









OWT Server进程结构和JS代码处理流程 [Open WebRTC Toolkit]
目录

相关文章:
1. 进程结构
- 在基本的SFU功能中,将会涉及Management API、Cluster Manager、WebRTC Portal、Conference Agent、WebRTC Agent这几个组件。
- 从编程语言的层面看,很多组件都会包含Javascript和C++代码,各个组件的进程都是通过NodeJS启动的,C++代码会被编译为NodeJS扩展的形式,进而被Javascript代码使用。
- 从代码结构的层面看,不少组件都会有共用代码,直接分析项目源码会造成一定的干扰,所以查看的是发布之后的代码。
- 每个组件都是独立的目录,目录中包含的是这个组件运行所需的完整代码。
-
每种组件都会负责处理一些任务,比如WebRTC Portal负责和WebRTC客户端进行信令交互、Conference Agent负责会议房间的管理和控制、WebRTC Agent负责流的发布和订阅,每一个任务在服务端会对应于一个task。
-
每种Agent(比如WebRTC Agent)都会有一个主进程(代码里面叫worker进程,也叫agent进程)、多个工作进程(代码里面叫node进程)。
-
agent进程会提供node进程管理的RPC服务(getNode、recycleNode、queryNode),node进程会提供实际工作的RPC服务(比如WebRTC的publish操作等)。
-
getNode会返回node进程的rpcId(也就是nodeId),用于调用方直接向node发起RPC。
-
Cluster Manager负责对agent进行调度,注意不是对node进行调度。
-
一个agent和多个node是运行在同一台机器上的,同一台机器不用进行调度。它会记录agent与task的关系,作为agent负载的体现,并据此实现调度逻辑。
-
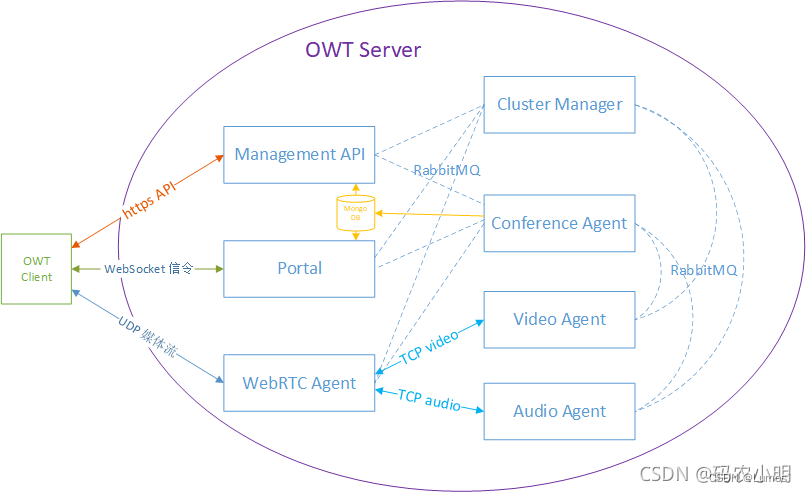
基础模块架构图:
- 模块内部的 RPC 调用都是通过 RabbitMQ 消息队列实现的,都不是直接调用,即上图中 所有的虚线都是通过RabbitMQ间接通信的,而不是直接连接。
- 模块内部流交换(Internal IO)默认用的是 TCP 协议直接交互。
- 会议房间信息(默认布局和支持的编码格式等)在创建会议的时候存储在 MongoDB 中。
-
接下来结合具体代码展开分析上面介绍的进程结构的建立和交互过程,以及几个典型请求的处理流程。
2. Management API
- 其实Management API(组件目录为management_api)不属于上述进程结构,它包含一个master进程和多个worker进程(默认是CPU核数),利用NodeJS的cluster模块实现多进程服务。
- 它的入口是api.js,会把resource目录中定义的各种RESTful接口暴露出去,比如rooms(房间)、streams(流)、participants(用户)
// Only following paths need authentication.
var authPaths = ['/v1/rooms*', '/v1.1/rooms*', '/services*', '/cluster*'];
app.get(authPaths, serverAuthenticator.authenticate);
app.post(authPaths, serverAuthenticator.authenticate);
app.delete(authPaths, serverAuthenticator.authenticate);
app.put(authPaths, serverAuthenticator.authenticate);
app.patch(authPaths, serverAuthenticator.authenticate);
app.post('/services', servicesResource.create);
app.get('/services', servicesResource.represent);
app.get('/services/:service', serviceResource.represent);
app.delete('/services/:service', serviceResource.deleteService);
...
