







题目描述:
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
题目分析:
参考代码:
class LRUCache {
/** 定义一个Node结点 **/
class Node{
private int key;
private int value;
private Node pre;
private Node next;
public Node(int key, int value){
this.key = key;
this.value = value;
}
}
/** 定义一个DoubleList双链表**/
class DoubleList{
private Node head;
private Node tail;
private int size;
public DoubleList(){
this.head = new Node(0, 0);
this.tail = new Node(0, 0);
this.size= 0;
this.head.next = tail;
this.tail.pre = head;
}
public Node removeLast(){
if(tail.pre == head)return null;
Node last= tail.pre;
remove(last);
return last;
}
public void addFirst(Node node){
node.next = head.next;
node.pre = head;
head.next.pre = node;
head.next = node;
size ++;
}
public void remove(Node node){
node.pre.next = node.next;
node.next.pre = node.pre;
node.next = null;
node.pre = null;
size--;
}
private int size(){
return this.size;
}
}
private DoubleList doubleList;
private Map<Integer, Node> map;
private int capacity;
public LRUCache (int capacity){
this.capacity = capacity;
doubleList = new DoubleList();
map = new HashMap<>();
}
public int get(int key){
if(!map.containsKey(key))return -1;
int val = map.get(key).value;
put(key, val);
return val;
}
public void put(int key, int value){
Node node = new Node(key, value);
if(map.containsKey(key)){
doubleList.remove(map.get(key));
doubleList.addFirst(node);
map.put(key, node);
}
else{
if(capacity == doubleList.size()){
Node last = doubleList.removeLast();
map.remove(last.key);
}
doubleList.addFirst(node);
map.put(key, node);
}
}
}
小结:
HashMap中的各个变量大致如下: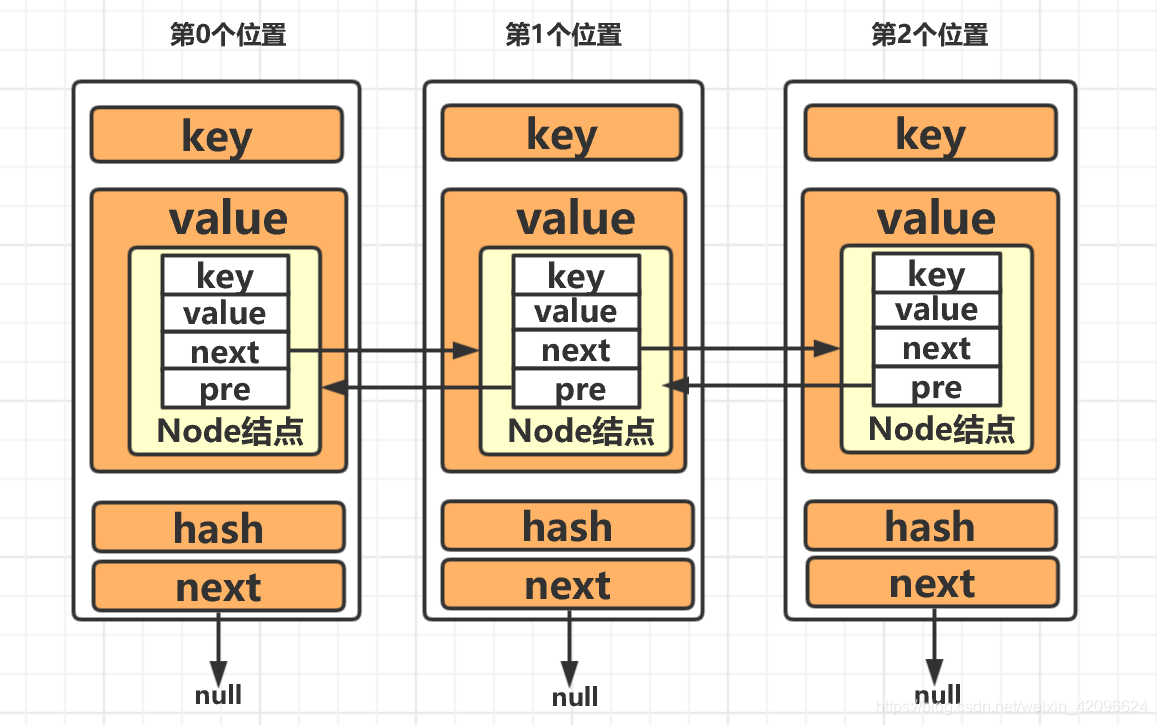
可以看到,删除了Node结点,还要删除HashMap中的key对应的元素。
Node结点也存储key,在利用removeLast()删除尾部Node结点后,还要删除对应的HashMap中的结点, 那怎么删除呢?根据key删除,可是key我们不知道,我们只知道刚刚删除的是双链表中最后一个结点(tail的前驱结点),所以除了HashMap中存储key以外,这里让Node结点也存储key,这样既可以删除Node结点,又可以根据Node中的key来删除HashMap中对应的键为key的结点。

















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









