






在介绍ACK参数之前,先介绍几个概念
基本概念topic、partition、replication、leader、follower
对于kafka的每一个topic,我们都可以设置他有几个Partition,每个Partition负责存储这个Topic一部分的数据。然后Kafka的Broker集群中,每台机器上都存储了一些Partition,也就存放了Topic的一部分数据,这样就实现了Topic的数据分布式存储在一个Broker集群上。每个Partition都可以有多个副本,其中一个副本叫做leader,其他的副本叫做follower。这样的多副本冗余机制,可以保证任何一台机器挂掉,都不会导致数据彻底丢失,因为起码还是有副本在别的机器上的。KAFKA中任何一个Partition,只有Leader是对外提供读写服务的。也就是说,如果有一个客户端往一个Partition写入数据,此时就是写入这个Partition的Leader副本。然后Leader副本接收到数据之后,Follower副本会不停的给他发送请求尝试去拉取最新的数据,拉取到自己本地后,写入磁盘中。
什么是ACK?
ACK (Acknowledge character)即是确认字符,在数据通信中,接收站发给发送站的一种传输类控制字符。表示发来的数据已确认接收无误。在TCP/IP协议中,如果接收方成功的接收到数据,那么会回复一个ACK数据。通常ACK信号有自己固定的格式,长度大小,由接收方回复给发送方。
什么是ISR?
ISR全称是“In-Sync Replicas”,也就是保持同步的副本,他的含义就是,跟Leader始终保持同步的Follower有哪些。所以每个Partition都有一个ISR,这个ISR里一定会有Leader自己,因为Leader肯定数据是最新的,然后就是那些跟Leader保持同步的Follower,也会在ISR里。Leader负责跟踪与维护ISR列表。如果一个 Follower 宕机,或者落后太多(落后多少,由参数replica.lag.time.max.ms控制),Leader 将把它从 ISR 中移除。如果Leader发生故障或挂掉,一个新Leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为Leader,新的Leader继续服务客户端的读写请求。
