







 提出一种算法,能从单个静止图像中推断详细的三维结构,建立既精确又视觉上令人满意的三维模型。该算法使用马尔可夫随机场(MRF)推断图像小区域的三维位置和方向,无需对场景结构做明确假设,适用于复杂场景。
提出一种算法,能从单个静止图像中推断详细的三维结构,建立既精确又视觉上令人满意的三维模型。该算法使用马尔可夫随机场(MRF)推断图像小区域的三维位置和方向,无需对场景结构做明确假设,适用于复杂场景。
Make3D Learning 3D Scene Structure from aSingle Still Image(译文)
下载原文:https://cn.bing.com/academic/profile?id=45505ee803dc50067cac97db19e57b67&encoded=0&v=paper_preview&mkt=zh-cn
欢迎在下面留言交流。
摘要:
我们考虑从非结构化的单个静止图像中的估计详细的三维结构的问题。我们的目标是建立三维模型,即能在数量上精确,又能在视觉上令人满意。
对于图像中的每一个均匀的小区域,我们使用马尔可夫随机场(MRF)来推断一组“平面参数”,这些参数可以捕捉小区域的三维位置和三维方向。MRF通过用监督学习训练,对图像的深度线索以及图像不同部分之间的关系进行建模,除了假设环境是由许多小平面组成之外,我们的模型对场景的结构没有做出任何明确的假设。这使得算法能够捕捉比现有技术更详细的三维结构,并且在使用基于图像的渲染创建的三维草图中提供更丰富的经验,即使对于具有显著非垂直结构的场景。
利用这种方法,我们为从网上下载的588幅图像中的64.8%创建了质量正确的三维模型,我们还扩展了我们的模型,从一些图像生成了大规模的三维模型。
引语:机器学习,单目视觉,深度学习,视觉和场景理解,场景分析:深度线索。