3. WebRTC Portal
- WebRTC Portal(组件目录为portal),它只有一个主进程,主要逻辑为:
- 主进程启动后会连接到RabbitMQ服务器,并获取RPC客户端,用来向其他组件发起RPC。基于RabbitMQ的RPC由amqp_client.js实现,并被各个组件使用。
- 连接成功后,会把自己注册到Cluster Manager中,和Cluster Manager交互的逻辑由clusterWorker.js实现,也被各个组件使用,后面会对它展开分析。
- 注册成功后,会提供自己的RPC服务,并监听RPC服务的状态,主要用于处理异常事件。
- 监听成功后,执行startServers函数,启动SocketIO长连接服务器。SocketIO服务器的逻辑在socketIOServer.js和v11Client.js(除了v11Client,还有v10Client和legacyClient,用于老版本的兼容)中。
- socketIOServer只监听login、relogin、refreshReconnectionTicket、logout、disconnect和connection这6个事件。其中,前4个是OWT Server信令协议定义的,最后两个由长连接客户端的断开和接入触发。在处理login和relogin事件时,会根据protocol字段的取值来决定使用哪一版本的Client。
- 创建了Client后,会调用其join函数,最终在portal.js里发起RPC拿到Conference Agent的nodeId,并向Conference Agent的node发起join RPC。
- v11Client监听了其他所有OWT Server信令协议的事件,比如publish、subscribe等。
- v11Client中监听到事件后,都会调用portal.js中的各种函数进行处理,下面以publish事件为例,总结一下调用栈:
source/portal/v11Client.js socket.on('publish', function(pubReq,
source/portal/portal.js that.publish = = function(participantId, streamId, pubInfo) =>
source/portal/rpcRequest.js that.publish = function(controller, participantId, streamId, Options):向Conference Agent的node发起publish RPC
- Conference Agent里的处理逻辑后面再分析,这里先解答一个问题:集群里有多个WebRTC Portal该如何调度。参考创建token的处理逻辑,它在management_api/resource/v1/tokenResource.js的generateToken函数中,其中调用requestHandler.schedulePortal函数对WebRTC Portal进行调度。schedulePortal函数在management_api/requestHandler.js中,向Cluster Manager发起schedule RPC,提供客户端的请求数据(互联网服务提供商ISP和地域),要求分配一个WebRTC Portal的地址。
- 调用栈为:
source/management_api/resource/v1/tokensResource.js generateToken = function(currentRoom, ... =>
source/management_api/resource/v1/tokensResource.js rpc.callRpc(cluster_name, 'schedule', ... =>
source/cluster_manager/scheduler.js that.schedule = function (task, preference, ...
- Cluster Manager里的处理逻辑后面再分析,其他事件的处理也类似,可以参考:OWT Server信令分析 (下) [Open WebRTC Toolkit],有详细的客户端和服务端事件处理流程。
- WebRTC Portal的主要逻辑就分析完毕。
4. Conference Agent
- Conference Agent(组件目录为conference_agent)是典型的agent - node结构,由于各种Agent的启动流程基本一致,因此这部分源码是共用的,通过启动参数-U(代码中叫purpose)来区分Agent类型。
- Agent连接RabbitMQ服务器、注册到Cluster Manager、提供RPC服务的过程都和WebRTC Portal基本一致,不过最后它还会初始化nodeManager(实际node进程管理的实现,源码在nodeManager.js中)。
- 初始化nodeManager时,会传入添加和移除task的回调以及node进程异常退出的回调,在这些回调里会调用clusterWorker的对应接口,向Cluster Manager发起RPC,即向Cluster Manager注册、添加和移除task都是由clusterWorker负责的,这些和Cluster Manager交互的过程后面再展开。
- nodeManager创建后,会通过launchNode函数启动node进程。一个node进程负责一个房间,node进程的入口为workingNode.js,其中purpose参数也会传递给node进程。node进程启动后,和purpose同名的.js文件或同名目录中的index.js提供了node进程的RPC服务,比如Conference Agent的node进程的RPC服务就定义在conference.js中,这些服务可能通过rpcAPI变量暴露,也可能由各个函数直接暴露。在查看这部分代码时,如果没有看到rpcAPI的定义,不用奇怪。
- 现在总结一下join RPC的处理过程:
source/portal/portal.js that.join = function(participantId, token) =>
source/portal/rpcRequest.js that.join = function(controller, roomId, participant) =>
source/agent/conference/conference.js that.join = function(roomId, participantInfo, callback) =>
source/agent/conference/conference.js initRoom = function(roomId, origin) => //保存房间信息,创建roomController、accessController
