






大模型微调实操手册
本实操⼿册记录基于Qwen2.5-7B-Instruct⼤模型进⾏微调
1、搭建环境
选择 AutoDL的 4090 云 GPU 做为训练测试环境。因为独⽴部署⾃⼰训练的⼤模型, 4090 是⽬前性价⽐最⾼的⽅案
1.1注册AutoDL并进⾏实名认证
AutoDL官⽹链接:https://www.autodl.com/
根据平台要求进⾏账号注册,注册成功登录平台进⾏实名认证,按照官⽅要求进⾏认证即可
1.2 挑选GPU
在官⽹⾸⻚点击算⼒市场菜单进⼊并进⾏GPU选择,参考如下截图配置进⾏选择即可(参考)

1.3 创建实例
GPU选择确定后,单击n卡可租进⼊创建实例⻚⾯,并按照如下截图进⾏配置其中,镜像选择使⽤开源的社区镜像
这⾥推荐选择 agiclass/fine-tuning-lab/finetune-lab-v8
并选择最新版本,社区版本镜像中已经配置好了微调所需要依赖包环境,⾮常⽅便使⽤

实例创建成功如下截图所示,当状态为运⾏中时,表示创建完成,并且开始计费如果要暂停计费,请点击关机。
下次需要使⽤时,再点击开机,这⾥需要注意官⽅相关的限制策略

2、微调前⼯作
2.1 连接实例
这⾥推荐⼤家使⽤SSH客户端软件远程登录到服务器,
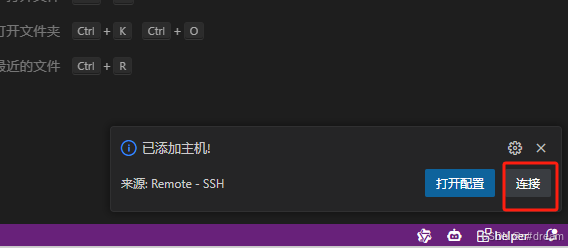
并同时连接SFTP服务进⾏⽂件的上传下载或者直接使用VScode进行远程连接(方便启动微调服务进行本地测试)连接信息可在如下截图所示的地⽅获取

2.1.1使用本地SSH客户端连接
我的环境是windows,使用的工具为FinalShell,Mac系统⼯具推荐为Termius

配置成功后,如下截图所示

注意官方的目录说明
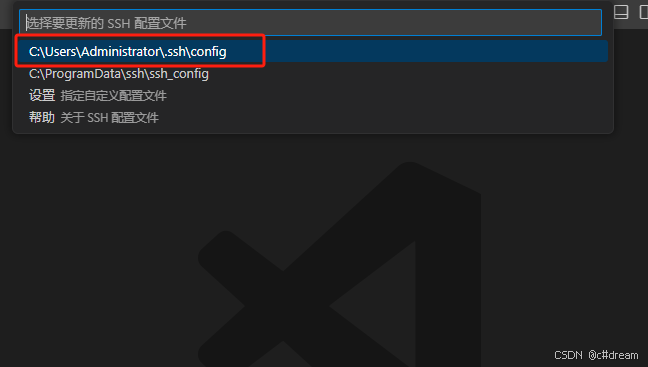
2.1.2 使用VSCode工具连接
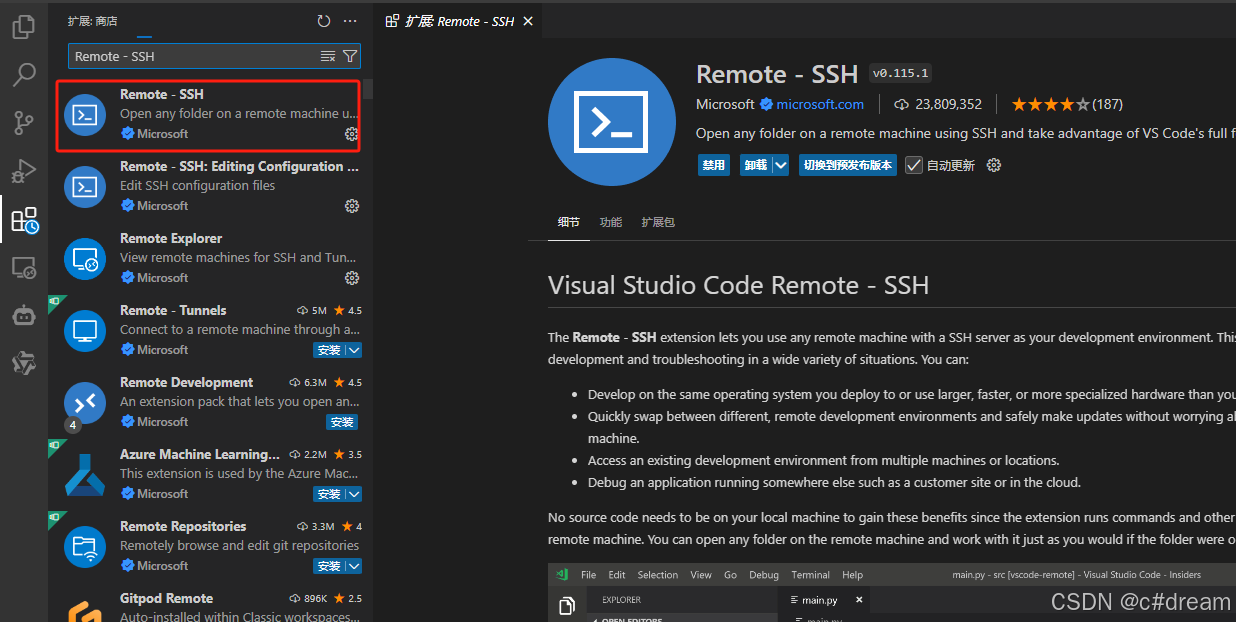
首先在VSCode扩展中下载Remote - SSH
<img src="https://i-blog.csdnimg.cn/direct/b7564023cf7745c8acf67824461246b5.png" width="800px" height=400 />
<br/>
<br/>
<br/>
<img src="https://i-blog.csdnimg.cn/direct/78848ae3daae41e5821d4bb92705e0c1.png" width="800px" height=400 />
<img src="https://i-blog.csdnimg.cn/direct/fc3640995fba4d8394f116bc85d3f8bb.png" width="800px" height=400 />
<br/>
<br/>
<br/>
<br/>
<br/>
<br/>
<img src="https://i-blog.csdnimg.cn/direct/8d3b62c9b6d049c38a31626f42888105.png" width="800px" height=400 />
2.2 下载预训练模型
这⾥所需的预训练模型Qwen2.5-7B-Instruct从HuggingFace下载,考虑到国内访问HuggingFace⽐较慢,这⾥使⽤hfmirror,官⽹链接 https://hf-mirror.com/Qwen/Qwen2.5-7B-Instruct