一、介绍:
在看到如图1a所示的图像时,人类不难理解其三维结构(图1c、d)。然而,对于目前的计算机视觉系统来说,推断出这样的三维结构仍然是一个极具挑战性的课题。实际上,从狭义的数学意义上讲,从一副图像上恢复其三维深度是不可能的,因为,我们永远无法知道它是一副油画的图片(这种情况下,深度是平坦的)还是一副真实的三维环境的图。然而,实际上,只要一副图像,人们就能很好的感知深度;我们希望我们的计算机在场景中也具有类似的感知。
理解三维结构是计算机视觉的一个基本问题。对于三维重建的具体问题,以往的工作主要集中于立体视觉、运动结构和其他需要两幅(或多幅)图像的方法上。这些几何算法依赖于三角剖分来估计深度,然而,仅仅依赖于几何的算法往往会忽略大量额外的单目线索,这些线索也可以用来获取丰富的三维信息。在最近的研究中,[6]- [9] (文章的尾部的引用)利用了其中的一些线索来获得一些三维信息。Saxena,Chung和Ng[6]提出了一种基于单目图像特征的深度预测算法。[7]利用单目深度感知自主驾驶遥控车。[8],[9]建立模型时使用了一个强有力的假设,即场景由地面/水平面和垂直墙(可能还有天空)组成;因此,这次方法不使用于许多场景,这些场景并非仅由竖立在水平地板上的表面构成。一些例子包括山脉、树木(如图15b和13d)、楼梯(如图15a)、拱门(如图11a和15k)、屋顶(如图15m)等图像,这些图像通常具有更丰富的三维结构。
在这篇论文中,我们的目标是推断出既能在数量上精确有能在视觉上令人满意的三维模型。我们使用的洞察力,大多数三维场景是可以分割成许多下的,近似平面的表面(事实上,现代计算机图形学使用OpenGL或Directx以这种方式建模极其复杂的场景,使用三角面来建模甚至非常复杂的形状)。我们的算法从拍摄图像开始,并尝试将其分割成许多小的平面。使用超像素分割算法,[10]我们发现图像的过渡分割将其分割成许多小区域(超级像素)。在图1b中显示了这样的分割的一个例子。因为我们使用过分割,世界上的平面表面可能被分割成许多超像素;然而,每个超像素很有可能(至少近似地)完全位于一个平面上。
对于每个超像素,我们的算法试图推断出它来自的三维表面的三维位置和方向。这个三维表面不仅限于垂直和水平方向。而且可以朝向任何方向。从单个图像推断三维位置是非常重要的,而且人类使用许多不同的视觉深度线索,例如纹理(例如,近距离观察时草的纹理与远距离观察时草的纹理非常不同);颜色(例如,绿色斑块更可能是草上的地面;蓝色斑块更可能是天空)。我们的算法使用监督学习来学习不同的视觉线索是如何与不同的深度相关联的。我们的学习算法使用马尔可夫随机场模型,该模型也能考虑对邻近超混合体相对深度的限制。例如,它认识到两个相邻的图像块更可能位于相同的深度,甚至是共面的。而不是相隔很远。
在推断出每个超像素的三维位置后,我们现在可以构建场景的三维网格模型(图1c)。然后我们将原始图像纹理图构建一个纹理化的三维模型(图1d),我们可以从不同的角度浏览。
除了假设三维结构是由许多小平面组成之外,我们对场景的结构没有做出明确的假设。这使得我们的方法能够很好地概括,即使是对于结构化仅竖立在水平地面上的垂直表面(如山、树等)要丰富得多的场景。我们的算法能够自动推断从互联网下载的588个图像中64.9%的测试图像的三维模型,即能在数量上精确,又能在视觉上令人满意。我们进一步证明,我们的算法比之前的两项工作在数量上预测更精确的深度。
扩展这些思想,我们还考虑了在仅给定一组小的稀疏图像的情况下,创建大型新颖环境的三维模型的问题。在此设置中,场景的某些部分可能在多个图像中可见,因此可以使用三角剖分提示(来自运动的结构)帮助重建它们;但场景的较大部分可能仅在一个图像中可见。我们扩展了我们的模型,将三角剖分和单目图像无缝地结合起来。这使我们能够建立完整的,真实的三维模型,更大的场景。最后,我们还演示了如何将对象识别信息合并到我们的模型中。例如,如果我们发现一个站立的人,我们知道人们通常站在地板上,因此他们的脚必须在地面上。了解身高有多高也有助于我们从相机推断出它们的深度(距离);例如,图像中50像素高的人很可能是100像素高的人的两倍。(这也让人想起[11],他使用汽车和行人探测器以及已知大小的汽车/行人来估计地平线的位置。)
