







 本文介绍了位图和布隆过滤器在处理大数据时的应用。位图用于在有限内存下查找出现一次的整数、计算交集等,通过映射和位操作提高效率。布隆过滤器则是一种概率型数据结构,用于高效插入和查询,适用于判断元素是否存在,但可能存在误判。文中通过实例解释了这两种数据结构的工作原理和使用场景。
本文介绍了位图和布隆过滤器在处理大数据时的应用。位图用于在有限内存下查找出现一次的整数、计算交集等,通过映射和位操作提高效率。布隆过滤器则是一种概率型数据结构,用于高效插入和查询,适用于判断元素是否存在,但可能存在误判。文中通过实例解释了这两种数据结构的工作原理和使用场景。
一、位图
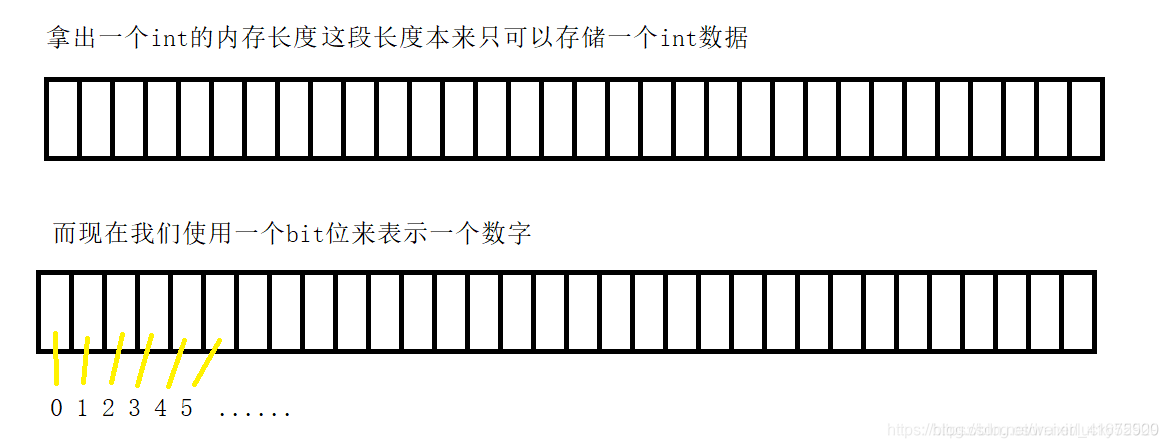
1.位图原理
4个字节本来只能存储一个int,而现在使用位图我们就存了(映射)32个数字,也就是存储的倍数为原来的32倍。
2.位图应用
- 给定100亿个整数,设计算法找到只出现一次的整数
将100亿个数分拆成1000份文件,再将每份文件里使用位图,并用两位bit表示数字出现的次数,00存出现0次的数,01存放出现1次的数,10存放出现多次的数,11舍弃,再将1000份中出现一次的数全部合并到一个文件里存放即可。- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集
- 使用hash函数将第一个文件的所有整数映射到1000个文件中,每个文件有1000万个整数,大约40M内存, 内存可以放下,把1000个文件记为a1,a2,a3……a1000,用同样的hash函数映射第二个文件到1000个文件中,这1000个文件记为b1,b2,b3……b1000,由于使用的是相同的hash函数,所以两个文件中一样的数字会被分配到文件下标一致的文件中,分别对a1和b1求交集,a2和b2求交集,ai和bi求交集,最后将结果汇总,即为两个文件的交集
- 桶分+组内bitmap。如果这里的整数是32bit的话,直接使用bitmap的方法就能实现了。所有整数共2^32 种可能,每个数用2bit来表示,“00”表示两个文件均没出现,“10”表示文件1出现过,“01”表示文件2出现过,“11”表示两个文件均出现过,共需(2^32)*2/8=1GB内存,遍历两个文件中的所有整数,然后寻找bitmap中“11”对应的整数即是两个文件的交集。
- 1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
- 将100亿个整数分成100份,这样就只需要400M的内存,将每个数加载到哈希表中,就可以知道那个数据只出现了两次或者一次。
- 100亿个整数其实也都在是42亿9千万数字之中,利用位图的扩展,用2个位表示数字出现的次数,00表示没有出现过,01表示出现过一次,10表示出现过多次,这样内存需要1G。
- 给两个文件,分别有100亿个URL,我们只有1G内存,如何找到两个文件交集?
分别给出精确算法和近似算法。
- 精确算法:Hash分桶法 •
将两个文件中的query hash到N个小文件中,并标明query的来源 • 在各个小文件中找到重合的query •
将找到的重合query汇总- 近似算法:BloomFilter
- 给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
将100G文件分成1000份,将每个IP地址哈希映射到相应文件中,在每个文件中分别求出最高频的IP,然后合并在进行比较,找出次数最多的IP地址。
这里的位图只是可以映射数字类型的数据,变成字符串以及其他文件可以用布隆过滤器
二、布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
参考
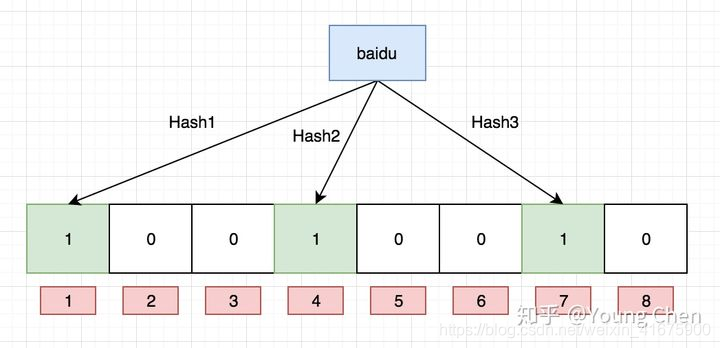
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
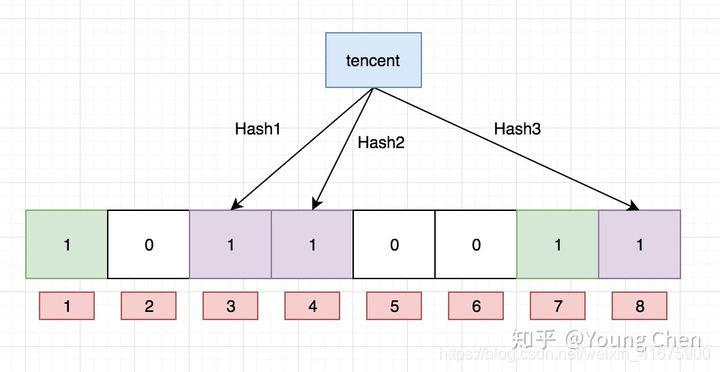
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
- 值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
- 这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
算法:
- 首先需要k个hash函数,每个函数可以把key散列成为1个整数
- 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0
- 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
- 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
优点:不需要存储key,节省空间
缺点:
- 算法判断key在集合中时,有一定的概率key其实不在集合中

















 1962
1962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









