




 本文对比介绍BLS和Ensemble两种实现TritonPipelines的方式,并对高性能部署Yolov5Tritonservice的Benchmark性能测试结果进行解读。BLS通过Python代码调用其他模型服务,适用于动态组合已部署模型;Ensemble则可以并行执行多个模型步骤,减少请求数量,提高整体性能。
本文对比介绍BLS和Ensemble两种实现TritonPipelines的方式,并对高性能部署Yolov5Tritonservice的Benchmark性能测试结果进行解读。BLS通过Python代码调用其他模型服务,适用于动态组合已部署模型;Ensemble则可以并行执行多个模型步骤,减少请求数量,提高整体性能。
Triton Pipeines的实现方式及对比
在部署yolov5 Triton Pipelines中,简单介绍了BLS和Ensemble这两种实现Triton Pipelines的方式,同时在高性能部署Yolov5 Triton service的Benchmark中,对两种Pipelines和All in TensorRT Engine的部署方式进行了性能测试,本文将对比介绍一下BLS和Ensemble, 同时对性能测试的结果进行解读。
1. Python Backend
1.1 实现方式及结构
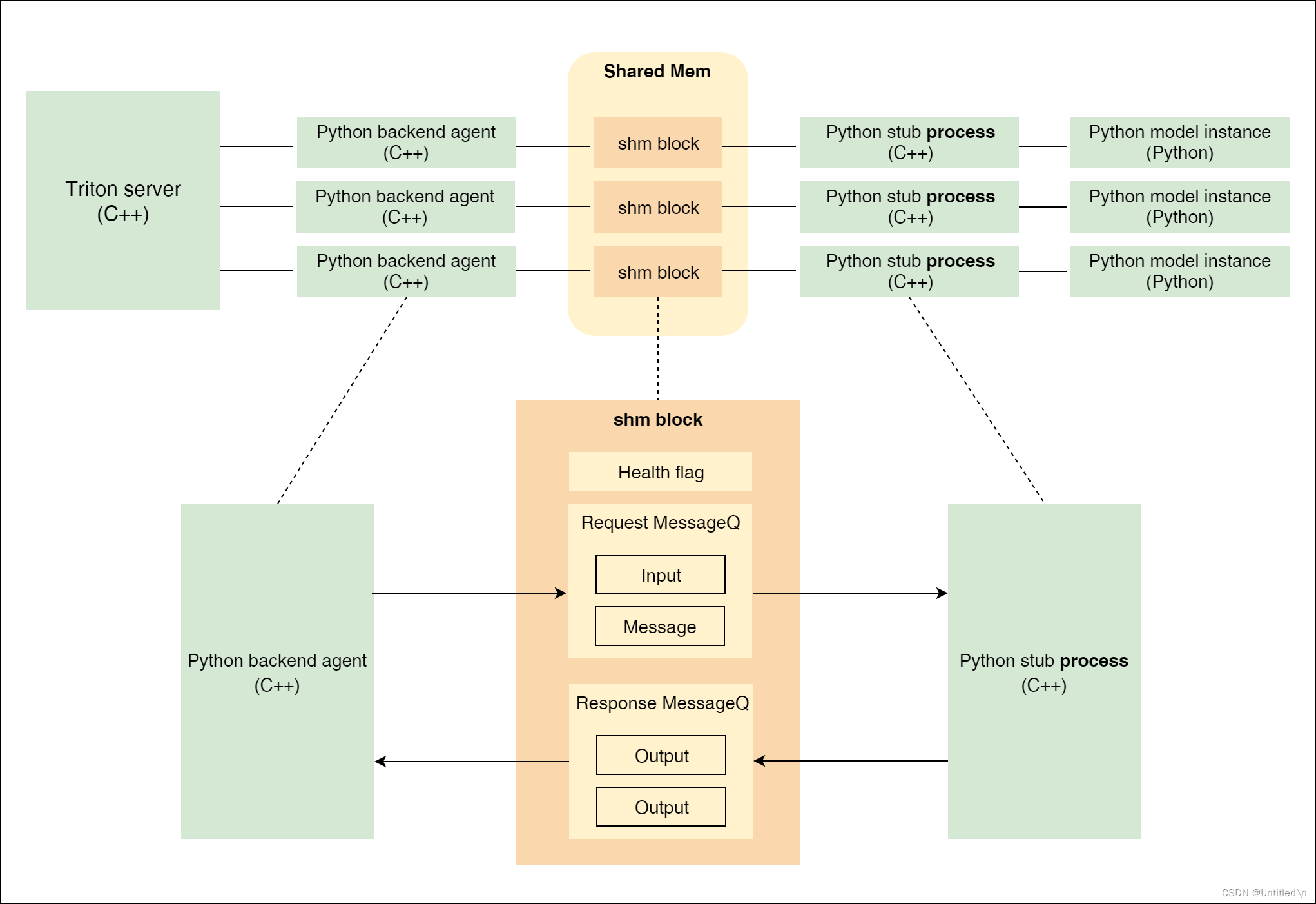
BLS是一种特殊的python backend,通过在python backend里调用其他模型服务来完成Pipelines。python backend的结构如下
-
进程间通信IPC
由于GIL的限制,python backend通过对每个model instance起一个单独的进程(
python stub process(C++))来支持多实例部署。既然是多进程,那么就需要通过shared memory来完成python model instance和Triton主进程之间的通信,具体为给每个python stub process在shared memory里分配一个shm block, shm block连接python backend agent(C++)来进行通信。 -
数据流向
shm block通过Request MessageQ和Response MessageQ调度和中转Input和Output, 上述两个队列均通过生产者-消费者模型的逻辑实现- 发送到Triton server的request被
python backend agent(C++)放到Request MessageQ - python stub process从
Request MessageQ取出Input, 给到python model instance执行完推理后,将Output放到Response MessageQ python backend agent(C++)再从Response MessageQ中取出Output,打包成response返回给Triton server主进程
示例如下:
responses = [ - 发送到Triton server的request被
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