本文的其余部分安排如下。第二节论述了前期工作。第三节描述了我们从人类视觉中获得的直觉。第四节描述了我们为三维模型选择的表示。第五节描述了我们的概率模型,第六节描述了使用的特性。第七节描述了我们为测试我们的模型而进行的实验。第八节将我们的模型扩展到从稀疏视图构建大型三维模型的情况。第九节演示了如何将来自对象识别器的信息合并到我们的三维重建模型中,第十节总结。
二、前期工作
对于一些特定的设置,一些作者开发了从单个图像进行深度估计的方法。示例包括来自着色的形状[12]、[13]和来自纹理的形状[14]、[15];但是,这些方法很难应用于颜色和纹理不太均匀的曲面。Nagai等人[16]使用隐马尔可夫模型对已知的、固定的物体(如手和面孔)。Hassner和Basri[17]使用基于实例的方法从已知对象类估计对象的深度。Han和Zhu[18]对放置在无背景区域的已知特定类别的物体进行了三维重建。Criminisi、Reid和Zisserman[19]提供了一种交互式的三维几何计算方法,用户可以在其中指定对象分段、某些点的三维坐标和对象的参考高度。Torralba和Oliva[20]研究了图像的傅里叶谱与其平均深度之间的关系。
在当前的工作,Saxena, Chung和Ng (SCN)[6],[21]提出了一种基于单眼图像特征的深度预测算法,并成功地应用于提高立体视觉的性能[22]。Michels, Saxena和Ng[7]还使用单目深度感知和强化学习在非结构化环境中自主驾驶遥控汽车。Delage, Lee和Ng (DLN)[8],[23]和Hoiem, Efros和Hebert (HEH)[9]假设环境是由带垂直墙的菲亚特地面构成的。 DLN考虑的是室内图像,而HEH考虑的是室外场景。他们将图像分为水平/地面和垂直区域(也可能是天空),从图像中生成一个简单的“弹出”类型浏览(fiy-through)。
我们的方法使用马尔可夫随机场(MRF)来模拟单眼线索和图像各部分之间的关系。MRFs是机器学习的主力,已经被应用于各种局部特征不足和需要使用更多上下文信息的问题。例如立体视觉[4]、[22]、图像分割[10]和对象分类[24]。
在多幅图像的三维重建中,如在立体视觉和运动结构中,也有大量的前期工作。我们不可能在这里公正地对待这些文献,但最近的调查包括[4]和[25],我们将在第八节进一步讨论这项工作。
三、场景理解的视觉线索
图像是由三维场景投影到二维上形成的。因此,只要给定一幅图像,真正的三维结构就不明确,因为一幅图像可能代表无限多的三维结构。然而,并非所有这些可能的三维结构都有同样的可能性。我们所处的环境结构合理,因此人类通常能够利用先前的经验推断出(几乎)正确的三维结构。
给定一幅图像,人类使用各种单眼线索来推断场景的三维结构。其中一些提示基于图像的局部属性,例如纹理变化和渐变、颜色、雾度和散焦[6]、[26]、[27]。例如,当以不同的距离或方向查看时,曲面的纹理会显示不同。带有平行线的平铺地板在图像中也会显示出倾斜的线条,这样远处的区域在线条方向上会有较大的变化,而附近的区域在线条方向上会有较小的变化。同样,在不同的方向/距离查看时,草地也会显示不同。我们将在我们的模型中捕捉这些线索。然而,我们注意到,单靠局部图像线索通常不足以推断三维结构。例如,蓝天和蓝色物体都会产生相似的局部特征;因此很难仅从局部特征估计深度。
人类在空间上“整合信息”的能力,即理解图像不同部分之间的关系,对于理解场景的三维结构至关重要。[27,第11章]例如,即使图像的一部分是均匀的、没有特征的灰色斑块,人们通常也可以通过查看图像的附近部分来推断其深度,从而识别该斑块是否是人行道、墙等的一部分。因此,在我们的模型中,我们还将捕获图像不同部分之间的关系。
人类认识到许多视觉线索,比如某一特定形状可能是一座建筑物,天空是蓝色的,草是绿色的,树长在地面上,上面有叶子,等等。在我们的模型中,单目线索与三维结构的关系,以及图像各部分之间的关系,都将通过监督学习来学习。具体来说,我们的模型将被训练成使用一个训练集来估计深度,在这个训练集中,地面真实深度是使用激光扫描仪收集的。
四、表示
我们的目标是从图像中创建一个完整的照片真实的三维模型。在计算机图形学和其他相关领域中的三维模型的大部分工作之后,我们将使用三维模型的多边形网格表示,其中我们假设世界是由一组小平面组成的。1
详细地说,给定场景的图像,我们首先在图像中找到小的均匀区域,称为“超级像素”[10]。每个这样的区域表示场景中的相干区域,所有像素具有相似的特性。(见图2)我们的基本表示单位是世界上的这些小平面,我们的目标是推断每个平面的位置和方向。


