







为什么要倾向值匹配?
样本选择偏误会带来内生性问题:
比如在比较读研究生对于工资的影响时,要选择能力、智商、家庭背景、工作单位等都差不多的样本进行比较,所以需要样本匹配.
样本匹配的核心
- 共同支撑假设
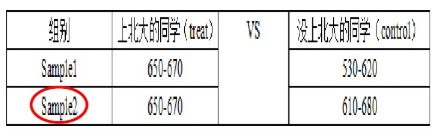
- 平行假设
方法与举例
小明读研究生和没读研究生的工资差距多少?
这是一个反事实问题,因为事实上他已经读了
使用倾向值匹配,从一大堆没读研究生的人(样本子集)中,对每个人读研究生的概率进行估计(logistic回归),找到与小明有差不多读研概率但没读的小强,作为小明的对照。
步骤
对总体样本进行 logit 或 probit 回归
估计出每一个观测对象读研的概率
根据读研概率,把读研的和没读研的配对起来,得到实验组和对比组
++++++++++以下为stata实现+++++++++++++++++
# probit 回归
probit [dependent var] [independent var]
# [dependent var] 是01变量
# [independent var] 是普通变量
# 根据 probit 模型计算出每个样本的读研概率
predict pscore, p
# pscore 是纪律每个观测对象读研概率的变量
倾向值匹配
psma 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









