




LMDeploy本地部署DeepSeek
前言
LMDeploy 是一个专为大语言模型(LLMs)和视觉-语言模型(VLMs)设计的高效且友好的部署工具箱。它集成了多种先进的技术和功能,有着卓越的推理性能、可靠的量化支持、便捷的服务部署以及极佳的兼容性
一、环境搭建
版本要求,CUDA 11+(>=11.3),python要求3.8 - 3.12之间.
获取代码,下面2种方法都可以.
1. pip
conda create -n lmdeploy python=3.8 -y
conda activate lmdeploy
pip install lmdeploy
2. git
git clone https://github.com/InternLM/lmdeploy.git
cd lmdeploy
pip install -e .
二、模型准备
1. 下模地址
1,huggingface
https://huggingface.io
需要梯子
2,魔塔社区
https://www.modelscope.cn
可直接访问
2. 选模
1,LLM(文本生成)
先来看看全球热度爆表的两款有着性价比之王赞誉的DeepSeek-R1和DeepSeek-V。

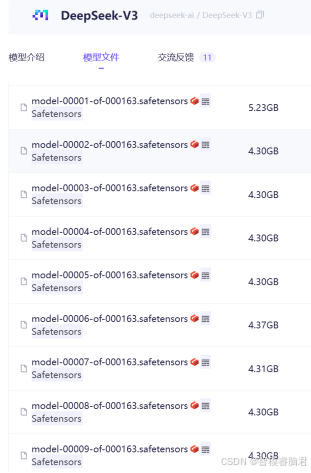
这两款大小几乎一样,一共切了163块,每块4.3G,还有个别一些事5-6G,总大小超过163*4.3=700.9G.要是企业级应用可以试试,自己玩的话,光下载至少3天,关键硬盘也没那么大,推理的话GPU要求也极高,综上所述,还是先放弃这两款。幸运的是,经过查找发现了一个小一点的,和他们都有血缘关系的deepseek,蒸馏过的1.5B参数的模型。
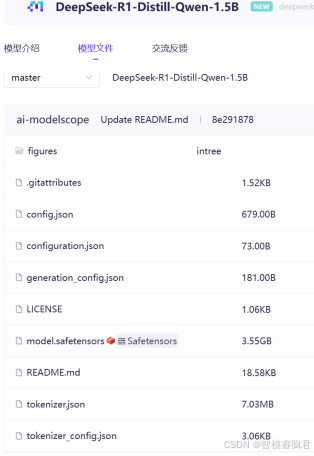
这个就很小了,只有3G多了,后面就拿这款测试了。
2,VLM(图像识别)
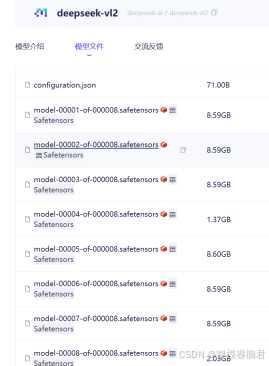
哥哥70G左右,弟弟30G,那就用弟弟。

3,T2I(文生图)
这是一款近期最近发布的,经过多家测评机构,一致认为在文生图的表现已经超过DALL·E 3,而且模型也不大.Janus-Pro-1B大概4G多点.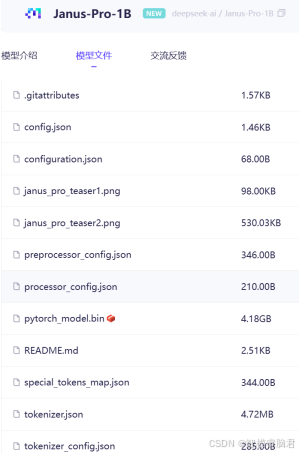
3. 下模
1, LLM
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B')
2, VLM
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/deepseek-vl2-small')
3, T2I
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/Janus-Pro-1B')
魔塔社区的网站给了下载地址,直接复制到代码即可。
然后安装modelscope包。
唯一注意一点就是包下哪去了。
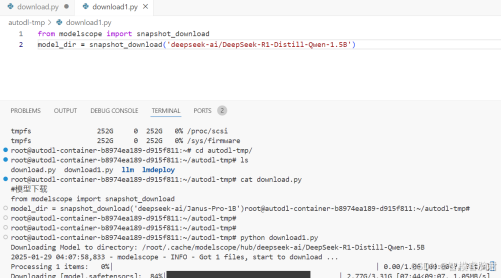
主要第一个模型没给参数,一般默认是根目录下.cache文件的modelscope下,如果是从huggingface下的,默认也是在这个目录,同样也会建一个huggingface目录,模型都保存在这里面.
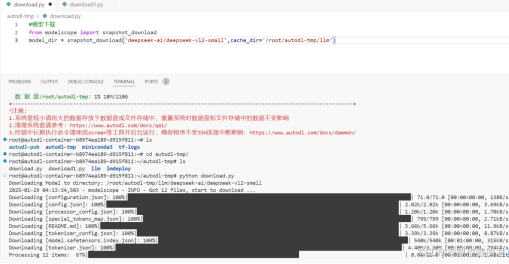
如果不想考来考去,也可以指定下载目录,就是参数中加一个cache_dir,后面跟路径即可.2个模型分别用默认和指定下载,然后看看下哪了.这时候可以去干别的,可以开2个窗口同时下,过会再来看.
三、推理
1. 代码
只需要把模型路径改位自己的即可,问题可以随便写自己感兴趣的话题.这样,就可以不需要下任何app,不需要上网,本地就可以玩转大模型,也可以部署到自己服务器上.
下面举例演示过程.
1,文本
from lmdeploy import pipeline
pipe = pipeline('/root/autodl-tmp/llm/modelscope/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B')
response = pipe(['Hi, pls intro yourself', 'Shanghai is'])
print(response)
也可以使用调用OpenAI格式的prompts形式调用,关于相关更详细的调用,可以参考
https://blog.youkuaiyun.com/weixin_41688410/article/details/145378798
from lmdeploy import pipeline, GenerationConfig, TurbomindEngineConfig
backend_config = TurbomindEngineConfig(tp=2)
gen_config = GenerationConfig(top_p=0.8,
top_k=40,
temperature=0.8,
max_new_tokens=1024)
pipe = pipeline('internlm/internlm2_5-7b-chat',backend_config=backend_config)
prompts = [[{
'role': 'user',
'content': 'Hi, pls intro yourself'}],
[{
'role': 'user', 'content': 'Shanghai is'}]]
response = pipe(prompts, gen_config=gen_config)
print(response)
2,视觉
把模型路径,和需要加载的图片换成自己的即可。
from lmdeploy import pipeline
from lmdeploy.vl import load_image
pipe = pipeline('/root/autodl-tmp/llm/deepseek-ai/deepseek-vl2-small')
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
response = pipe(('describe this image', image))
print(response)
2. 输出
下面是输出,可以看到,我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1882
1882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