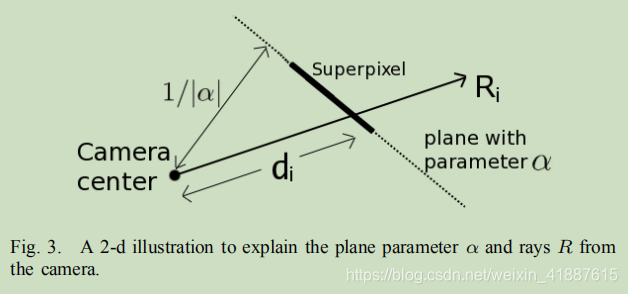
五、概率模型
仅从局部线索很难推断出一个区域的三维信息(见第三节),需要根据其他区域的三维信息推断出一个区域的三维信息。
在我们的MRF模型中,我们尝试捕获图像的以下属性:
- 图像特征和深度:超级像素的图像特征与超级像素的深度(和方向)有一定关系。
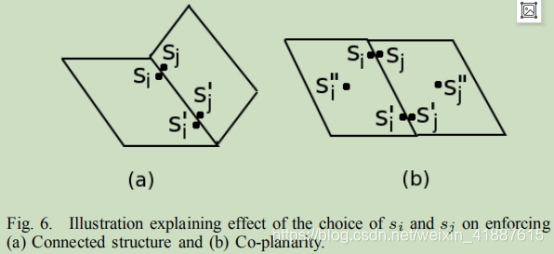
- 连通结构:除遮挡情况外,相邻的超混合体更容易相互连通。
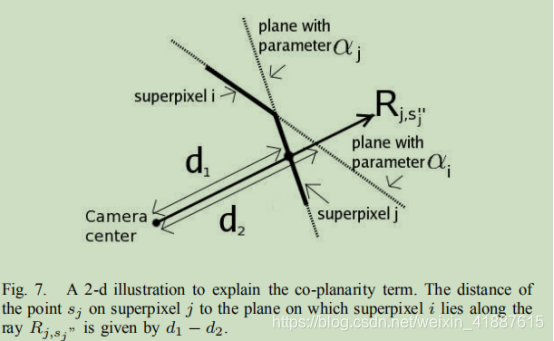
- 共面结构:如果相邻的超混合体具有相似的特征并且它们之间没有边,那么它们更可能属于同一平面。
- 共线性:图像平面中的长直线更可能是三维模型中的直线。例如,建筑物的边缘,人行道,窗户。
注意,这四个性质中没有一个本身就足以预测三维结构。例如,在某些情况下,局部图像特征不是深度(和方向)的强指示器(例如,在没有特征的空白墙壁上的补丁)。因此,我们的方法将在mrf中组合这些属性,其方式取决于我们对每个属性的“置信度”。在这里,“置信度”本身是根据本地图像提示来估计的,并且会因图像中的区域而异。








