







 本文介绍了倾向值匹配(PSM)的基本思路和使用方法,旨在消除研究中的选择性偏误。通过匹配和计算个体接受处理的倾向性,确保实验组和控制组在关键协变量上的平衡,从而准确评估处理效果。匹配方法包括精确匹配、倾向值匹配等,使用R语言的MATCHIT包可实现匹配过程。在分析治疗效应前,需确保所有关键协变量达到平衡状态。
本文介绍了倾向值匹配(PSM)的基本思路和使用方法,旨在消除研究中的选择性偏误。通过匹配和计算个体接受处理的倾向性,确保实验组和控制组在关键协变量上的平衡,从而准确评估处理效果。匹配方法包括精确匹配、倾向值匹配等,使用R语言的MATCHIT包可实现匹配过程。在分析治疗效应前,需确保所有关键协变量达到平衡状态。
在研究一些treatment effect的时候,为了避免选择性偏误(selection bias),我们有时会用matching选一个控制组。Propensity score matching是matching的方法之一。下面我来简单介绍一下PSM的逻辑以及使用方法。我认为,如果条件允许,我们不该只学习方法而不去理解方法的原理。
1. 匹配、倾向值匹配的基本思路
下图展示了一个简化了的但典型的对某种政策、药物等的treatment effect进行研究的概念框架。以我之前的一项研究为例,我的目的是探究科学家从海外跳槽到中国大陆之后业绩有没有变好,在这里,接受treatment指的就是跳槽到中国大陆,outcome指的就是业绩变化。
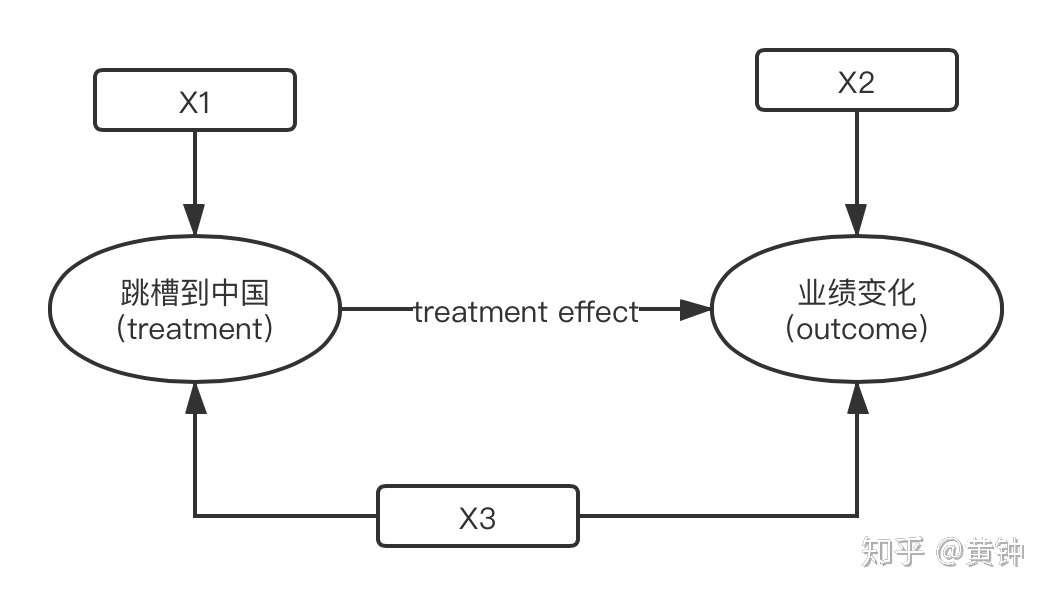
整个过程涉及到的协变量可以被分为三类:
X1:仅对是否接受treatment有影响的变量,比如这位科学家是不是很喜欢大陆
X2:仅对outcome有影响的变量,比如这位科学家来大陆之后生活是否适应
X3:对是否接受treatment和outcome都有影响的变量,比如他是不是处在上升期(中国大陆的人才引进政策主要针对的是正处在上升期的科学家)
在这个框架之下,如果我们研究的对象是treatment effect
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3640
3640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