source/agent/conference/conference.js addParticipant = function(participantInfo, permission) => //保存用户信息
- accessController负责接入逻辑,比如WebRTC的信令处理等,roomController负责房间内各种状态的维护和功能的控制,比如流、订阅关系等,以及发布(publish)、订阅(subscribe)、混流(mix)、设置混流布局(setLayout)等。也有很多实际的处理工作都是向其他组件的node进程发起RPC完成的。
- 接着我们总结publish RPC的处理流程:
source/portal/v11Client.js socket.on('publish', function(pubReq,
source/portal/portal.js that.publish = = function(participantId, streamId, pubInfo) =>
source/portal/rpcRequest.js that.publish = function(controller, participantId, streamId, Options) =>
source/agent/conference/conference.js that.publish = function(participantId, streamId, pubInfo, callback) =>
source/agent/conference/accessController.js that.initiate = function(participantId, sessionId, direction, origin, sessionOptions, ... =>
source/agent/conference/rpcRequest.js that.getWorkerNode = function(clusterManager, purpose, ... => //发起RPC,拿到WebRTC Agent的nodeId
source/agent/conference/rpcRequest.js that.initiate = function(accessNode, sessionId, ... => //向WebRTC Agent的node发起publish RPC
# WebRTC Agent的RPC服务定义在webrtc/index.js中
source/agent/conference/rpcRequest.js that.initiate = function(accessNode, sessionId, ... => //向WebRTC Agent的node发起publish RPC
source/agent/webrtc/index.js that.publish = function (operationId, connectionType, ... =>
source/agent/webrtc/index.js createWebRTCConnection = function (transportId, ... => //创建WrtcConnection(`webrtc/wrtcConnection.js`),它负责和C++ 代码进行交互
# WebRTC PC连接成功后,会向Conference Agent的node发起onSessionProgress RPC
source/agent/conference/conference.js conference.js that.onSessionProgress =>
source/agent/conference/accessController.js that.onSessionStatus =>
source/agent/conference/accessController.js accessController.js onReady =>
source/agent/conference/conference.js onSessionEstablished =>
source/agent/conference/conference.js addStream =>
source/agent/conference/roomController.js that.publish
- 发布和订阅流的SDP通过onSessionSignaling RPC进行处理,其流程为:
source/portal/rpcRequest.js that.onSessionSignaling =>
source/agent/conference/conference.js that.onSessionSignaling =>
source/agent/conference/rtcController.js onClientTransportSignaling =>
source/agent/conference/rpcRequest.js that.onTransportSignaling =>
source/agent/webrtc/index.js that.onTransportSignaling =>
source/agent/webrtc/wrtcConnection.js that.onSignalling
// 其他资料上述显示过程如下:
WebRTC Portal rpcRequest.js that.onSessionSignaling =>
conference.js that.onSessionSignaling =>
accessController.js that.onSessionSignaling:向WebRTC Agent的node发起onSessionSignaling RPC
- 最后总结subscribe RPC的处理流程:
source/portal/rpcRequest.js that.publish = function(controller, participantId, streamId, Options) =>
source/agent/conference/conference.js that.subscribe = function(controller, participantId, ... =>
source/agent/conference/rtcController.js initiate(ownerId, sessionId, direction, origin, ... =>
source/agent/conference/rpcRequest.js that.getWorkerNode:发起RPC,拿到WebRTC Agent的nodeId