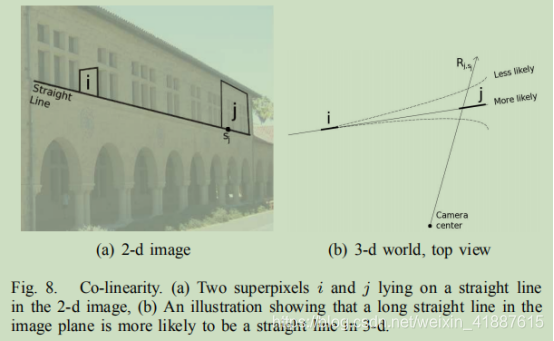
共线性:考虑二维图像中长直线上的两个超混合i和j(图8a)。有无穷多个投影到图像平面中直线的曲线;但是,图像平面中的直线更有可能是三维中的直线(图8b)。因此,在我们的模型中,我们将惩罚点(如)与理想直线的相对(分数)距离。



六、特征
对于每个超级像素,我们计算一组特征来捕获第三节中讨论的一些单眼线索。我们还计算特征来预测图像中有意义的边界,例如遮挡和褶皱。我们依赖于大量不同类型的特征,使我们的算法更加健壮,甚至可以将其推广到与训练集非常不同的图像。

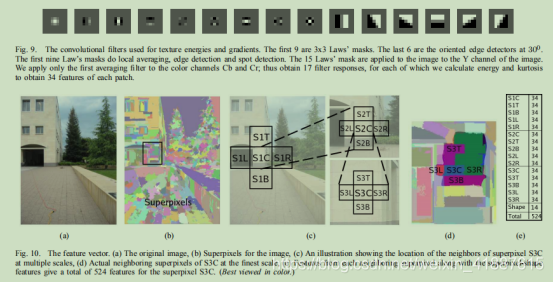

七、实验
A.数据收集
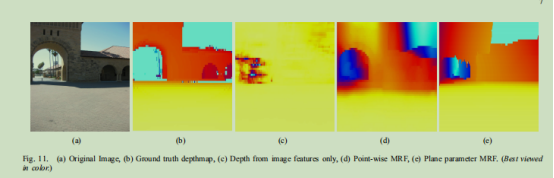
我们使用定制的三维扫描仪来收集图像(如图11a)及其相应的深度图(如图11b)。我们收集了534幅深度图,图像分辨率2272x1704,深度图分辨率55x305,并使用400幅来训练我们的模型。这些图像是白天在帕洛阿尔托市及其周边地区的不同城市和自然区域收集的。
我们在134张图片(使用我们的三维扫描仪收集)和588张互联网图片上测试了我们的模型。这些图片是通过在google图片搜索中发布关键词来收集的。为了收集数据并以完全公正的方式对算法进行评估,要求与项目无关的人员收集环境图像(大于800x600大小)。该人士选择了以下关键词来收集图像:校园、花园、公园、房屋、建筑、学院、大学、教堂、城堡、庭院、广场、湖泊、寺庙、场景。这样收集的图像来自世界各地,所包含的环境与训练集有着显著的不同,例如山、湖、夜景等。人们只选择那些“环境”的图像,即,在搜索关键字"方形"时,删除了几何图形"方形"的图像;没有其他对数据进行了预筛选。
B.结果和讨论
我们对588幅互联网测试图像和134幅激光扫描仪采集的测试图像进行了广泛的评估。
在表格一中,我们比较了以下的算法:
(a)基线:点式MRF(基线-1)和平面参数MRF(基线-2)。基线MRF是在没有任何的图像特征的情况下训练,因此会重新选择一个“优先”的深度图排序。
(b)我们的点式MRF:有约束和没有约束(连通性、共面性格共线性)。
(c)我们的平面参数MRF(PP-MRF):没有任何约束,只有共面约束,全模型。
(d)Saxena等人(SCN),[6],[21]仅适用于定量误差。
(e)Hoiem等人(呵呵)[9]。为了公平起见,我们在计算错误之前缩放并移动它们的深度映射,以匹配测试图像的全局尺度。没有标度和偏移,它们的误差要高得多(相对深度误差为7.533)。
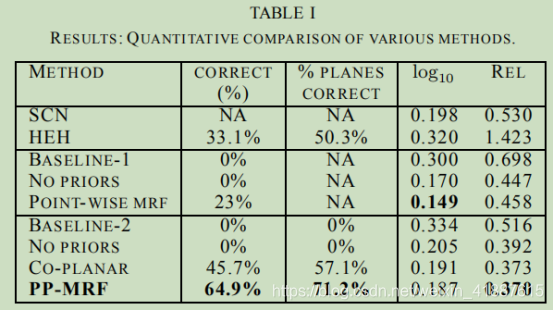

表1显示,我们的模型(点式MRF和平面参数MRF)在深度预测的定量精度方面都优于其他算法。平面参数MRF提供更好的相对深度精度,并产生更尖锐的深度图(图11、12和13)。表1还显示,通过捕获连通结构、共面性和共线性的图像特性,该算法生成的模型变得明显更好。除了减少定量误差外,PP-MRF确实产生了更好的三维模型。当生产三维五面图时,即使定量数字可能仍然显示出小的误差。


