







前言
~~~
在上一章节influxDB概念详解1,解释了influxDB的一些基本概念,主要是tag,measurement,series等一些基本的概念。有些概念和我们常用的DBMS有点像。上一节介绍的概念大多数都是时序领域一些常用的概念,或者说大家公认的。在influxDB里面,还有很多自己特有的概念,大多数都是和influxDB存储和查询模型相关的。这一节主要是介绍这些概念。
~~~
这一部分的概念大部分还是来源于官方的文档,以及自己补充一些自己的理解,有理解的不到位,还多包涵!
概念详解
series
~~~
series也叫做序列,这个概念其实在大多数时序数据库里面都有。在influxDB的概念是:
 解释一下就是一个series指的是**(measurement,tag set,field key**)定义的一组数据。
解释一下就是一个series指的是**(measurement,tag set,field key**)定义的一组数据。
比如下面有一组关于cpu的数据,和一组关于memory的数据
| timestamp | host | rock | usage | load |
|---|---|---|---|---|
| 1648974723 | 1.2.3.4 | rock1 | 0.33 | 2 |
| 1648974743 | 1.2.3.5 | rock2 | 0.34 | 3 |
这组数据就有两个series,首先measurement是cpu,tag有两个,分别是host和rock,代表了这个cpu的host的所在的rock(机架)。field有两个,usage和load,代表这个时刻的cpu.load 和cpu.usage。按照定义tag set是固定的,field就是usage和load,所以就是两个series。
~~~
这里的seires的概念和其他时序数据库有点出入,比如openTSDB定义的series是(name,tagK,tagV),也就是每个name+tagK+tagV唯一确定了一个series。
series cardinality
~~~
series的大小,这个一般也叫series的维度。看一下定义
 这个其实通俗点解释就是这个series有多少种组合情况。举个例子,还是官网上给的例子。
这个其实通俗点解释就是这个series有多少种组合情况。举个例子,还是官网上给的例子。
~~~
假设influxDB里面现在只有一个数据,一个measurement,一个field,如下所示
这个measurement有两个tag(email,和status)

ETiBATWF0cml4WWc=,size_20,color_FFFFFF,t_70,g_se,x_16)因为email有三种选择,status有两种选择,所以这个series的维度就是6(2*3)
~~~
那么计算series的维度是不是就是简单等于各个tag的维度相乘呢?其实不是的,series大小本质上是表示了这个series现在有多少种不同,例如,在上述的tag set里面加上一个tag firstname
 这里的firstname与也有三种选择,但是维度不是在原来的基础上*3,而是6,这里我想不难理解,因为通过数学计算得到的维度,是所有的可能性,但是有的其实是没有出现的。**所以维度的计算不是简单的相乘。**所以你会发现,可能计算维度不是那么简单,所以influxDB查看一个measurement的维度,有具体的SQL
这里的firstname与也有三种选择,但是维度不是在原来的基础上*3,而是6,这里我想不难理解,因为通过数学计算得到的维度,是所有的可能性,但是有的其实是没有出现的。**所以维度的计算不是简单的相乘。**所以你会发现,可能计算维度不是那么简单,所以influxDB查看一个measurement的维度,有具体的SQL
-- show estimated cardinality of measurement set on current database
