







 本文详细介绍了逻辑回归,一种用于二分类问题的分类算法。首先,解释了逻辑回归如何通过线性模型结合sigmoid函数将连续值转化为离散概率。接着,讨论了逻辑回归的损失函数,该函数衡量预测概率与实际类别之间的差距。最后,探讨了使用梯度下降法优化损失函数以求解模型参数的方法。
本文详细介绍了逻辑回归,一种用于二分类问题的分类算法。首先,解释了逻辑回归如何通过线性模型结合sigmoid函数将连续值转化为离散概率。接着,讨论了逻辑回归的损失函数,该函数衡量预测概率与实际类别之间的差距。最后,探讨了使用梯度下降法优化损失函数以求解模型参数的方法。
逻辑回归
逻辑回归(Logistic Regression),虽然名字中有“回归”两个字,但其实是一种分类算法,可以用来处理二分类或多分类问题。逻辑回归又被称为对数几率回归,它是一种广义线性模型。已知线性回归 z=ωTx z = ω T x ,其中 ω,x∈Rn ω , x ∈ R n ,考虑单调可微函数 g(.) g ( . ) ,我们称形如 y=g(z)=g(ωx) y = g ( z ) = g ( ω x ) 的模型为“广义线性模型”。
1逻辑回归模型
线性回归模型的预测结果为连续值,当我们需要预测的结果是0-1的离散值时,我们希望引入函数
g(.)
g
(
.
)
,使得
y=g(z)
y
=
g
(
z
)
能将连续值转换为离散值并直接输出0/1。最理想的一个函数是阶跃函数
y=ϕ(z)
y
=
ϕ
(
z
)
,使得:
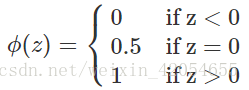
但这个函数不是一个连续函数,因此不能作为广义线性模型中的
g(.)
g
(
.
)
。我们找到一种sigmoid函数:
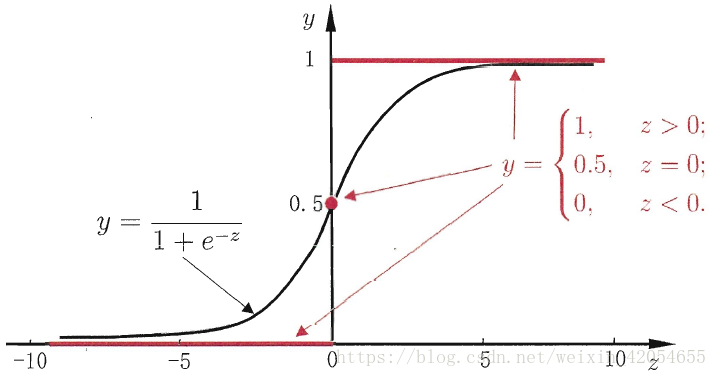
令 z=ωTx z = ω T x ,并代入 g(z) g ( z ) 中,就得到逻辑回归模型:
该模型的输入 x x 表示一个样本在一组特征向量上的取值,模型输出可以理解为预测输入样本取正类的概率。
这个sigmoid函数还有一个非常好的性质:
我们很快就会用到这个性质。
2 逻辑回归模型的损失函数
我们已经知道逻辑回归的输出
g(x)
g
(
x
)
可以理解为预测输入样本取正类的概率,我们可以做如下定义:
分别表示模型预测输出样本 x x 为正类和负类的概率。将两个式子合并,可以写作:
我们可以用极大似然估计的方法去推测我们的模型系数 ω ω ,并用极大似然函数构造损失函数 J(ω) J ( ω ) 。取极大似然函数:
我们可以对极大似然函数取对数,就变成:
这个函数值越大,预测准确率越高。也就是我们需要求的是使这个函数值最大时所对应的 ω ω 。再加个负号就是我们的误差函数,即:
用矩阵表示,可以表示为:
3 逻辑回归模型的求解
上一节提到的逻辑回归损失函数
J(ω)
J
(
ω
)
是一个关于
ω
ω
的凸函数,求解凸函数的极小值的方法有很多,如梯度下降法、牛顿法等。以下展示用梯度下降法进行求解的推导。
J(ω)
J
(
ω
)
对
ωj
ω
j
求导,有:
所以, ω ω 的更新过程可以写成: ωj:=ωj−α∑mi=1[g(x(i)−y(i))]x(i)j ω j := ω j − α ∑ i = 1 m [ g ( x ( i ) − y ( i ) ) ] x j ( i ) ,其中 α α 表示每次更新的步长。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