source/agent/conference/rpcRequest.js that.initiate = function(accessNode, sessionId, ... => //向WebRTC Agent的node发起publish RPC
# WebRTC PC连接成功后,会向Conference Agent的node发起onSessionProgress RPC
source/agent/conference/conference.js conference.js that.onSessionProgress =>
source/agent/conference/accessController.js that.onSessionStatus =>
source/agent/conference/accessController.js onReady =>
source/agent/conference/conference.js onSessionEstablished =>
source/agent/conference/conference.js addSubscription =>
source/agent/conference/roomController.js that.subscribe =>
source/agent/conference/roomController.js spreadStream:如果流的发布和订阅由不同的WebRTC Agent处理,就需要把流从发布Agent扩散到订阅Agent
source/agent/conference/roomController.js linkup(subscribe的内部函数):向WebRTC Agent的node发起linkup RPC
- 需要做流扩散的情况,分析完WebRTC Agent后再单独分析。其他RPC的处理可以举一反三。
- Conference Agent SFU模式的主要逻辑就分析完毕。
5. WebRTC Agent
- WebRTC Agent(组件目录为agent/webrtc),它也是典型的agent - node结构。
- index.js、clusterWorker.js、nodeManager.js和workingNode.js的代码都是共用的,介绍node进程RPC的处理逻辑。
- 因为一个流的发布和订阅可能由不同的WebRTC Agent处理,所以WebRTC Agent的node除了需要和WebRTC客户端进行数据传输外,还可能需要和其他Agent的node进行数据传输(流扩散)。
- 对于这两种传输,在代码里将前者定义为webrtc类型,将后者定义为internal类型。本小节先只考虑webrtc类型,流扩散的情况下一小节再分析。
- WebRTC Agent node进程的RPC服务定义在webrtc/index.js中,这里总结一下publish、onSessionSignaling、subscribe和linkup的处理过程,其他的RPC服务可以同理分析。
- 首先是publish:
source/agent/conference/rpcRequest.js that.initiate =>
source/agent/webrtc/index.js that.publish =>
source/agent/webrtc/index.js createWebRTCConnection:创建WrtcConnection(`webrtc/wrtcConnection.js`),它负责和C++ 代码进行交互
source/agent/connections.js that.addConnection:保存创建的连接对象
- 创建WrtcConnection时会执行webrtc/wrtcConnection.js的initWebRtcConnection函数,其中会监听C++代码发送的事件(由webrtc/connection.js做了一层翻译,变成status_event事件),收到事件后会回调给webrtc/index.js的notifyStatus函数,向Conference Agent的node发起onSessionProgress RPC。
- 接着是onSessionSignaling:
source/portal/rpcRequest.js that.onSessionSignaling =>
source/agent/conference/conference.js that.onSessionSignaling =>
source/agent/conference/rtcController.js onClientTransportSignaling =>
source/agent/conference/rpcRequest.js that.onTransportSignaling =>
source/agent/webrtc/index.js that.onSessionSignaling =>
source/agent/webrtc/wrtcConnection.js that.onSignalling:把SDP传给C++ 层的代码进行处理
- 接着是subscribe:
source/portal/portal.js that.subscribe = function(participantId, ... =>
source/portal/rpcRequest.js that.publish = function(controller, participantId, streamId, Options) =>
source/agent/conference/conference.js that.subscribe = function(controller, participantId, ... =>
source/agent/conference/rtcController.js initiate(ownerId, sessionId, direction, origin, ... =>
source/agent/conference/rpcRequest.js that.initiate = function(accessNode, sessionId, ... => //向WebRTC Agent的node发起publish RPC
source/agent/webrtc/index.js that.subscribe = function (operationId, connectionType, ... =>
source/agent/webrtc/index.js createWebRTCConnection = function (transportId, ... => //创建WrtcConnection(`webrtc/wrtcConnection.js`),它负责和C++ 代码进行交互