SHOW MEASUREMENT CARDINALITY
-- show exact cardinality of measurement set on specified database
SHOW MEASUREMENT EXACT CARDINALITY ON mydb
第一个是估计值,第二个是准确值。
Shard
~~~
到这里就是和influxDB怎么存储数据强相关了。shard翻译过来也叫分片。聊到这里可能有些同学不是很了解。分片存储是现在分布式存储种常用的概念。和分库分表是一个道理。假设现在你有一张MySQL的表,这张表数据量很大,而且增长很快。可能会做一下分表的。
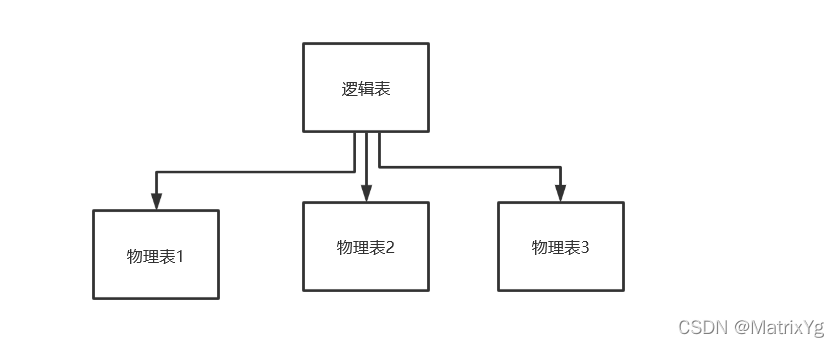 这里每个物理表,就是一个shard,或者叫做一个分片。这里应该就比较好理解了。知道了shard的一般用法,看一下influxDB关于shard的定义
这里每个物理表,就是一个shard,或者叫做一个分片。这里应该就比较好理解了。知道了shard的一般用法,看一下influxDB关于shard的定义
 ~~~
这里和我们的理解的基本是一致的,一个shard就是编码压缩后的数据真实存储的位置。这种数据被组织成了一个TSM的结构。并且每一个shard属于一个shard group。后面还有一些特性,先说一下,虽然可能不好理解。**在一个shard里面,series相同的点,会被存储在一个TSM里面。**这里可以看出来,series其实还是非常重要的,是贯穿了存储和查询的概念。如果这里不理解没关系,等后面看代码就知道咋回事了。
~~~
这里和我们的理解的基本是一致的,一个shard就是编码压缩后的数据真实存储的位置。这种数据被组织成了一个TSM的结构。并且每一个shard属于一个shard group。后面还有一些特性,先说一下,虽然可能不好理解。**在一个shard里面,series相同的点,会被存储在一个TSM里面。**这里可以看出来,series其实还是非常重要的,是贯穿了存储和查询的概念。如果这里不理解没关系,等后面看代码就知道咋回事了。
Shard group
~~~
上面还提到了一个概念:shard group。shard group其实是一个逻辑的概念,shard是一个物理的概念。这里逻辑的概念指的是之存在于理解和代码种,存储到磁盘时,是没有shard group相关的信息存储的。shard group是对shard的分组,那么分组的依据是什么呢?
~~~
时序数据有一个非常重要的特点就是时间属性很强,比如一些机器监控数据,大家可能只关心最近两天的数据,比如你会关心一年前机器的cpu 使用率是多少吗?(PS:也可能关心,比如每年一度的活动的时候,会环比去年同期)大部分场景下,还是关注的是最近的数据。所以在时序数据种,数据过期和保留策略就很重要。这个在influxDB里面,叫做retention policy。shard group是一个和retention policy强相关的概念。
Shard Duration
~~~
上面提到了,shard group是一组逻辑的概念,并且和retention policy紧密相关。决定了一个shard group的有限期是多长时间的东西,叫做Shard Duration。
 ~~~
这里解释了shard duration的概念。并且举了个例子,假设给的shard duration是1w(week),那么这一周创建的shard,都是属于一个shard group内(也就是说这一周不会有新建shard group的操作出现)。
~~~
这里解释了shard duration的概念。并且举了个例子,假设给的shard duration是1w(week),那么这一周创建的shard,都是属于一个shard group内(也就是说这一周不会有新建shard group的操作出现)。
retention policy
~~~
