







笔记摘自课程内容。
机器翻译和数据集
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
数据预处理
数据清洗主要去除多余字符以及特殊字符(通常指计算机无法编码)。其次是进行分词,将字符串组成由单词构成的列表,然后再建立词典,即单词id组成的列表。
Encoder-Decoder部分。encoder:输入到隐藏状态。decoder:隐藏状态到输出。encoder的输出是decoder的初始输入。
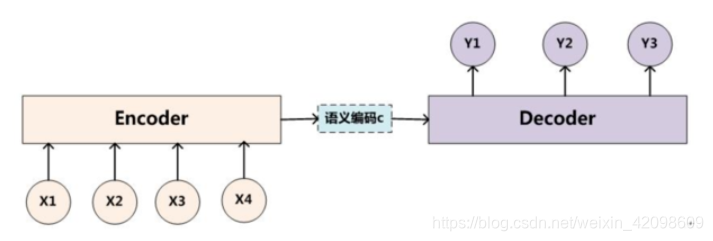
Sequence to Sequence模型
SeqtoSeq模型也是基于encoder-decoder框架的。encoder框架输入的是固定长度的句子序列(长了截断,短了补足),输出一个固定长度的语义编码,这个语义编码作为decoder的初始输入。
在训练模型中,decoder每个时间步都输入一个新的词,但在预测时,是将上一个时刻的输出作为下一个时刻的输入。
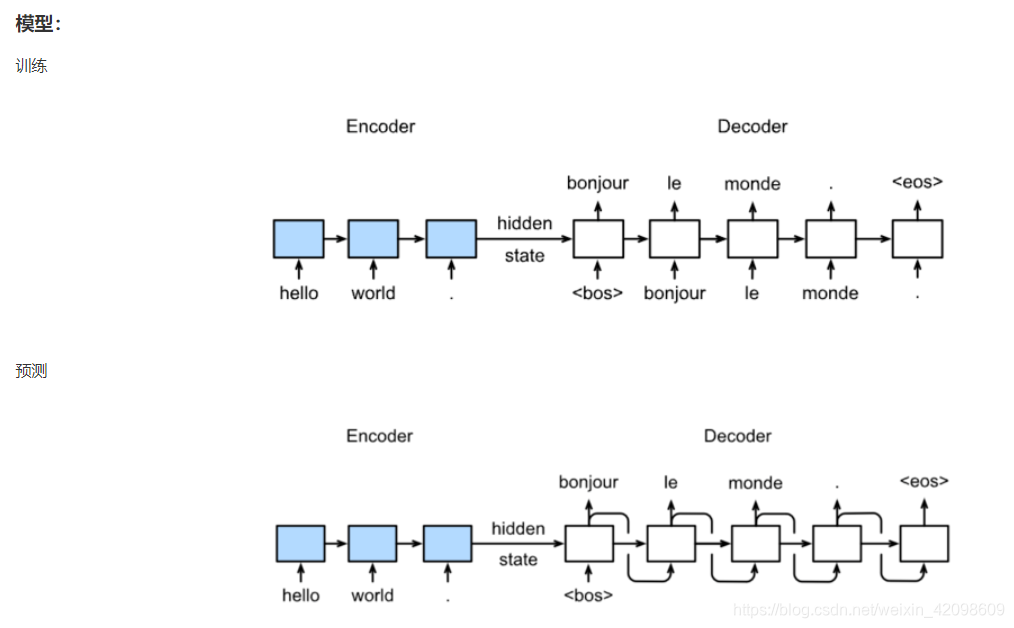
encoder-decoder框架解决了输入序列和输出序列不等长的问题,但也存在缺陷。decoder的预测结果,很依赖于encoder输出的语义编码,因此ecoder框架采用的模型本身的缺陷都会影响语义编码的准确性,进而影响decoder的准确率。