source/agent/connections.js that.addConnection:保存创建的连接对象
- 最后是linkup:
source/agent/conference/roomController.js that.subscribe =>
source/agent/conference/roomController.js spreadStream:如果流的发布和订阅由不同的WebRTC Agent处理,就需要把流从发布Agent扩散到订阅Agent
source/agent/conference/roomController.js linkup(subscribe的内部函数):向WebRTC Agent的node发起linkup RPC
source/agent/webrtc/index.js that.linkup =>
source/agent/internalConnectionRouter.js linkup(dstId, from) =>
source/agent/connections.js that.linkupConnection =>
source/agent/webrtc/wrtcConnection.js sender.addDestination =>
source/agent/webrtc/wrtcConnection.js addDestination 调用C++ 接口关联发布端和订阅端
- WebRTC Agent SFU模式的主要逻辑就分析完毕。
6. WebRTC Agent node间的流扩散
- 如果一个流的发布和订阅由不同的WebRTC Agent处理,就记处理发布的node为original_node、处理订阅的node为target_node,即客户端A把流发布到original_node,客户端B从target_node订阅流。为了让客户端B能成功收到客户端A的流,我们需要把流从original_node扩散(发送)到target_node,相当于给original_node增加了一路订阅,给target_node增加了一路发布,当然这个订阅和发布其实是同一个连接的两端。
- 现在总结一下Conference Agent roomController.js的spreadStream函数:
- 根据记录的流信息,获取流发布端的nodeId(original_node)、订阅端的nodeId(target_node)。
- 如果original_node等于target_node,则发布和订阅由同一个WebRTC Agent处理,无须扩散,否则需要扩散。
- 向target_node发起createInternalConnection RPC,方向为in,即给target_node增加一路发布,向original_node发起createInternalConnection RPC,方向为out,即给original_node增加一路订阅。
- 向target_node发起publish RPC,向original_node发起subscribe RPC,这两个RPC都会提供对端node的internal connection地址。
- 向original_node发起linkup RPC,关联发布端(客户端A)和订阅端(internal connection)。
var spreadStream = function (stream_id, target_node, target_node_type, on_ok, on_error) {
log.debug('spreadStream, stream_id:', stream_id,
'target_node:', target_node, 'target_node_type:', target_node_type);
if (!streams[stream_id] || !terminals[streams[stream_id].owner]) {
return on_error('Cannot spread a non-existing stream');
}
const stream_owner = streams[stream_id].owner;
const original_node = terminals[stream_owner].locality.node;
const audio = ((streams[stream_id].audio && target_node_type !== 'vmixer' && target_node_type !== 'vxcoder') ? true : false);
const video = ((streams[stream_id].video && target_node_type !== 'amixer' && target_node_type !== 'axcoder') ? true : false);
const spread_id = stream_id + '@' + target_node;
const data = !!streams[stream_id].data;
if (!audio && !video && !data) {
return on_error('Cannot spread stream without audio, video or data.');
}
if (original_node === target_node) {
log.debug('no need to spread');
return on_ok();
}
const on_spread_start = function () {
log.debug('spread start:', spread_id);
const i = streams[stream_id].spread.findIndex((s) => (s.target === target_node));
if (i >= 0) {
if (streams[stream_id].spread[i].status === 'connected') {
log.debug('spread already exists:', spread_id);
on_ok();
} else if (streams[stream_id].spread[i].status === 'connecting') {
log.debug('spread is connecting:', spread_id);
streams[stream_id].spread[i].waiting.push({onOK: on_ok, onError: on_error});