retention policy也叫数据保留策略,是一个非常重要的概念。而且这不是一个逻辑概念,retention policy是直接能够在存储的时候非常明显的体现出来。
~~~
先看看官网是怎么说的:
 ~~~
用的六级刚过的英文翻译一下。retention policy是描述了influxDB把数据保留多久,数据有多少个副本(replication factor),以及一个shard group的时间范围。这里面数据保留多久和shard group的范围我想都是能够理解的,对于replication factor解释一下,可能有人刚接触这个概念。
~~~
用的六级刚过的英文翻译一下。retention policy是描述了influxDB把数据保留多久,数据有多少个副本(replication factor),以及一个shard group的时间范围。这里面数据保留多久和shard group的范围我想都是能够理解的,对于replication factor解释一下,可能有人刚接触这个概念。
~~~
replication factor,指的是一个数据的副本数量。在分片存储的环境下,数据副本是非常重要的。因为一旦shard 损坏,那么造成数据丢失,所以为了应对这种缺陷,就会采用副本(replica).shard1和shard2互为副本,写入shard1的数据同时也会写入到shard2,一旦shard1有损坏,那么就可以使用shard2来顶替。这里的副本数量值得就是,对于一个shard,给他配置多少个副本。
TSM (Time Structured Merge tree)
~~~
这个概念来自于LSM,其实本质上就是LSM tree,从源码上来看,区别不是很大。TSM指的是influxDB的存储引擎
 ~~~
这个了解LSM tree的同学可能会有一些概念,这个不了解的可以找找相关的资料看看,难度不是很大。
~~~
这个了解LSM tree的同学可能会有一些概念,这个不了解的可以找找相关的资料看看,难度不是很大。
总结
~~~
这一篇描述的是一些influxDB中,不是很常用的概念,或者稍微的高级一点的概念。有些是时序存储的一些标准,有些事influxDB自己定义的。
其实很多人在理解series,shard,shard group ,shard duration,retention policy这些概念比较苦难,有两张图:
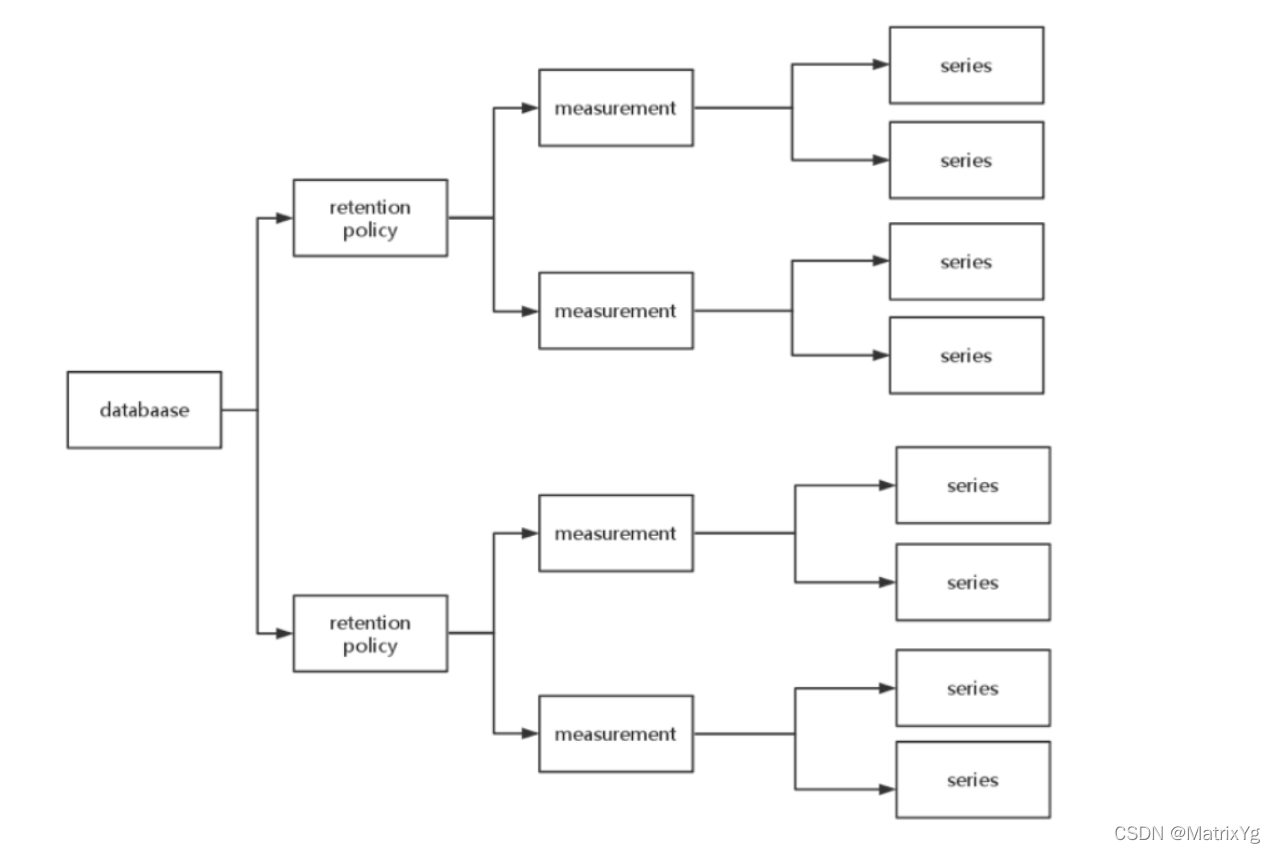 这张图说明了database,retention policy,measurement以及series上面的包含关系。
这张图说明了database,retention policy,measurement以及series上面的包含关系。
还有在存储上的关系
 这张图基本的概括了influxDB的架构,可以看到每个database都是分开存储的,database下面,每个retention policy也是分开存储的,retention policy下面就是每个shard,这里没有shard group,因为shard group是一个逻辑概念,不体现在存储上。
这张图基本的概括了influxDB的架构,可以看到每个database都是分开存储的,database下面,每个retention policy也是分开存储的,retention policy下面就是每个shard,这里没有shard group,因为shard group是一个逻辑概念,不体现在存储上。
引用说明
后面两张图是参考了一些资料。
- [ x] https://www.cnblogs.com/kakashiS/p/12058712.html
后面的那一张,是很久之前我保存到手机上的,所以找不到链接了,如果有侵权的地方可以联系我加上相关的引用链接或者删除。


















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









