







目录
一. 文件读写
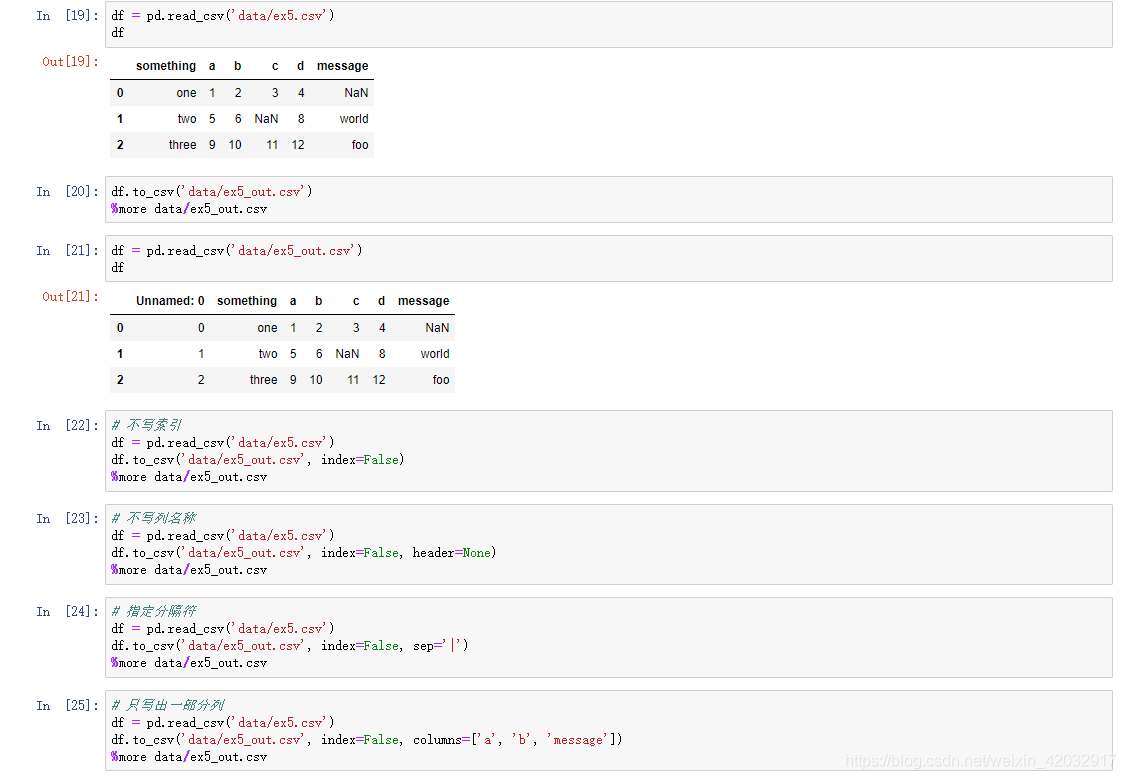
载入数据到pandas
索引:将一个列或多个列读取出来构成 DataFrame,其中涉及是否从文件中读取索引以及列名
类型推断和数据转换:包括用户自定义的转换以及缺失值标记
日期解析
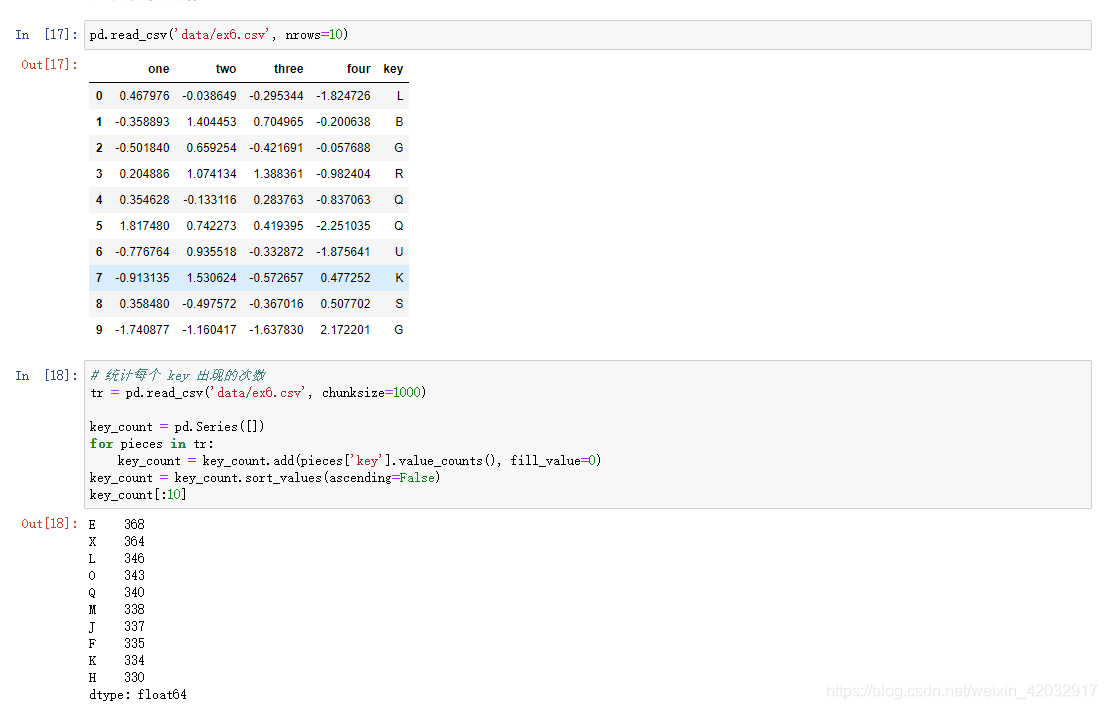
迭代:针对大文件进行逐块迭代。这个是Pandas和Python原生的csv库的最大区别
不规整数据问题:跳过一些行,或注释等等
索引及列名
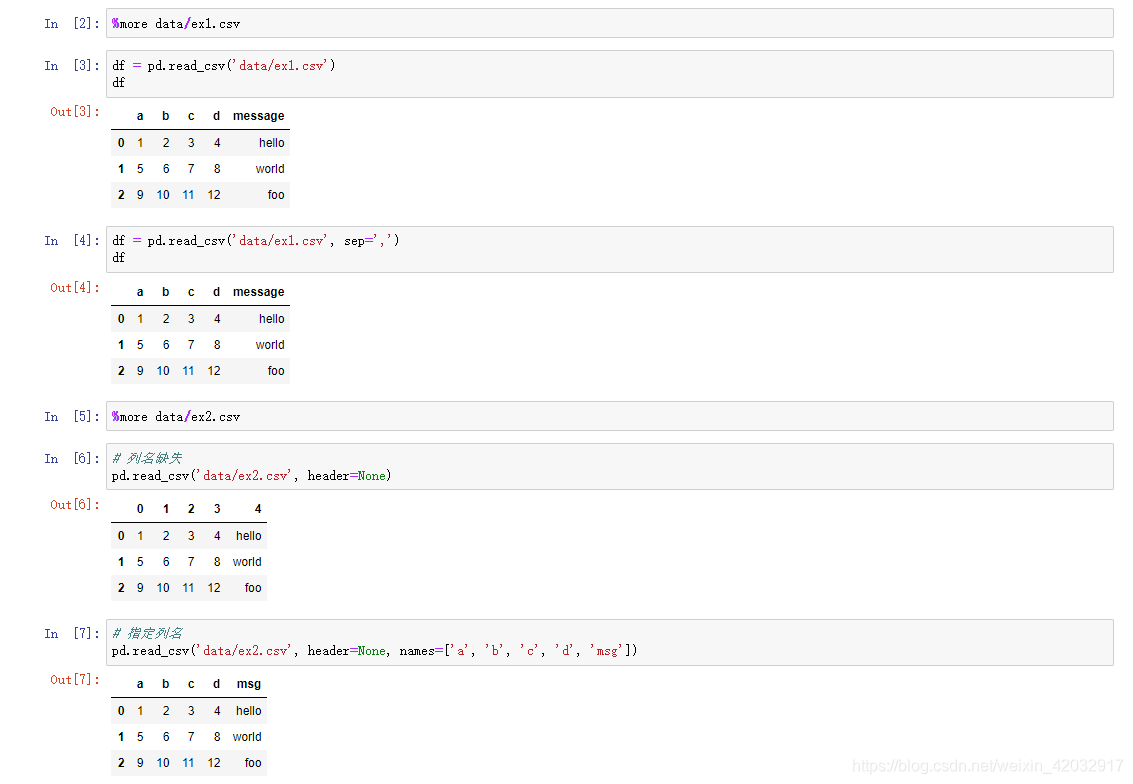
