







XTuner大模型微调
前言
XTuner 是一个专注于 大模型微调(Fine-tuning) 的工具包,旨在帮助用户高效地对预训练的大语言模型(LLMs)进行微调,以适应特定任务或领域。它提供了灵活的配置、高效的训练流程以及丰富的功能支持,特别适合需要定制化大模型的应用场景。
一、环境的搭建
1,新建虚拟环境
conda create --name xtuner01 python==3.10 -y
conda activate xtuner01
#下载源码
git clone https://github.com/InternLM/xtuner.git
pip install -e ".[all]"
环境安装好后,先对里面要用的目录结构简单说明,
在代码包的config文件里包含了国内外绝大部分模型
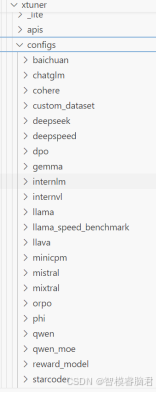
下面以qwen1_5_1_8b_chat为例
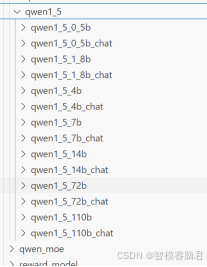
里面2个文件,一个全量微调,一个lora微调

二、数据整理
1,基座模型的准备和数据集的获取
本地没有基座模型,可以去huggingface或是魔塔社区下载
由于huggingface需要科学上网,建议去魔塔社区
https://modelscope.cn/home
1,模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen1.5-1.8B-Chat')
说明:
1).snapshot_download 是 Hugging Face 的 huggingface_hub 库中的一个函数,用于从 Hugging Face Hub 下载模型或数据集的快照(snapshot)。
2).下载的默认路径在默认使用 Hugging Face 的缓存目录(通常是 ~/.cache/huggingface),要指定路径,只需要加入参数cache_dir,比如:
model_dir = snapshot_download('Qwen/Qwen1.5-1.8B-Chat',cache_dir="/root/autodl-tmp/llm")
等待模型下载完成
2,数据集准备
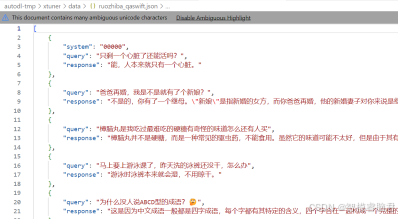
1,数据的下载
可以用自己的,也可以去魔塔社区,和模型下载一个网址.在社区搜索ruozhiba_qa问答数据集,数据集格式如下:
2,格式转换
需要转换成xtuner要求格式。可以去官网查看
Quickstart — XTuner 0.1.23 documentation
https://xtuner.readthedocs.io/en/latest/get_started/quickstart.html
转换脚本可以使用大模型自动生成:
比如这里使用deepseek
帮我转换一个json格式数据集,源数据格式如下:[{
"system": "00000",
"query": "只剩一个心脏了还能活吗?",
"response": "能,人本来就只有一个心脏。"
},
{
"query": "爸爸再婚,我是不是就有了个新娘?",
"response": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"
}]
目标格式如下
[{
"conversation":[
{
“input”:"你是谁",
“output”:"您好,我是AI小助手InternLM,请问有什么能帮你的"
}
]
}]
将以上信息输入大模型后,会生成转换脚本,然后对数据进行转换。下面是大模型生成转换脚本,只需要修改输入输出路径即可。
import json
def convert_format(source_data):
"""
将源数据格式转换为目标格式
"""
target_data = []
for item in source_data:
conversation = [
{
"input": item.get("query", ""), # 使用 query 作为 input
"output": item.get("response", "") # 使用 response 作为 output
}
]
target_item = {
"conversation": conversation
}
target_data.append(target_item)
return target_data
def convert_and_save(input_path, output_path):
"""
读取源数据,转换格式,并保存结果
:param input_path: 源数据文件路径
:param output_path: 转换后数据保存路径
"""
# 读取源数据
with open(input_path, "r", encoding="utf-8") as f:
source_data = json.load(f)
# 转换格式
target_data = convert_format(source_data)
# 保存转换后的数据
with open(output_path, "w", encoding="utf-8") as f:
json.dump(target_data, f, ensure_ascii=False, indent=4)
print(f"转换完成,结果已保存到: {output_path}")
# 示例调用
if __name__ == "__main__":
# 输入路径和输出路径
input_path = "source_data.json" # 源数据文件路径
output_path = "target_data.json" # 转换后数据保存路径
# 调用函数进行转换和保存
convert_and_save(input_path, output_path)
直接运行即可保存

下面是转换后的格式:
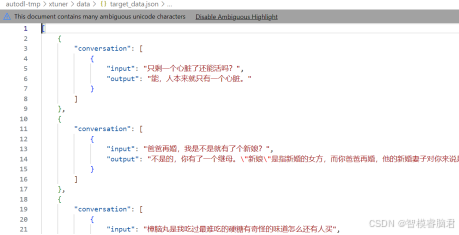
这个是单轮对话,就是每一个都是独立,如果是多轮对话,上下文有相关性,那就是一个conversion里多个input,output。
三、参数设置
训练前需要对相应的参数做修改.
在config里面找到模型对应的配置文件
qwen1_5_1_8b_chat_qlora_alpaca_e3.py
1,准备基座模型
首先是需要加载的基座模型,数据集的路径
pretrained_model_name_or_path = '/root/autodl< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









