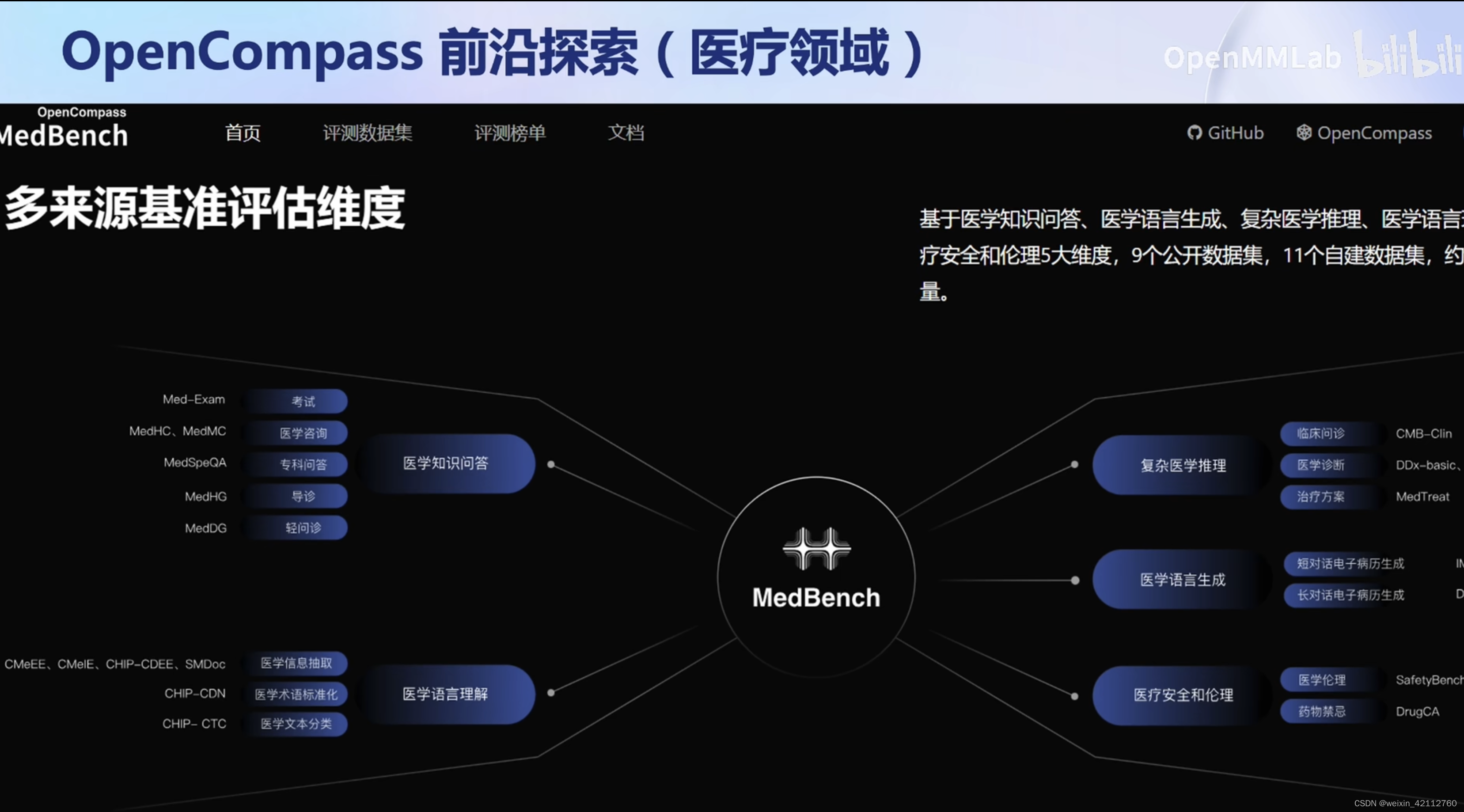
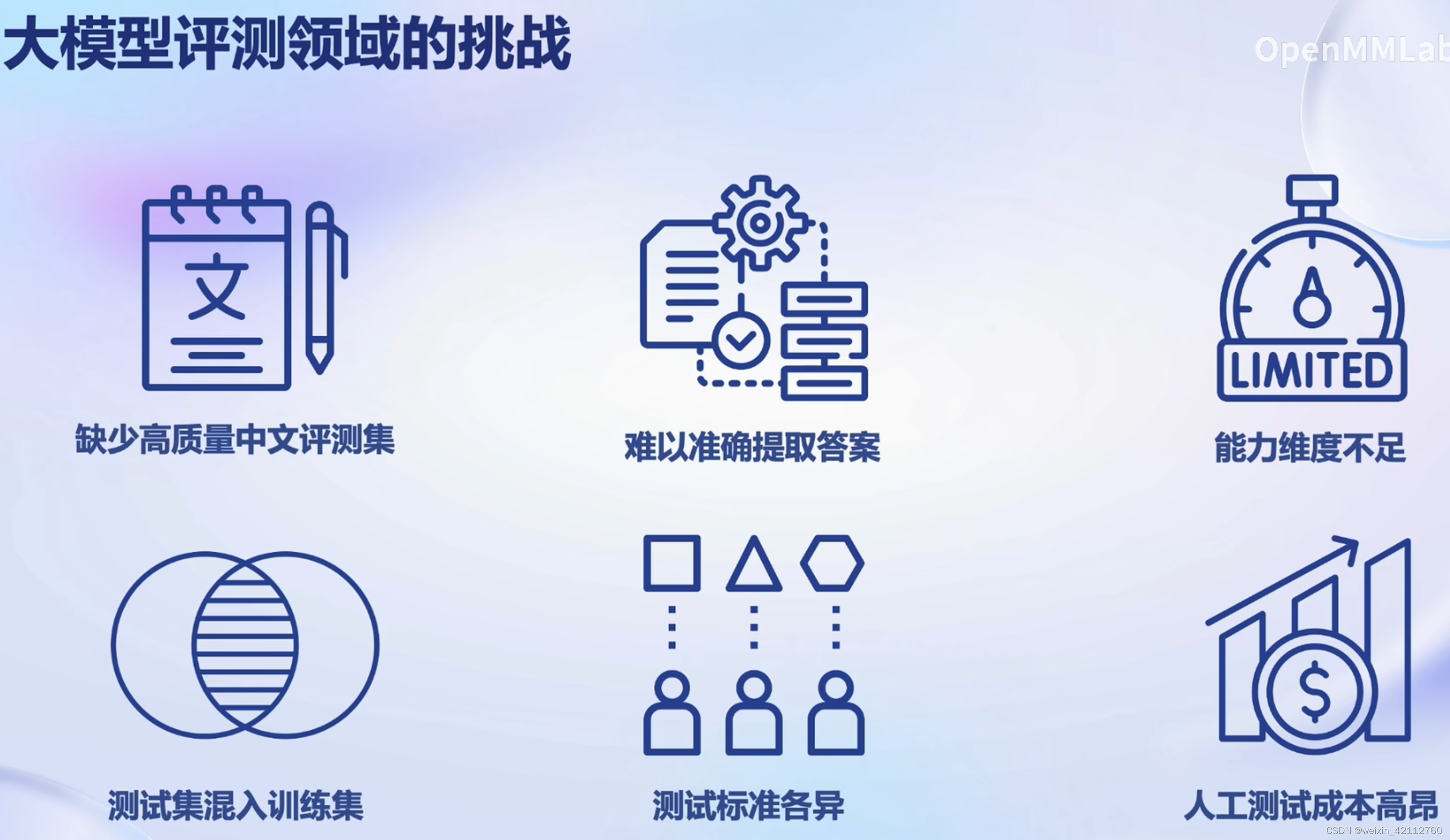
【测试集混入训练集】数据污染问题,导致精确度虚高。有望使用工具进行检测。
实践
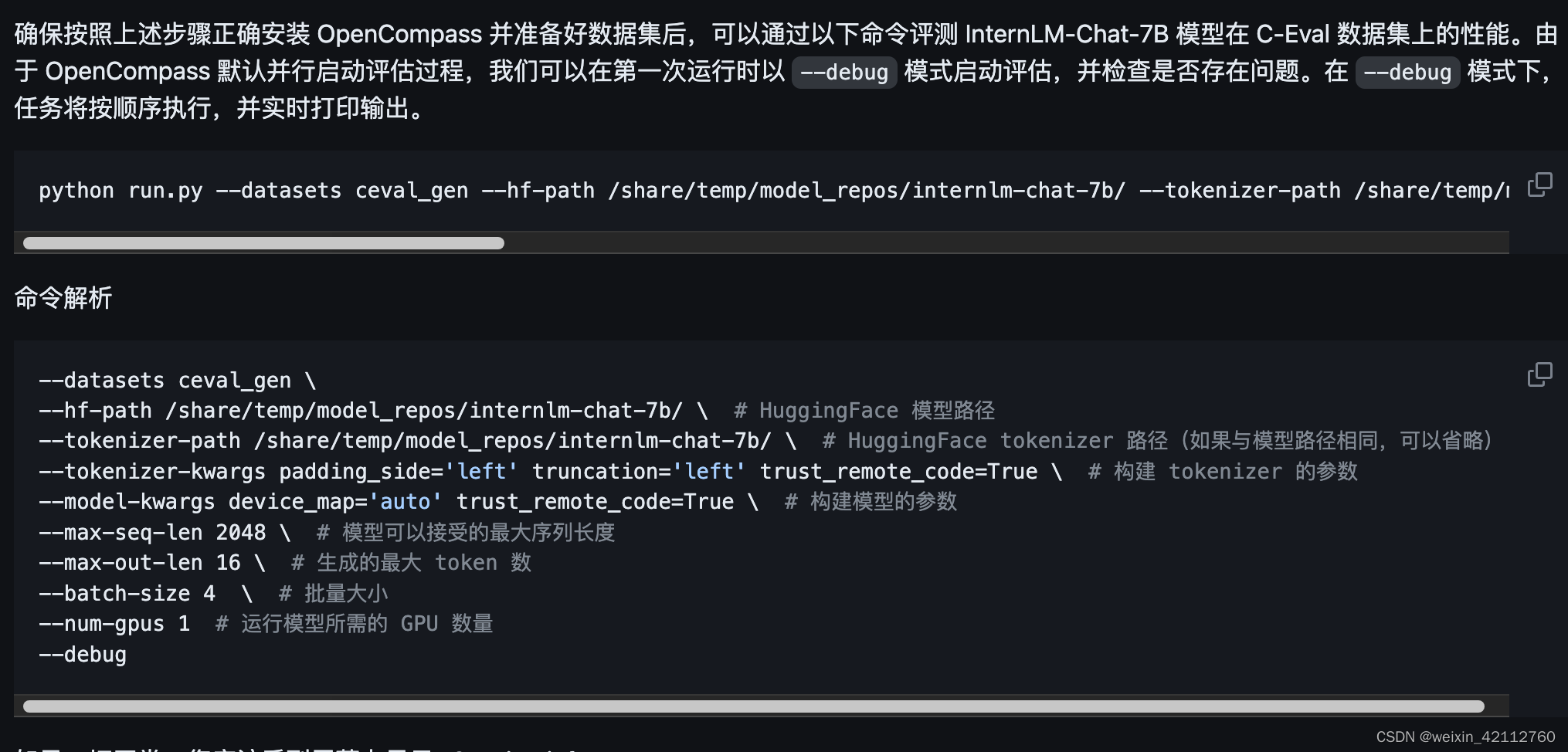
发现错误:
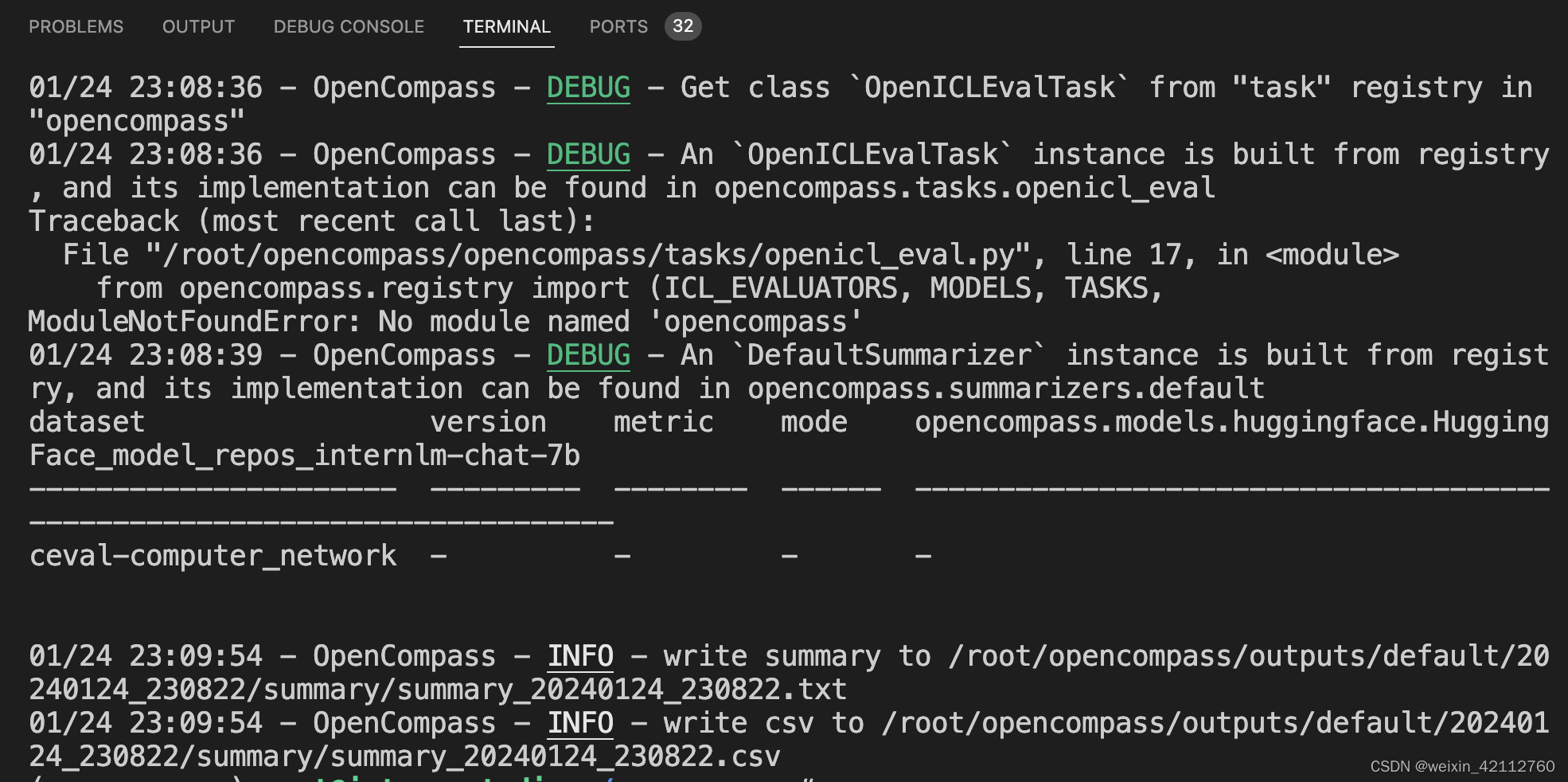
ModuleNotFoundError: No module named ‘opencompass’
发现安装opencompass的时候需要:source activate opencompass
conda create --name opencompass --clone=/root/share/conda_envs/internlm-base
source activate opencompass # 不是conda
git clone https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
重新进入环境并且pip install -e .

成功得到评测结果:
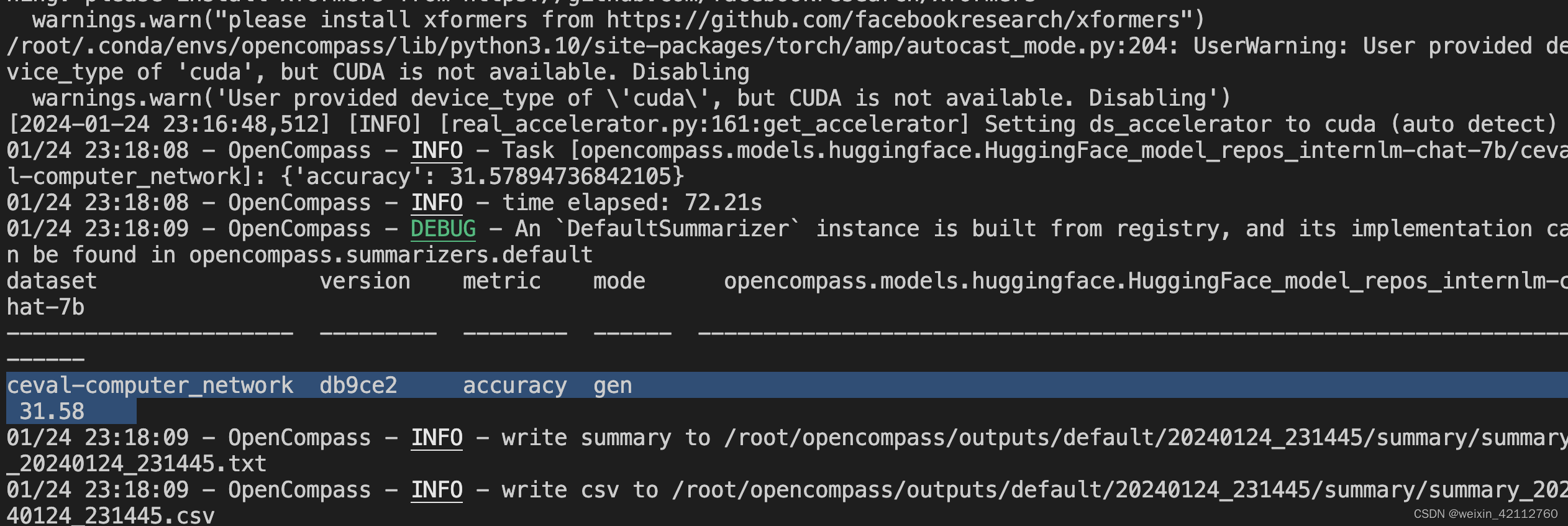
-
主观测评需要使用另外一个模型对当前被测模型进行评价:本次案例使用的是aligenbench
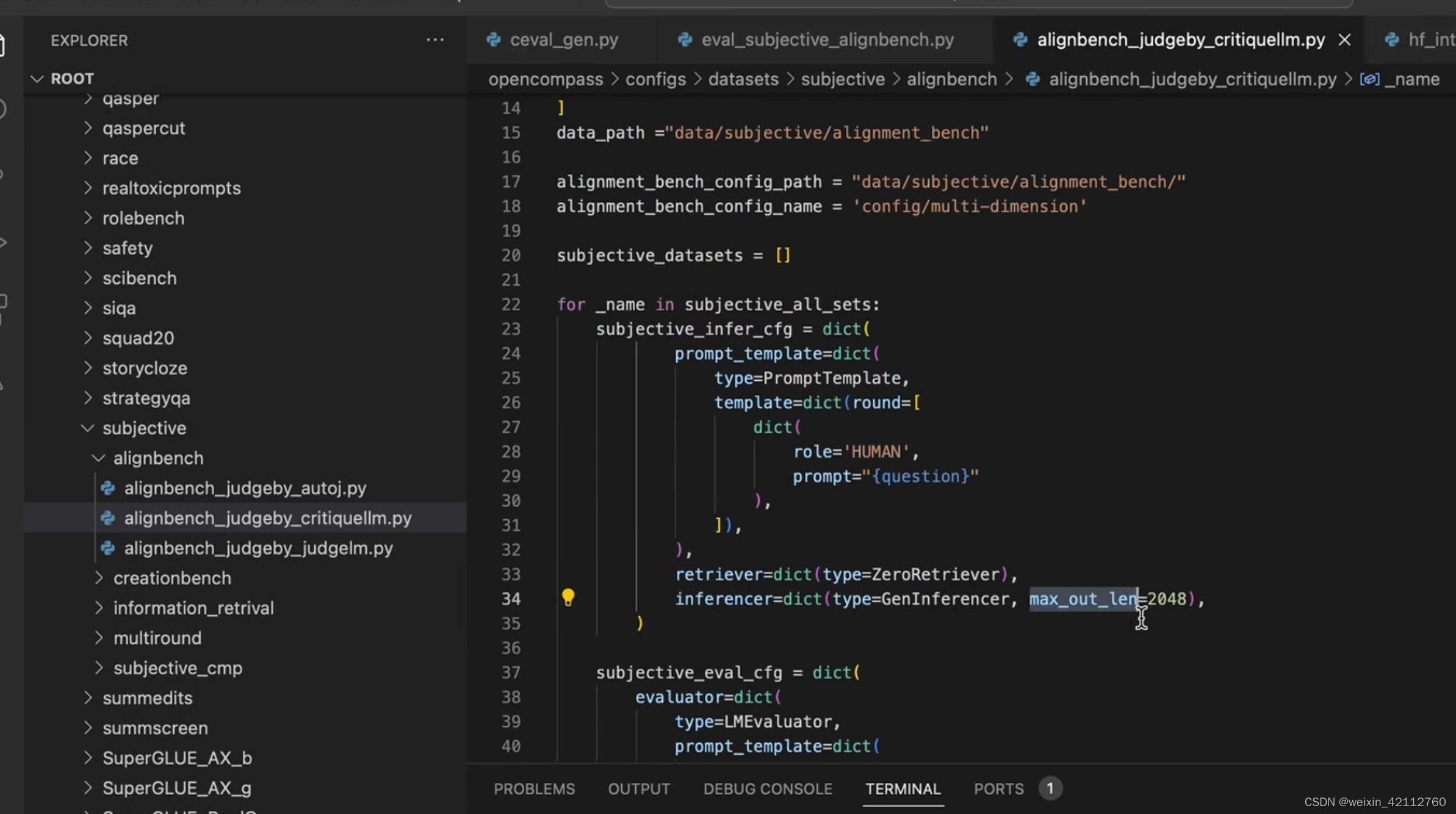
-
datasets可以设置最大输出长度,不用每个模型都针对性的调整,datasets里面的值会覆盖掉models里面设置的。