处理不规则的分隔符
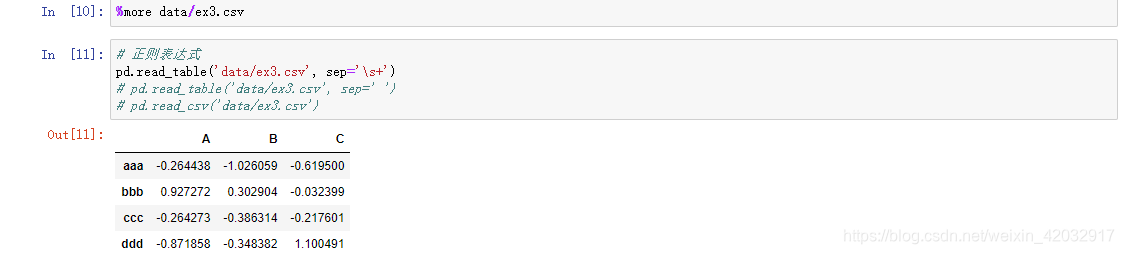
缺失值的处理
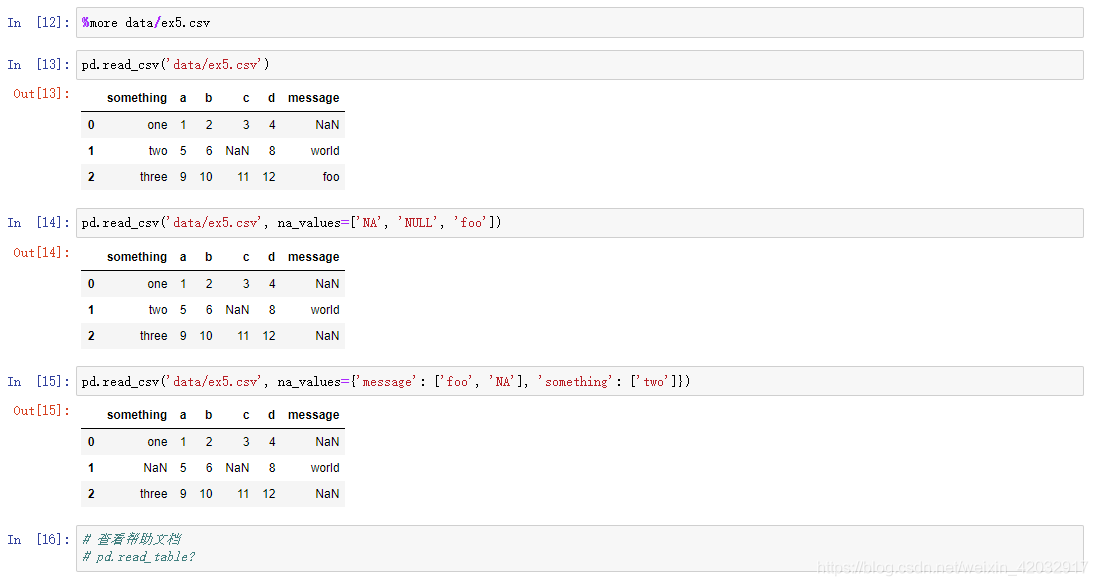
逐块读取数据
保存数据到磁盘
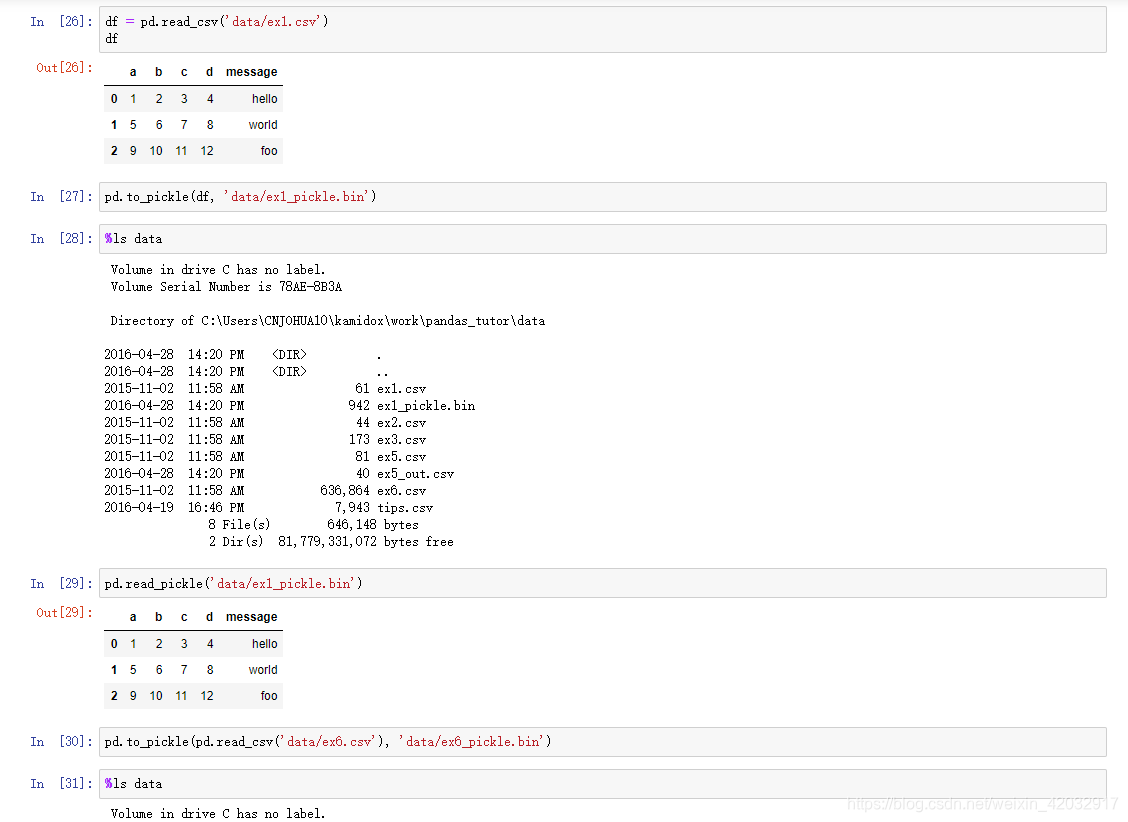
二进制格式
二进制的优点是容量小,读取速度快。缺点是可能在不同版本间不兼容。比如 Pandas 版本升级后,早期版本保存的二进制数据可能无法正确地读出来。
二. 时间处理
时间序列
基础:python的datetime
创建日期序列
pd.date_range(‘20190901’, periods=7, normalize=True, freq=‘24H’) # 包含从20190901及其以后7个间隔为24h(默认)的序列,并只保留到日
时期
pd.Period(2010)
创建时期序列
pd.period_range(‘20190901’, periods=7 , freq=‘24H’)
频率转换
pd.Period.asfreq(‘频率标识’)
重采样
ts.resample(‘5min’, how=‘sum’ label=‘left’/‘right’)
统计开盘收盘
how=‘ohlc’
三. 数据可视化
notebook内显示
%matplotlib inline
线型图
.plot(title=’’, style=’’, figsize=(,), subplot=True/False)
柱状图
.plot.bar()
直方图
.hist(bins=多少等分)
概率密度
.plot.kde()
散点图
.plot.scatter()
饼图
.plot.pie()

















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