我们的算法对64.9%的图像给出了定向正确的模型,而HEH的正确率33.1%。定向评估由与项目无关的人员按照脚注6的准则进行。Delage,Lee和Ng[8]以及HEH通过在“地面垂直”边界折叠图像来产生弹出效果——这一假设对于大量图像来说是不正确的。因此,我们的方法在这些图像中失败。三维模型的一些典型示例如图14(注意,图1、13、14和15所示的所有测试用例都来自从互联网下载的数据集,图15a除外,图15a来自激光测试数据集。)这些示例还表明,我们的模型通常更为详细,因为它们通常能够用多个(超过100个)平面来模拟场景。
我们做了进一步的比较。即使这两种算法在图像上都被定性地评价为正确的,有一种结果仍然可能是优越的。因此,我们让这个人比较这两种方法,并决定哪一种更好,还是平手。2表二显示,我们的算法在62.1%的情况下输出更好的模型,而HEH在22.1%的情况下输出更好的模型(与其他情况相同)。
完整的文档描述了无偏人类判断过程的细节,以及由我们的算法生成的三维五线谱,可在以下网站上获得:http://make3d.stanford.edu/research
我们的一些模型,如图15J中的模型,有外观缺陷——如拉伸纹理;更好的纹理渲染技术将使模型更具视觉美感。在某些情况下,一个小错误(例如,在图15h中,一个人被检测到在远处,而在图15k中,横幅被弯曲)会使模型看起来很糟糕,因此被评估为“不正确”。
最后,在一个大规模的网络实验中,我们允许用户将他们的照片上传到互联网上,并通过我们的算法查看由他们的图像生成的三维图片。约有23846名用户上传(并评级)了约26228张图片。3位用户评价48.1%的车型为好。如果我们只考虑场景的图像,即排除诸如公司标志、卡通人物、物体特写等图像,那么这个百分比是57.3%。我们提供了以下网站,用于下载数据集/代码,以及将图像转换为三维模型/浏览:http://make3d.stanford.edu
我们的算法是在帕洛阿尔托市周围白天拍摄的图像上训练的,能够对各种环境(例如,有上或湖的环境、夜间拍摄的环境,甚至绘画)的三维模型进行定性正确的预测。(参见图15和网站)我们相信,根据我们对不同数量的训练示例(这里没有报道)的实验,拥有更大和更多样化的训练图像集将显著改进算法。



八、来自多幅图像的更大的三维模型
由一副图像建立的三维模型几乎总是不完整的场景模型,因为场景的许多部分将丢失或被遮挡。在这一节中,我们将使用单目和多视图三角剖分线索来创建更好和更大的三维模型。
给定场景的一组稀疏图像,有时可以使用诸如运动结构(SFM)[5]、[32]等技术来构建三维模型,这些技术首先拍摄两张或更多照片,然后找到图像之间的对应关系,最后使用三角剖分来获得点的三维位置。如果图像是从附近的相机拍摄的(即,如果基线距离很小),那么这些方法对于远离相机的点通常会遭受较大的三角测量误差。4相反,如果选择相隔较远的图像,则视点的改变通常会导致图像变得非常不同,从而很难找到对应关系,有时会导致虚假或遗漏对应关系。(更糟的是,大基线也意味着图像之间可能几乎没有重叠,因此甚至可能存在一些对应关系。)这些困难使得纯几何3-D重建算法在许多情况下失败,特别是当只给出一小组图像时。
然而,当数以万计的图片可用时——例如,对于经常拍照的旅游景点,例如国家纪念碑——人们可以使用在许多视图中呈现的信息来可靠地丢弃只有很少的对应匹配的图像。这样做,一个人只能使用一小部分可用的图像(~15%),仍然可以获得“三维点云”的点匹配使用SFM。这种方法已经非常成功地应用于著名的建筑,如圣母院;这种算法的计算成本非常高,并且需要大约一周的时间在一组计算机上运行[33]。
许多基于几何“三角剖分”的方法有时会失败(特别是当只有少数场景图像可用时),原因是它们没有利用单个图像中的信息。因此,我们将扩展我们的mrf模型,以无缝地结合三角剖分和单目图像的线索,以建立一个完整的照片真实的三维场景模型。使用单眼提示也将帮助我们建立仅在一个视图中可见的零件的三维模型。