-
断点续存可以在配置文件后加入:
--reuse latest

-
主观推理不能太归一,这样的话表达反而不好,这时候可以额外加入generation—kwargs参数中的do—sample=True
以及其他的相关参数:
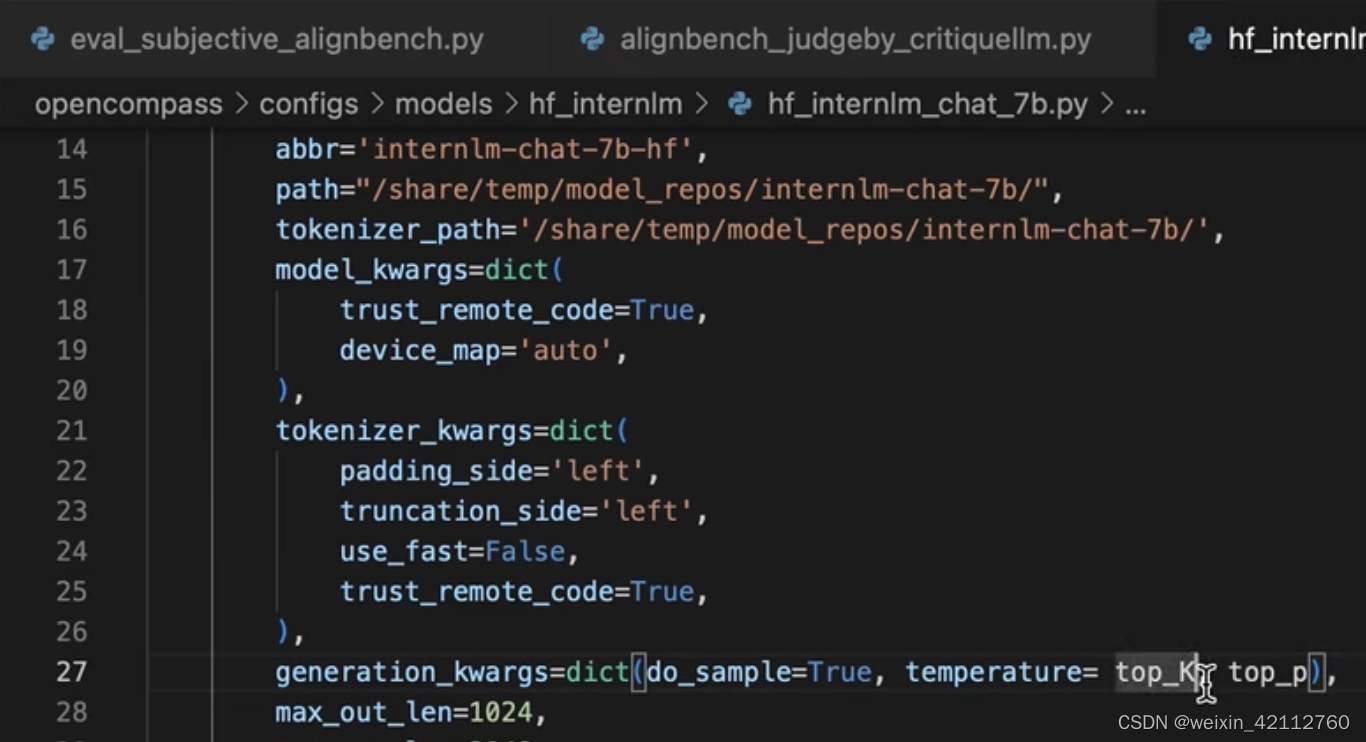
OpenCompass 支持分别通过 turbomind python API 评测数据集。
准备好测试配置文件configs/eval_internlm_turbomind.py,但是结果好像并不如意。待修正~

















 1538
1538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