return true;
} else {
log.error('spread status is ambiguous:', spread_id);
on_error('spread status is ambiguous');
}
return false;
}
streams[stream_id].spread.push({target: target_node, status: 'connecting', waiting: []});
return true;
};
const on_spread_failed = function(reason) {
log.error('spreadStream failed, stream_id:', stream_id, 'reason:', reason);
const i = (streams[stream_id] ? streams[stream_id].spread.findIndex((s) => {return s.target === target_node;}) : -1);
if (i > -1) {
streams[stream_id].spread[i].waiting.forEach((e) => {
e.onError(reason);
});
streams[stream_id].spread.splice(i, 1);
}
on_error(reason);
};
const on_spread_ok = function () {
log.debug('spread ok:', spread_id);
const i = streams[stream_id].spread.findIndex((s) => {return s.target === target_node;});
if (i >= 0) {
streams[stream_id].spread[i].status = 'connected';
process.nextTick(() => {
streams[stream_id].spread[i].waiting.forEach((e) => {
e.onOK();
});
streams[stream_id].spread[i].waiting = [];
});
on_ok();
} else {
on_error('spread record missing');
}
}
if (!on_spread_start()) {
return;
}
if (['vmixer', 'amixer', 'vxcoder', 'axcoder', 'aselect'].includes(target_node_type)) {
const locality = terminals[stream_owner].locality;
if (!locality.ip || !locality.port) {
log.error('No internal address for locality:', locality);
on_spread_failed('No internal address for locality');
} else {
makeRPC(
rpcClient,
target_node,
'publish',
[
stream_id,
'internal',
{
controller: selfRpcId,
publisher: (terminals[stream_owner].owner || 'common'),
audio: (audio ? {codec: streams[stream_id].audio.format} : false),
video: (video ? {codec: streams[stream_id].video.format} : false),
data: data,
ip: locality.ip,
port: locality.port,
}
],
function pubOk() { on_spread_ok(); },
function pubError(e) { on_spread_failed(e); }
);
}
} else {
on_spread_ok();
}
};
- spreadStream函数执行完毕后,subscribe的内部函数linkup内会向target_node发起linkup RPC,关联发布端(internal connection)和订阅端(客户端B)。至此,从客户端A到original_node,再到target_node,最后到客户端B的链路就完整了。
- 再看WebRTC Agent internal connection相关的代码,首先是创建:
source/agent/audio/index.js that.createInternalConnection =>
source/agent/InternalConnectionFactory.js that.create:根据方向,创建InConnection或OutConnection
- 对于TCP和UDP的internal connection,InConnection负责listen,OutConnection负责connect。
- publish处理的区别是,connection对象是获取之前创建的InConnection,并调用其connect函数,而不是创建WrtcConnection。subscribe处理的区别是,connection对象获取之前创建的OutConnection,并调用其connect函数。linkup处理的区别是,connection对象类型不同,最终执行不同C++类的addDestination函数。
// Create the connection and return the port info
that.create = function (connId, direction, internalOpt) {
// Get internal connection's arguments
var prot = internalOpt.protocol;
var minport = internalOpt.minport || 0;
var maxport = internalOpt.maxport || 0;
var ticket = internalOpt.ticket;
if (preparedSet[connId]) {
log.warn('Internal Connection already prepared:', connId);
// FIXME: Correct work flow should not reach here, when a connection