什么是HW?
HW俗称高水位,是HighWatermark的缩写。它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
什么是LEO?
LEO (Log End Offset),标识当前日志文件中下一条待写入的消息的offset。LEO 的大小相当于当前日志分区中最后一条消息的offset值加1.分区 ISR 集合中的每个副本都会维护自身的 LEO ,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
下面具体分析一下 ISR 集合和 HW、LEO的关系。
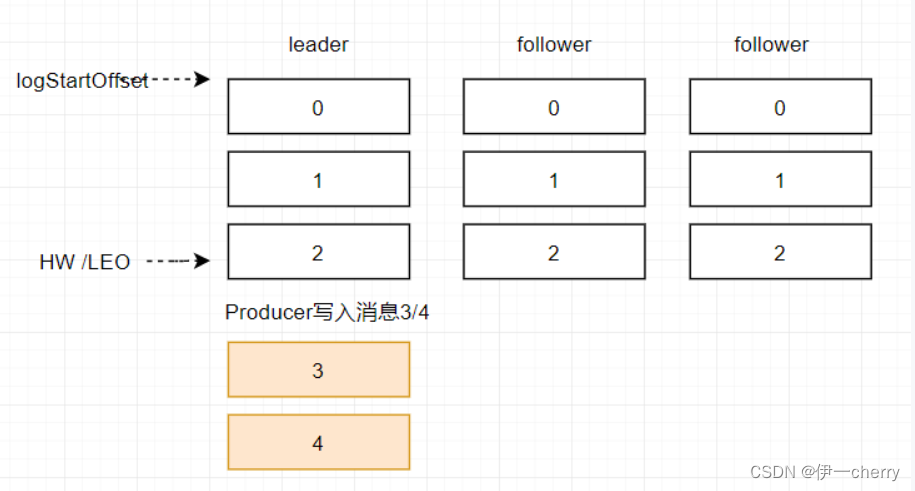
假设某分区的 ISR 集合中有 3 个副本,即一个 leader 副本和 2 个 follower 副本,此时分区的 LEO 和 HW 都分别为 3 。消息3和消息4从生产者出发之后先被存入leader副本。
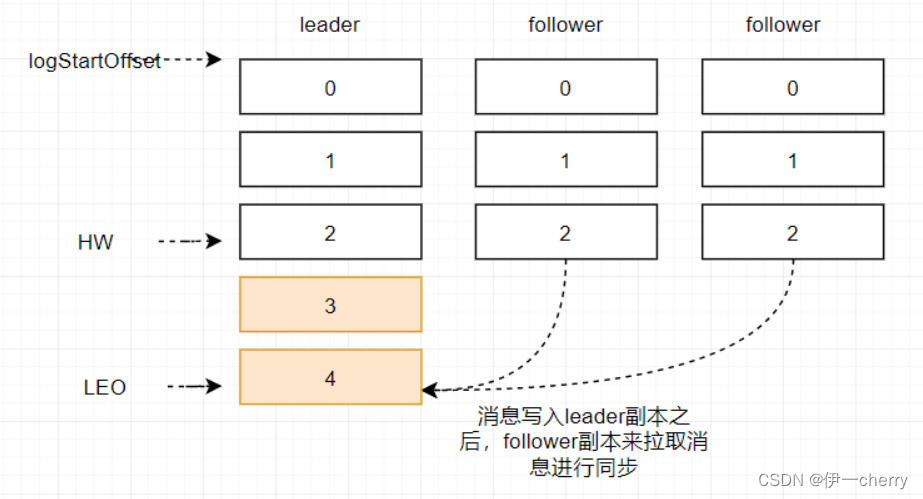
在消息被写入leader副本之后,follower副本会发送拉取请求来拉取消息3和消息4进行消息同步。
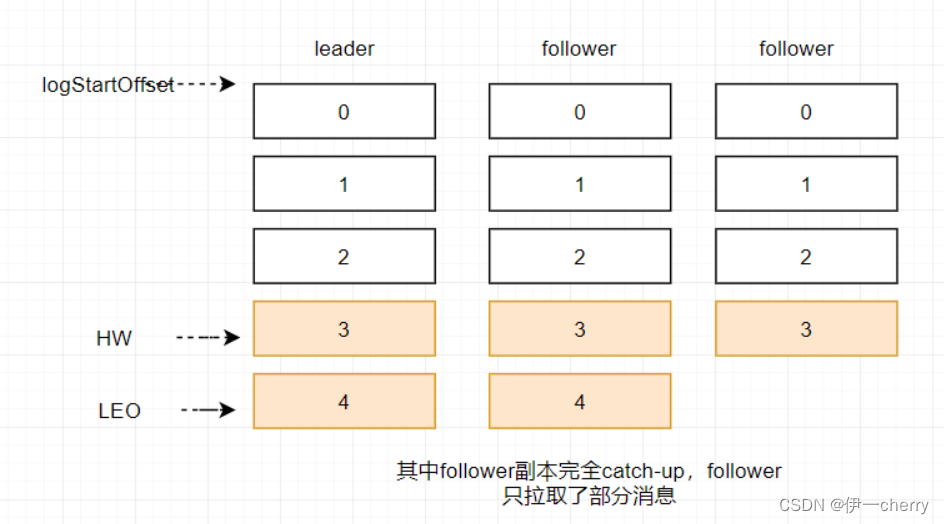
在同步过程中不同的副本同步的效率不尽相同,在某一时刻follower1完全跟上了leader副本而follower2只同步了消息3,如此leader副本的LEO为5,follower1的LEO为5,follower2的LEO 为4,那么当前分区的HW取最小值4,此时消费者可以消费到offset0至3之间的消息。
当所有副本都成功写入消息3和消息4之后,整个分区的HW和LEO都变为5,因此消费者可以消费到offset为4的消息了。
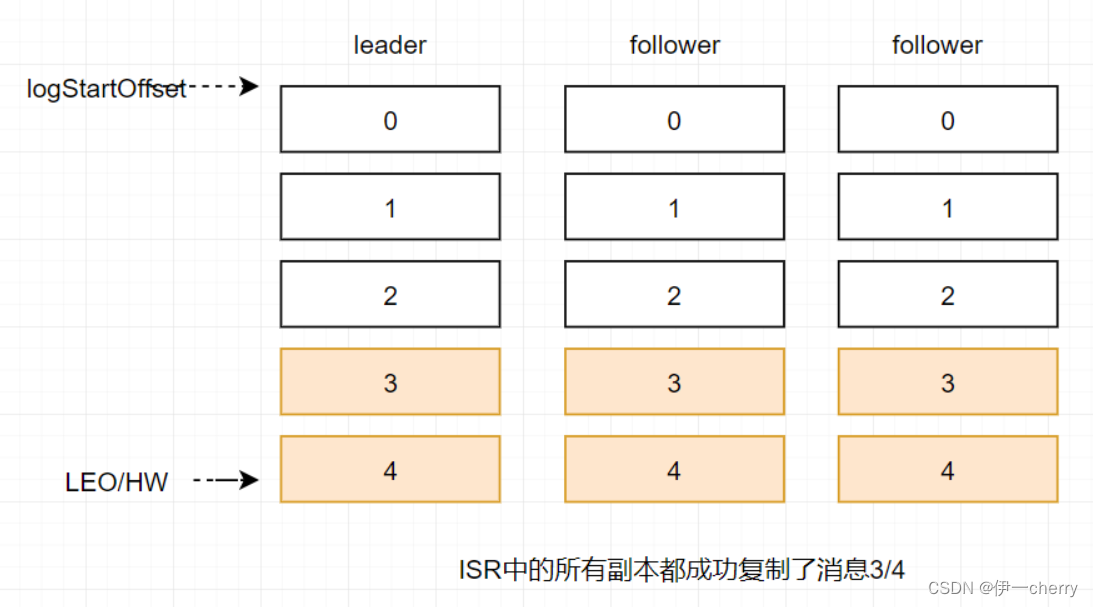