执⾏如下命令⾏进⾏模型下载:
cd /root/autodl-tmp
git lfs install
git clone https://hf-mirror.com/Qwen/Qwen2.5-7B-Instruct
执⾏完成后,耐⼼等待下载完成即可,这个过程需要一会时间
下载完成后,查看⽂件
cd Qwen2.5-7B-Instruct
rm -rf .git #清除掉.git⽬录,避免数据盘空间不⾜

3、开始微调
3.1下载LLaMA-Factory并配置环境
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
#激活虚拟环境
conda activate llama_factory
cd LLaMA-Factory
#安装依赖
pip install -e '.[torch,metrics]'
3.2运行LLaMA-Factory可视化界面
需要注意的是,本次及后续所有的程序的入口都是 llamafactory-cli,
通过不同的参数控制现在是实现什么功能,比如现在是想使用网页版本直接推理,所以第一个参数设置为webchat, 所有的可选项包括
| 动作参数枚举 | 参数说明 |
|---|---|
| version | 显示版本信息 |
| train | 命令行版本训练 |
| chat | 命令行版本推理chat |
| export | 模型合并和导出 |
| api | 启动API server,供接口调用 |
| eval | 使用mmlu等标准数据集做评测 |
| webchat | 前端版本纯推理的chat页面 |
| webui | 启动LlamaBoard前端页面,包含可视化训练,预测,chat,模型合并多个子页面 |
llamafactory-cli webui

注意:用VSCode可以直接在本地做转发端口打开,如果用的SSH软件连接操作,需要到AutoDL控制台的自定义服务打开,下图所示

运行成功,如下图所示

①切换语言,默认为英文
②模型的名称,输入Qwen2-7B-Instruct,如果出现Qwen2-7B-Chat也是一样的
③本地要训练的模型全路径,即2.2下载的位置
④默认为lora
⑤检查点路径表示每训练一次就会生成一个检查点,初次训练为空。一个检查点+原始模型等于本次微调的结果模型
⑥数据集为训练数据集,详情介绍参考3.3
⑦选中的数据集预览功能,可以多选
⑧训练轮次,默认设置20,可以自己实验增加
上面设置好之后,按照下面这个图标注的顺序进行点击即可开始微调

3.3训练集设置
在下载LLaMA-Factory源码后,进入data目录即可看到实例的训练数据集。
自定义数据集请访问官方文档进行学习

3.3.1添加数据集文件
将自定义好的数据集放到/root/autodl-tmp/LLaMA-Factory/data下面
并打开/root/autodl-tmp/LLaMA-Factory/data/c4_demo.json进行添加,如下图所示

注意:不同的数据集格式添加配置不一样,详情以官方文档为准
3.4查看显存占用
3.4.1 显示一次当前GPU占用情况
nvidia-smi

3.4.2 每秒刷新一次并显示
nvidia-smi -l

3.4.3 watch命令(推荐)
watch -n 5 nvidia-smi

4.启用外部记录面板(wandb)
此过程针对需要记录多次实验结果,如果不需要记录可以不操作
4.1登录注册
在多次实验中,需要记录每一次实验的正确率,在这里推荐使用wandb
进入到wandb官网进行注册
成功后进入到下面页面,按照提示安装wandb包即可

4.2LLaMA-Factory启动记录
4.2.1在yaml文件添加配置

4.2.2 在LLaMA-Factory可视化界面选择启用外部记录面板

多次运行结果如下图



















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