// is in use, it should not be created again. we should ensure the
// right call sequence in upper layer.
return preparedSet[connId].connection.getListeningPort();
}
var conn = (direction === 'in')
? InConnection(prot, minport, maxport, ticket)
: OutConnection(prot, minport, maxport, ticket);
preparedSet[connId] = {connection: conn, direction: direction};
return conn.getListeningPort();
};
7. Cluster Manager
- 最后分析Cluster Manager(组件目录为cluster_manager)。问题:
- Agent注册到Cluster Manager的流程。
- WebRTC Portal的调度过程。
- WebRTC Portal拿到Conference Agent的nodeId的过程。
- Conference Agent的node拿到WebRTC Agent的nodeId的过程。
- 添加、移除、执行task的流程。
- 首先Cluster Manager只有主进程,不过实现了主从模式的集群机制,可以部署多台机器运行Cluster Manager,它们会自动选择出一台主机,用于处理其他模块的RPC请求,其他从机则会定期检查主机的在线状态,一旦主机掉线,则又自动选择出另一台主机。主从模式的集群机制以及RPC服务的定义都在clusterManager.js中。
- 下面以Conference Agent为例,看一下Agent注册到Cluster Manager的流程:
# 创建clusterWorker触发
source/common/clusterWorker.js joinCluster =>
source/common/clusterWorker.js join:向Cluster Manager发起join RPC
source/cluster_manager/clusterManager.js join =>
source/cluster_manager/clusterManager.js workerJoin =>
source/cluster_manager/scheduler.js that.add:保存worker进程的信息
- 其中workerJoin函数会按需创建scheduler(调度器),每种worker(Agent的agent进程,由purpose参数区分)会有一个独立的scheduler,后续的调度任务也由这个scheduler完成。
- 接着看WebRTC Portal的调度过程,比如:
source/management_api/resource/v1/tokensResource.js generateToken =>
source/management_api/requestHandler.js exports.schedulePortal =>
source/management_api/requestHandler.js scheduleAgent('portal', ... =>
source/cluster_manager/scheduler.js that.schedule:根据调度策略和负载信息,选择出一个worker,回调回去
- scheduler.js的schedule函数首先会检查待调度的task是否已经存在:若已存在task且分配的worker也存在,则直接返回worker。否则,从可用的worker中进行过滤和调度。
- 过滤逻辑位于matcher.js中,主要考虑互联网服务提供商ISP、地域以及处理数据的格式等,调度策略位于strategy.js中,包括leastUsed、mostUsed、lastUsed、roundRobin和randomlyPick五种策略。
- 查看Management API的代码可以发现,请求调度时的task是一个随机数,所以同一个房间的用户可能调度到不同的WebRTC Portal上。
- 接着看WebRTC Portal拿到Conference Agent的nodeId的过程,比如:
source/portal/portal.js that.join
source/portal/rpcRequest.js that.getController =>
source/cluster_manager/scheduler.js that.schedule => //拿到Conference Agent的worker进程id
source/agent/index.js (rpcAPI)getNode: function(task, callback) =>
source/agent/nodeManager.js that.getNode => 根据房间号查找已启动的node,或启动新的node
source/agent/index.js (rpcAPI)getNode: function(task, callback) 把Conference Agent的nodeId回调回去
- WebRTC Portal请求调度时的task是房间号,所以同一个房间的所有用户都会被调度到同一个Conference Agent上。Agent分配node的过程也是考虑了房间号的,所以同一个房间的所有用户都由同一个Conference Agent的node进程进行处理,它们之间能互通。
- 接着我们看Conference Agent的node拿到WebRTC Agent的nodeId的过程:
source/agent/conference/conference.js that.publish = function(participantId, streamId, pubInfo, callback) =>
source/agent/conference/accessController.js that.initiate = function(participantId, sessionId, direction, origin, sessionOptions, ... =>
source/agent/conference/rpcRequest.js that.getWorkerNode = function(clusterManager, purpose, ... => //发起RPC,拿到WebRTC Agent的nodeId
source/cluster_manager/scheduler.js that.schedule => //拿到WebRTC Agent的worker进程id