D.幻影飞机
此提示在多个摄影机之间强制执行遮挡约束。具体地说,每个小平面(超级像素)都来自于由特定相机拍摄的图像。因此,在相机和那个小平面的三维位置之间必须有一个未被遮挡的视图——也就是说,这个小平面必须从拍摄它的照片的相机位置可见,并且任何其他小平面(一个来自不同的图像)都不可能有一个遮挡这个视图的三维位置。这个线索很重要,因为通常连接的结构项,非正式地试图将两个小平面中的点“连接”在一起,会导致模型与此遮挡约束不一致,并导致我们称之为“幻像平面”的结果,即,从拍摄它的相机看不到的平面。我们通过寻找额外的对应点来惩罚有问题的幻影平面和遮挡它的相机视图的平面之间的距离。这往往会使两个平面位于完全相同的位置(即具有相同的平面参数),从而消除幻影/遮挡问题。
E.实验
在这个实验中,我们创建了一个场景的真实感三维模型,只给出了一些图像(位置/姿势未知),甚至是从非常不同的视角拍摄的图像或很少重叠的图像。图19、20、21和22显示了由我们的算法创建的一些三维模型的快照。使用单目线索,我们的算法能够创建完整的三维模型,即使大部分图像没有重叠(图19、20和21)。在图19中,单图像的单目预测(未示出)给出了在图像中未能捕获拱形结构的近似3-D模型。然而,使用单眼和三角测量线索,我们能够捕捉到这个三维拱形结构。这些型号可从以下网址获得:http://make3d.stanford.edu/research
http://make3d.stanford.edu/research
九、纳入对象信息
在本节中,我们将演示我们的模型如何还可以合并其他可能可用的信息,例如,来自对象识别器的信息。在以前的工作中,Sudderth 等人[36]表明物体的知识可以用来获得粗略的深度估计,Hoiem等人[11]利用对物体及其位置的了解来改进对地平线的估计。除了估计视界外,物体的知识和它们在场景中的位置也提供了关于场景三维结构的强有力的线索。例如,一个人更可能站在地面上,而不是在地面下,这就对三维模型施加了某些限制,这些限制可能对给定的图像有效。
在这里,我们给出了一些有关对象的信息可用是出现的此类提示的示例,并描述了如何在MRF中对它们进行编码:



十、总结
提出了一种从单个静止图像中推断三维结构细节的算法。与以前的方法相比,我们的算法创建了详细的三维模型,这些模型在数量上更精确,在视觉上更令人满意。我们的方法首先将图像过度分割成许多称为“超级像素”的均匀区域,然后使用MRF推断每个区域的三维位置和方向。除了假设环境是由许多小平面构成外,我们没有对场景的结构做出任何明确的假设,例如Delage等人的假设。[8]和Hoiem等人。[9]场景包括竖立在水平地板上的垂直表面。这使得我们的模型能够很好地推广,甚至可以推广到具有显著非垂直结构的场景。与现有技术相比,我们的算法在预测深度的定量精度和定性校正模型的分数方面都有显著的改善。最后,我们将这些思想扩展到使用稀疏图像集建立三维模型,并展示了如何将目标识别信息合并到我们的方法中。
深度知觉问题是计算机视觉的基础,在过去的几十年里,它引起了许多研究者的关注,并取得了重大进展。然而,这项工作的绝大多数,如立体视觉,都使用了多个图像几何线索来推断深度。相比之下,单一的图像线索提供了一个很大程度上正交的信息来源,一个迄今为止一直被相对开发不足的信息来源。鉴于深度和形状感知似乎是许多其他应用的重要组成部分,例如对象识别[11]、[38]、抓取[39]、导航[7]、图像合成[40]和视频检索[41],我们相信单目深度感知有潜力改进所有这些应用,尤其是在场景只有一个图像可用的设置中
致谢
我们感谢Rajiv Agarwal和Jamie Schulte在收集数据方面的帮助。我们还感谢杰夫·米歇尔斯、奥尔加·罗斯科夫斯基和塞巴斯蒂安·特龙的有益讨论。这项工作得到了国家科学基金会CNS-0551737奖、海军研究办公室Muri N000140710747和Pixblitz工作室的支持
对于大多数人工结构,如建筑物,这种假设是相当准确的。一些自然结构,如树木,也许可以更好地用圆柱来表示。然而,由于我们的模型非常详细,例如,对于一个小场景,大约有2000个平面,因此平面假设在实践中非常有效。 ↩︎
为了比较这些算法,研究人员被要求计算每种算法的错误数。当图像中的主平面(占图像面积的15%以上)相对于其相邻平面处于错误位置,或者平面的方向错误超过30度时,我们定义一个错误。例如,如果在错误的地方折叠图像(参见图14,图像2),则将其计为错误。同样地,如果我们预测建筑物的顶部远,底部近,使建筑物倾斜,这将被视为一个错误。 ↩︎
对用户可以上传的图像类型没有限制。用户可以将模型评为好(拇指向上)或坏(拇指向下)。 ↩︎
即,对于远距离的物体,深度估计往往不准确,因为即使三角测量中的小误差也会导致深度的大误差 ↩︎

















 4660
4660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