由此可见kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower副本都复制完,这条消息才会被确认已成功提交,这种复制方式极大的影响了性能。而在异步复制的方式下,follower副本异步的从leader副本中复制数据,数据只要被leader副本写入就会被认为已经成功提交。在这种情况下,如果follower副本都还没有复制完而落后于leader副本,然后leader副本宕机,则会造成数据丢失。kafka使用这种ISR的方式有效的权衡了数据可靠性和性能之间的关系。
ACK参数
铺垫了这么多,最后进入主题,聊一聊ACK参数。acks参数是在KafkaProducer,也就是生产者客户端里设置的。request.required.acks表示多少副本收到消息之后,生产者才会认为这条消息是成功写入。 它涉及可靠性和吞吐量之间的权衡。他有三个值:
1:leader接收到消息并成功写入,即返回成功响应。
0:生产者发送消息之后,不需要等待任何服务器的响应。
-1(all):生产者发送消息之后,需要等待ISR中所有副本都成功写入消息才能收到服务端的成功响应。
举个例子,当acks参数设置为-1时,producer写入消息流程如下:
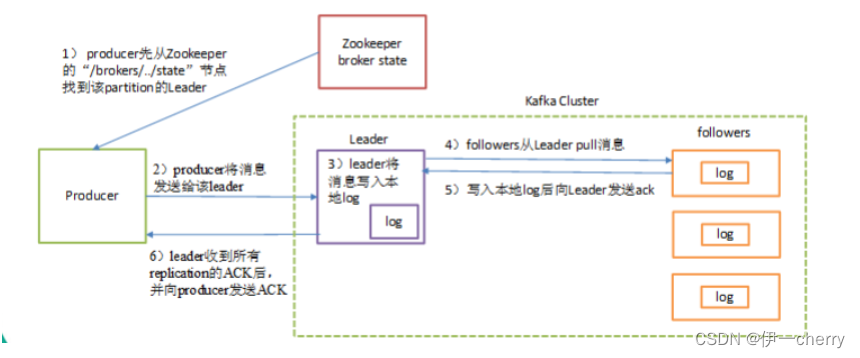
1)producer先从zookeeper的 "/brokers/.../state"节点找到该partition的leader
2)producer将消息发送给该leader
3)leader将消息写入本地log
4)followers从leader pull消息,写入本地log后向leader发送ACK
5)leader收到所有ISR中的replication的ACK后,增加HW(high watermark,最后commit 的offset)并向producer发送ACK


















 1115
1115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