source/agent/conference/rpcRequest.js //回到that.getWorkerNode,向WebRTC Agent的worker进程发起getNode RPC
source/agent/index.js (rpcAPI)getNode: function(task, callback) =>
source/agent/nodeManager.js that.getNode => 根据房间号查找已启动的node,或启动新的node
source/agent/index.js (rpcAPI)getNode: function(task, callback) 把WebRTC Agent的nodeId回调回去
- Conference Agent请求调度时的task,publish用的是streamId,subscribe用的是subscriptionId,这两个id都是在WebRTC Portal里随机生成的,所以一个流的发布和订阅可能调度到不同的WebRTC Agent上。如果调度到不同的WebRTC Agent上,则会通过前面分析的流扩散机制进行数据转发。如果调度到同一个WebRTC Agent上,那么由于分配node考虑了房间号,因此会被分配到同一个node进程。
- 最后,以Conference Agent为例看一下添加、移除、执行task的流程。注意,下述过程其实不是实际任务的处理过程,而是Cluster Manager追踪task的过程。
- 添加task:
source/agent/nodeManager.js that.getNode =>
source/agent/nodeManager.js addTask = function(nodeId, task) =>
index.js创建nodeManager时提供的onTaskAdded回调 =>
source/common/clusterWorker.js that.addTask =>
source/common/clusterWorker.js pickUpTasks = function (taskList) =>
source/cluster_manager/clusterManager.js pickUpTasks = function (worker, tasks) =>
source/cluster_manager/scheduler.js that.pickUpTasks =>
source/cluster_manager/scheduler.js executeTask = function (worker, task):把task添加到worker的tasks数组中,表示worker开始执行这个task
- 移除task:
source/agent/nodeManager.js that.recycleNode =>
source/agent/nodeManager.js removeTask = function(nodeId, task, ... =>
index.js创建nodeManager时提供的onTaskRemoved回调 =>
source/common/clusterWorker.js that.removeTask =>
source/common/clusterWorker.js layDownTask = function (worker, task) =>
source/cluster_manager/clusterManager.js layDownTask =>
source/cluster_manager/scheduler.js that.layDownTask =>
source/cluster_manager/scheduler.js cancelExecution:把task从worker的tasks数组中移除,表示worker结束执行这个task
- 任务的实际执行和Cluster Manager无关,由调用方直接向node发起RPC触发。发起RPC之前都会通过getNode RPC获取nodeId,于是触发了添加task的过程。任务处理完之后,会发起recycleNode RPC释放node,于是触发了移除task的过程。
8. 完整过程总结
- 一张流程图总结一下上述完整的过程,OWT Server SFU流程图:
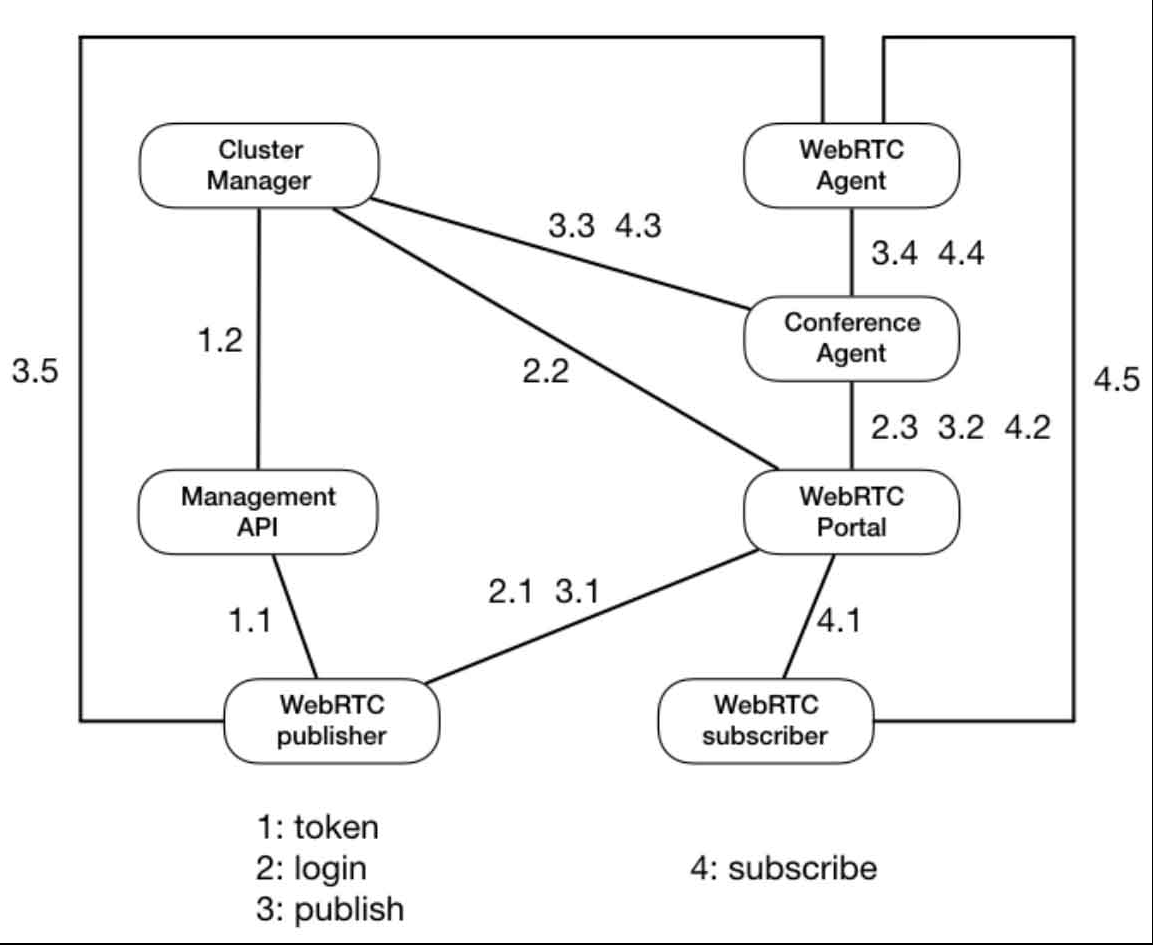
- 图中连线上的数字含义为:
- 客户端获取token。
- 客户端向Management API发送HTTP POST请求。
- Management API向Cluster Manager发起schedule RPC,请求调度WebRTC Portal。
- 客户端login。
- 客户端向WebRTC Portal发送login SocketIO事件。
- WebRTC Portal向Cluster Manager发起schedule RPC,请求调度Conference Agent。
- WebRTC Portal向Conference Agent(的node)发起join RPC。
- publish。
- publisher向WebRTC Portal发送publish SocketIO事件。
- WebRTC Portal向Conference Agent(的node)发起publish RPC。
- Conference Agent向Cluster Manager发起schedule RPC,请求调度WebRTC Agent。
- Conference Agent向WebRTC Agent(的node)发起publish RPC。
- publisher和WebRTC Agent(的node)通过PC传输媒体数据。
- subscribe。
- subscriber向WebRTC Portal发送subscribe SocketIO事件。
- WebRTC Portal向Conference Agent(的node)发起subscribe RPC。
- Conference Agent向Cluster Manager发起schedule RPC,请求调度WebRTC Agent。
- Conference Agent向WebRTC Agent(的node)发起subscribe RPC。
- subscriber和WebRTC Agent(的node)通过PC传输媒体数据。
- 客户端获取token。
参考:
《WebRTC Native开发实战》
OWT Server 整体架构分析 里的基础架构图

















 944
944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









