







 本文探讨了属性规约在大数据分析中的应用,旨在通过合并或删除不相关属性降低数据维度,同时保持概率分布的相似性。主要内容包括属性规约的基本概念,重点介绍了主成分分析这一常用方法,并提供了相应的Python代码实现。
本文探讨了属性规约在大数据分析中的应用,旨在通过合并或删除不相关属性降低数据维度,同时保持概率分布的相似性。主要内容包括属性规约的基本概念,重点介绍了主成分分析这一常用方法,并提供了相应的Python代码实现。
属性规约通过属性合并或者删除不相关的属性来减少数据维数,寻找出最小的属性子集并确保数据子集的概率分布尽可能地接近原来数据集的概率分布。
1.常用方法
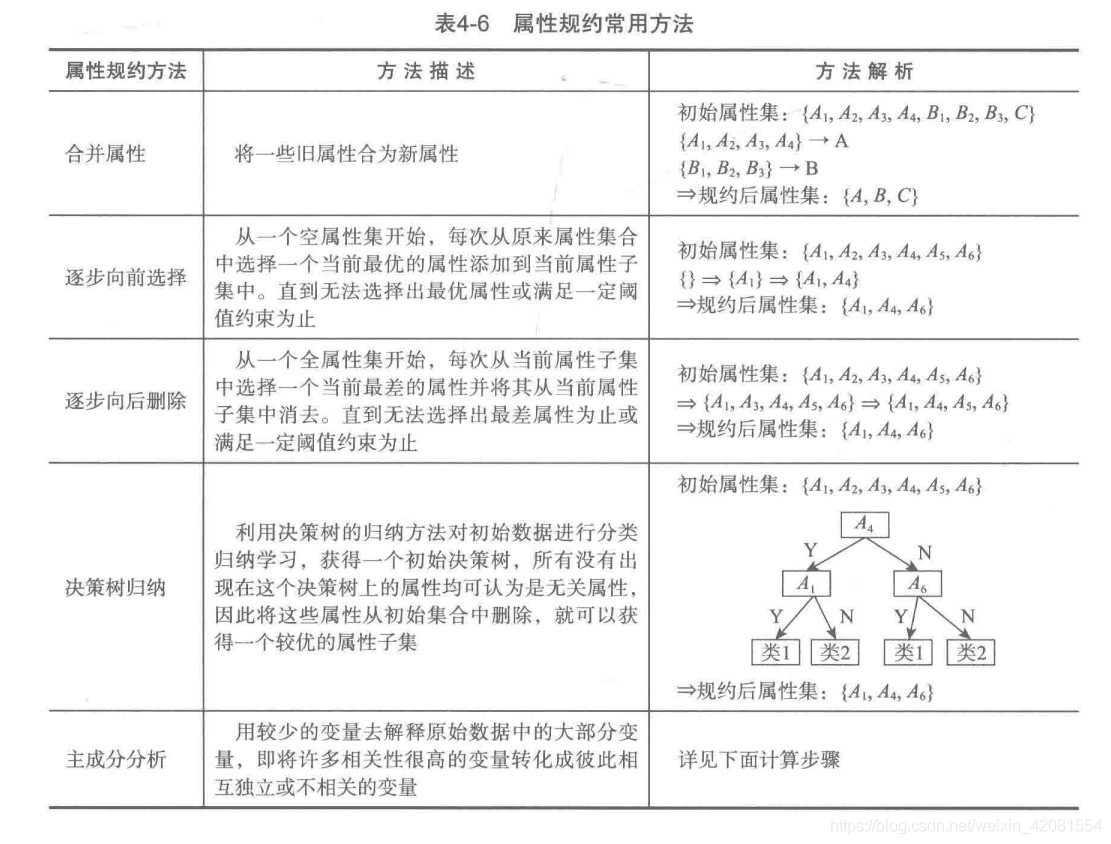
2.主成分分析:

3.代码实现
#-*- coding: utf-8 -*-
#主成分分析 降维
import pandas as pd
#参数初始化
inputfile = 'D:/Code/Need/principal_component.xls'
outputfile = 'D:/Code/Need/dimention_reducted.xls' #降维后的数据
data = pd.read_excel(inputfile, header = None) #读入数据
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(data)
pca.components_ #返回模型的各个特征向量
pca.explained_variance_ratio_ #返回各个成分各自的方差百分比
结果:
pca.components_
Out[2]:
array([[ 0.56788461, 0.2280431 , 0.23281436, 0.22427336, 0.3358618 ,
0.43679539, 0.03861081, 0.46466998],
[ 0.64801531, 0.24732373, -0.17085432, -0.2089819 ,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2044
2044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