Beam Search
直接上图,这个比较好理解。
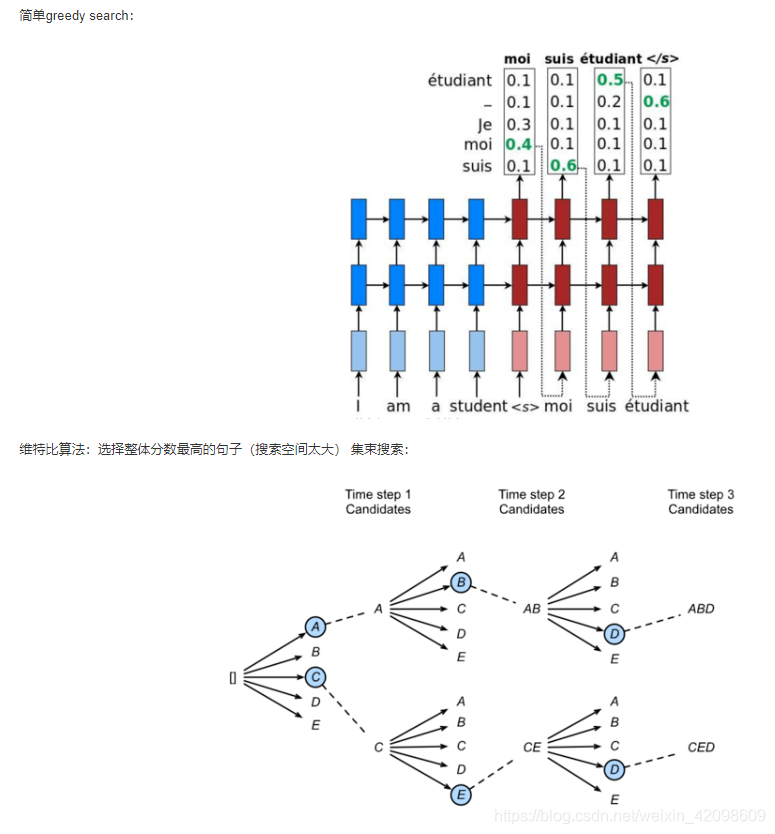
它的基本思想就是,decoder每一步输出都是当前的最优解,也就是局部最优解,它不一定是全局最优解。为了缓解这个问题,Bream Search选取当前两个得分最高的解。问题也显而易见,参数量变多了。
注意力机制和Seq2seq模型
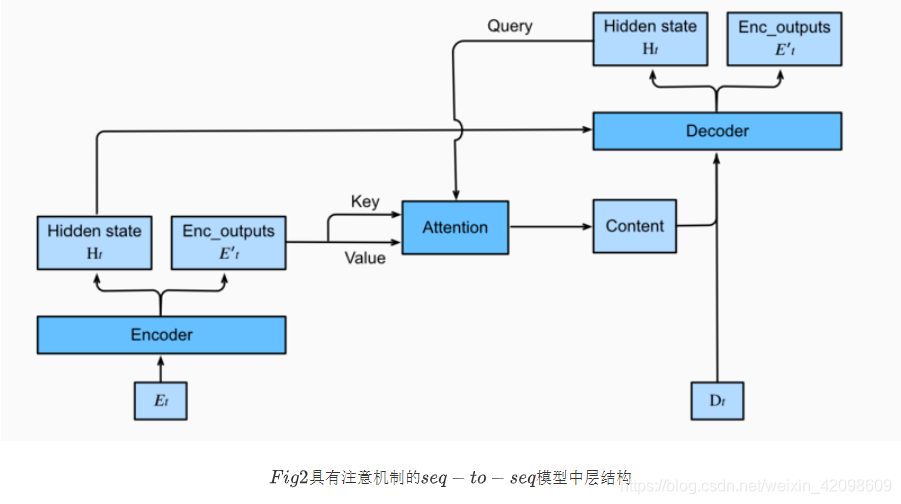
前面的SeqtoSeq,decoder每个时刻的输出依赖的只有一个语义编码,但事实上,decoder每个时刻的输出,应该与当前输出的上下文有关系,引入attention机制,相当于在decoder的时候,每个时刻都会从encoder中挑选出与之相关的上下文信息,然后来进行输出预测。
Transformer模型
关于transformer模型,参考这篇Transformer模型详解。

















 206
206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









